







CNN
网络基础结构
神经网络-全连接层(1)
神经网络-全连接层(2)
神经网络-全连接层(3)
本系列之前关于神经网络的文章!

卷积层(1)
前面聊了3期全连接层,下面先扔下它,看看卷积神经网络的另外一个重量级组成部分——卷积层。
关于卷积层的具体计算方式在这里就不多说了,和全连接层类似,由线性部分和非线性部分组成,一会儿直接看代码就好。关于卷积层的计算方法,现在一般来说大家的实现方式都是用“相关”这个操作来进行的,为什么呢?当然是为了计算方便,减少一次把卷积核转一圈的计算。
以下是“卷积层”操作的基本代码,我们后面会做进一步地“升级”的:
import numpy as np
import matplotlib.pyplot as plt
def conv2(X, k):
x_row, x_col = X.shape
k_row, k_col = k.shape
ret_row, ret_col = x_row - k_row + 1, x_col - k_col + 1
ret = np.empty((ret_row, ret_col))
for y in range(ret_row):
for x in range(ret_col):
sub = X[y : y + k_row, x : x + k_col]
ret[y,x] = np.sum(sub * k)
return ret
class ConvLayer:
def __init__(self, in_channel, out_channel, kernel_size):
self.w = np.random.randn(in_channel, out_channel, kernel_size, kernel_size)
self.b = np.zeros((out_channel))
def _relu(self, x):
x[x < 0] = 0
return x
def forward(self, in_data):
# assume the first index is channel index
in_channel, in_row, in_col = in_data.shape
out_channel, kernel_row, kernel_col = self.w.shape[1], self.w.shape[2], self.w.shape[3]
self.top_val = np.zeros((out_channel, in_row - kernel_row + 1, in_col - kernel_col + 1))
for j in range(out_channel):
for i in range(in_channel):
self.top_val[j] += conv2(in_data[i], self.w[i, j])
self.top_val[j] += self.b[j]
self.top_val[j] = self._relu(self.topval[j])
return self.top_val
到这里卷积层就介绍完了,谢谢……
卷积层内心OS:玩儿去,怎么可以戏份这么少……
其实在卷积神经网络这个模型大火之前,卷积这个概念早已深入许多图像处理的小伙伴的内心了。在图像处理中,我们有大批图像滤波算法,其中很多都是像卷积层这样的线性卷积核。为了更清楚地介绍这些核,我们拿一张OCR的训练数据做例子(特别说明,本文字来自wikipedia,侵权删图):
import cv2
mat = cv2.imread('conv1.png',0)
row,col = mat.shape
in_data = mat.reshape(1,row,col)
in_data = in_data.astype(np.float) / 255
plt.imshow(in_data[0], cmap='Greys_r')
这个字显示出来是这个样子:

首先是mean kernel,也就是均值滤波:
meanConv = ConvLayer(1,1,5)
meanConv.w[0,0] = np.ones((5,5)) / (5 * 5)
mean_out = meanConv.forward(in_data)
plt.imshow(mean_out[0], cmap='Greys_r')
结果如下所示:
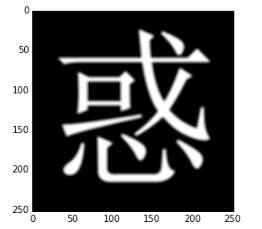
均值滤波在图像处理中可以起到对模糊图像的作用,当然由于卷积核比较小,所以效果不是很明显。
然后是梯度计算,请上Sobel kernel,我们定义一个计算纵向梯度的核,如果一个像素点的纵向梯度非常大,那么这个点的结果会非常大:
sobelConv = ConvLayer(1,1,3)
sobelConv.w[0,0] = np.array([[-1,-2,-1],[0,0,0],[1,2,1]])
sobel_out = sobelConv.forward(in_data)
plt.imshow(sobel_out[0], cmap='Greys_r')
图像结果如下所示:
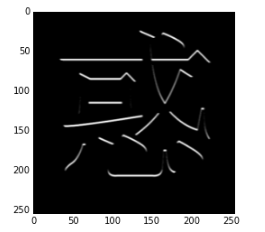
从结果来看,文字中横向比划的上端被保留了下来。
最后来一张Gabor filter的效果,现在的一些论文里面都宣称自己的模型能够学出Gabor filter的参数来(Gabor filter代码来自wikipedia):
def gabor_fn(sigma, theta, Lambda, psi, gamma):
sigma_x = sigma
sigma_y = float(sigma) / gamma
(y, x) = np.meshgrid(np.arange(-1,2), np.arange(-1,2))
# Rotation
x_theta = x * np.cos(theta) + y * np.sin(theta)
y_theta = -x * np.sin(theta) + y * np.cos(theta)
gb = np.exp(-.5 * (x_theta ** 2 / sigma_x ** 2 + y_theta ** 2 / sigma_y ** 2)) * np.cos(2 * np.pi / Lambda * x_theta + psi)
return gb
print gabor_fn(2, 0, 0.3, 0, 2)
gaborConv = ConvLayer(1,1,3)
gaborConv.w[0,0] = gabor_fn(2, 0, 0.3, 1, 2)
gabor_out = gaborConv.forward(in_data)
plt.imshow(gabor_out[0], cmap='Greys_r')
[[-0.26763071 -0.44124845 -0.26763071]
[ 0.60653066 1. 0.60653066]
[-0.26763071 -0.44124845 -0.26763071]]
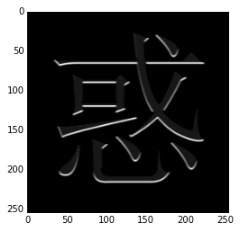
从结果可以看出,Gabor filter同样可以做到边缘提取的作用,这和它本身的功能是相符的。
好了,以上三种处理完成之后,我们可以看出,不同的滤波核确实能起到不同的效果。实际上用于图像滤波的卷积核还有很多。
下面要试图做一些讲道理的事情,也就是说明:
为什么要发明卷积层这种神经层?能不能用全连接层代替卷积层?
很显然,用全连接层代替卷积层是完全没有问题的,但是这样做的代价实在太大了。原始图像的维度相对而言比较大,如果采用全连接的话参数将会有爆炸式的增长,参数的数量可能对于现在的电脑来说是一个灾难。试想一下对于MNist的数据,如果第一层是全连接层,即使把1*28*28数据映射到1*1024这样的输出上,其中的参数已经达到800万。而曾经的经典模型Lenet呢?
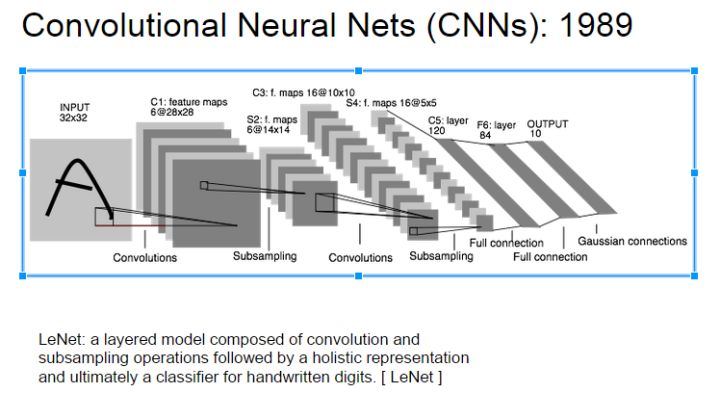
从上面的图可以看出(此处):
第一层卷积的参数数量为:1*6*(5*5+1)=156,却可以得到6*28*28的输出。
两者的参数数量差距几万倍,而实际上两者效果绝对不会有如此大的差距。
既然如此,参数数量如此少的卷积层为什么可以有用?识别这样的问题总体来说是一种比较宏观的问题。像MNist这样的问题,每张图片上有784个像素,理论上可以有
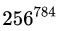
种组合,而实际的类别只有10种,基本上可以断定提供的信息是远远多于满足搜索需求的数量的。那么多出来的像素信息是以什么样的形式展现呢?在图像处理上,有一个词叫“局部相关性”就是指这样的问题。
我们是如何识别出一个数字的呢?当然是因为这个数字不同于别的数字的特点,对于像MNist这样的数据,特点自然来自于明暗交界的地方。一片黑的区域不会告诉我们任何有用的信息,同样地,一片白的区域也不会告诉我们任何有用的信息。同样,数字的笔画粗细对我们的识别也没有太大的作用。这些都是我们识别过程中会遇到的问题,而其中临近像素之间有规律地出现相似的状态就是局部相关性。
那么如何消除这些局部相关性呢,使我们的特征变得少而精呢?卷积就是一种很好地方法。它只考虑附近一块区域的内容,分析这一小片区域的特点,这样针对小区域的算法可以很容易地分析出区域内的内容是否相似。如果再加上Pooling层(可以理解为汇集,聚集的意思,后面不做翻译),从附近的卷积结果中再采样选择一些高价值的合成信息,丢弃一些重复低质量的合成信息,就可以做到对特征信息的进一步处理过滤,让特征向少而精的方向前进。

卷积的另一种解释
熟悉图像处理的童鞋一定都知道传说中的卷积定理,这个定理涉及到图像处理的一大黑科技——傅立叶变换。
关于傅立叶的高质量科普文章已经很多,这里就不多说了。套用之前看过的一个有赞的解释:如果把我们看到的图像比作一道做好的菜,那么傅立叶变换就是告诉我们这道菜具体的配料以及各种配料的用量。这个方法的神奇之处在于不管这道是如何做的(按类别码放还是大乱炖),它都能将配料清晰分出来。在图像处理中,这个配料被成为频率。其中有些信息被称作低频信息,有些被成为高频信息。
低频信息一般被我们是看作是整幅图像的基础,有点像一道菜中的主料。如果说这道菜是番茄炒蛋,那低频信息可以看作是番茄和蛋。高频信息一般是指那些变动比较大的,表达图像特点的信息,有点像一道菜的配料或者调料。对于番茄炒蛋,像是菜中调料和点缀的材料。
回到卷积中,卷积定理中说,两个矩阵的卷积的结果,等于两个矩阵在经过傅立叶变换后,进行元素级别的乘法(element-wise multiplication),然后再对结果进行反向傅立叶处理。如果我们用FFT表示傅立叶变换,IFFT表示反向傅立叶变换,那么下面两个过程结果是相同的(考虑到浮点数近似,可以认为相近就是相同):
A = np.array()
B = np.array() # matrix
# method1
C = conv2(A,B)
#method2
FFT_A = FFT(A)
FFT_B = FFT(B)
C = IFFT(FFT_A * FFT_B)
真实的代码不会像上面这样简单,但是大体来说结构也是相同的。看上去第二种方法比第一种方法啰嗦了不少,那么它的优势在哪里?
那我们就来看看上面提到的一些kernel在经过傅立叶变换后的样子:
首先是mean kernel:

然后是Sobel kernel:

最后是Gabor kernel:

我们前面说过,傅立叶变换可以帮助分析出高低频信息。在上面的图像中,(经过fft_shift的)图像的正中心是低频信息,越靠近边缘频率越高。由于最终要进行元素级的乘法,如果kernel在某个频率的数据比较低,经过乘法后输入数据在这个频率的数据也会变小。
如果我们把上面的图片想象成中心为原点的直角坐标系图,所以我们可以看出:
mean kernel会把中心附近和坐标轴附近信息进行保留;
Sobel kernel会保留y轴上下的信息,丢弃中间的信息和x轴两边的信息;
Gabor kernel和Sobel kernel类似,但是保留的内容会更少些,更倾向于保留远离中心的像素。
所以从这个角度来分析结果,sobel kernel和gabor kernel更倾向于保留高频信息而弱化低频信息,而mean kernel则是弱化高频信息而保留低频信息。所以mean kernel和另外两个kernel的作用不同。
另外,对于一些文章中提到利用可视化的方法发现了自己的参数像gabor filter,也说明了它的卷积核作用是保留高频牺牲低频。
那么从这个角度分析,卷积层意义在哪里?如果我们任务是给我们一盘番茄炒蛋,问我们这盘菜是哪位师傅做的(记得小时候在饭店吃饭的时候,菜盘边上经常会有一张小纸条写着“XX号厨师为您服务”)。那么盘子里的数量众多的番茄和鸡蛋不一定能帮助我们找到厨师,而其中佐料的分量多少更有助于我们找出厨师的做菜风格。当然这里我们假设厨师有自己的风格,且正常发挥没有失误了。而这个思路也是卷积层采取的一种策略。
关于傅立叶变换以及频域信息分析显然没有这么简单,更多的细节还需要更多的分析,这里只是抛砖作个引子。
下一回将说说卷积层具体求解的问题。
雷课:
让教育更有质量,
让教育更有想象!

















 2265
2265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









