






作者:黄天元,复旦大学博士在读,热爱数据科学与开源工具(R),致力于利用数据科学迅速积累行业经验优势和科学知识发现,涉猎内容包括但不限于信息计量、机器学习、数据可视化、应用统计建模、知识图谱等,著有《R语言数据高效处理指南》(《R语言数据高效处理指南》(黄天元)【摘要 书评 试读】- 京东图书,《R语言数据高效处理指南》(黄天元)【简介_书评_在线阅读】 - 当当图书)。知乎专栏:R语言数据挖掘。邮箱:huang.tian-yuan@qq.com.欢迎合作交流。
数据存在缺失值的问题在实践工作中屡见不鲜,正确地观察、分析并对缺失值进行合理的处理,是保证数据分析结果有效性的重要前提。一般而言,缺失值分析流程如下:
1、观察哪里缺失(行、列)、缺失多少,是否存在时间序列或空间邻接的连续确实
2、分析缺失原因,数据是如何缺失(随机缺失/非随机缺失)的
3、根据原因,给出处理方案(替换、删除、插补)
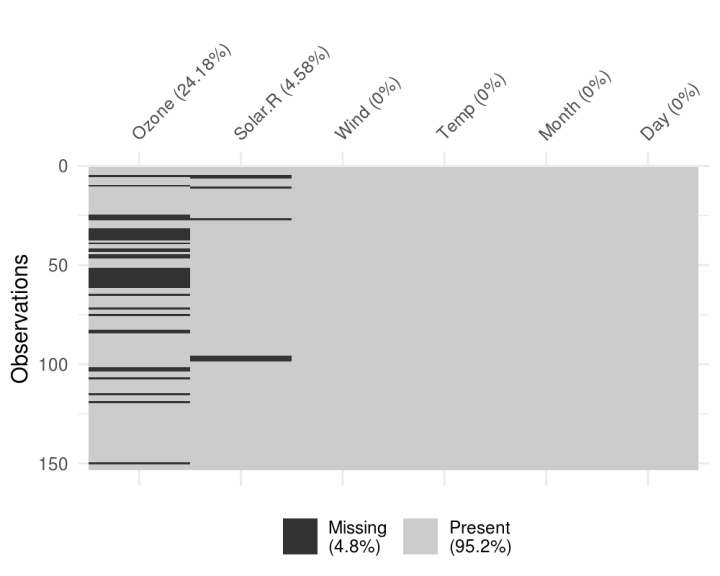
一直以来,R语言社区就对缺失值很有办法。而在R语言的新时代,简洁之风(tidy data)更是为这个过程带来极大的便利。这里只推荐一个R包——naniar。
链接如下:
CRAN - Package naniarcran.r-project.org https://github.com/njtierney/naniargithub.com Data Structures, Summaries, and Visualisations for Missing Datananiar.njtierney.com
从表格统计到可视化,一应俱全,在开发版本中更是有很多新的特性。这个包可以对缺失值进行观察、分析、替换、插补,而且未来还会更加优秀,是以mark一下,以备不时之需。















 763
763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









