






 本文介绍了一种针对光隔离元器件的划痕麻点检测程序,该程序能够检测体积微小的元件表面缺陷,如红圈标识的部分。
本文介绍了一种针对光隔离元器件的划痕麻点检测程序,该程序能够检测体积微小的元件表面缺陷,如红圈标识的部分。
 文/杨操,慧眼自动化科技(广州)有限公司
在芯片制造业中绝大部分生产线已实现自动化,但芯片中的光隔离元件因本身体积小、精密度高,对其外观检测一直是行业痛点,仍需大量人工检测。针对上述问题,慧眼自动化开发了基于深度学习的光隔离元件外观检测解决方案。
客户要求
我们的客户(暂称A公司)是一家致力于光电材料、高精密光学元件、光纤器件和光网络功能模块等光电子产品的研发、生产和销售的公司。在“用户至上、质量第一”的理念下,A公司不断推出满足用户需求的新产品,并持续改进制造工艺,力图在实现高品质产品的同时,兼顾降本增效。
在A公司的光隔离元件生产线上,目前采用的产品外观检测方法依然是人工通过显微镜目视检测。需要检测的缺陷包括划痕、脏污、破损、尺寸异常等。由于光隔产品的尺寸基本在0.3~0.7mm之间,缺陷尺寸在0.04mm左右,并且产品易碎,因此目前的显微镜目视检测方法存在以下弊端:
(1)人工用镊子夹取产品,速度慢,因此检测效率较低;
(2)操作员易疲劳,不利于产品质量的严格控制;
(3)产品易碎,容易造成二次损伤;
(4)操作员人工目视,检测标准难以控制;
(5)人工成本巨大,平均一颗产品的检测成本高达1元。
文/杨操,慧眼自动化科技(广州)有限公司
在芯片制造业中绝大部分生产线已实现自动化,但芯片中的光隔离元件因本身体积小、精密度高,对其外观检测一直是行业痛点,仍需大量人工检测。针对上述问题,慧眼自动化开发了基于深度学习的光隔离元件外观检测解决方案。
客户要求
我们的客户(暂称A公司)是一家致力于光电材料、高精密光学元件、光纤器件和光网络功能模块等光电子产品的研发、生产和销售的公司。在“用户至上、质量第一”的理念下,A公司不断推出满足用户需求的新产品,并持续改进制造工艺,力图在实现高品质产品的同时,兼顾降本增效。
在A公司的光隔离元件生产线上,目前采用的产品外观检测方法依然是人工通过显微镜目视检测。需要检测的缺陷包括划痕、脏污、破损、尺寸异常等。由于光隔产品的尺寸基本在0.3~0.7mm之间,缺陷尺寸在0.04mm左右,并且产品易碎,因此目前的显微镜目视检测方法存在以下弊端:
(1)人工用镊子夹取产品,速度慢,因此检测效率较低;
(2)操作员易疲劳,不利于产品质量的严格控制;
(3)产品易碎,容易造成二次损伤;
(4)操作员人工目视,检测标准难以控制;
(5)人工成本巨大,平均一颗产品的检测成本高达1元。

图1:被检测的光隔离元器件(红圈标识),体积非常小
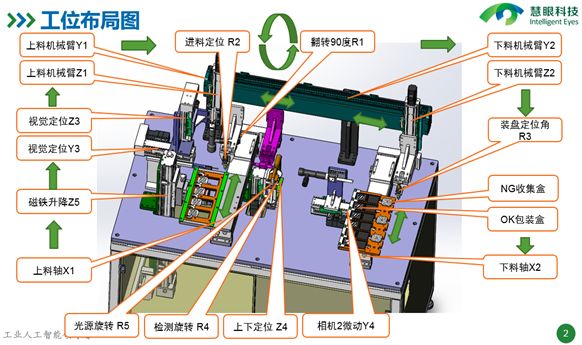
 设备结构及工作流程
设备结构及工作流程
 深度学习的应用
在机器视觉应用中,外观检测一直是行业痛点。外观缺陷中的划痕、脏污、形态不一、大小不同、深浅和各种姿态都不同,很难用传统的视觉检测算法稳定检测。但是随着深度学习技术的发展,采用深度学习模式的外观检测程式,成为了外观检测的新方法。在A公司的这个案例中,我们也遇到了传统视觉算法难以解决的外观检测问题,我们的解决方案是采用深度学习搭配传统定位算法。
深度学习训练模式:
深度学习是一类模式分析方法的统称,就具体研究内容而言,主要涉及三类方法:
(1)基于卷积运算的神经网络系统,即卷积神经网络(CNN)。
(2)基于多层神经元的自编码神经网络,包括自编码(Auto encoder)以及近年来受到广泛关注的稀疏编码(Sparse Coding)。
(3)以多层自编码神经网络的方式进行预训练,进而结合鉴别信息进一步优化神经网络权值的深度置信网络(DBN)。
通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示后,用“简单模型”即可完成复杂的分类等学习任务。由此可将深度学习理解为进行“特征学习”(feature learning)或“表示学习”(representation learning)。
以往在机器学习用于现实任务时,描述样本的特征通常需要由人类专家来设计,这称为“特征工程”(feature engineering)。众所周知,特征的好坏对泛化性能有至关重要的影响,人类专家设计出好特征也并非易事;特征学习(表征学习)则通过机器学习技术自身来产生好特征,这使机器学习向“全自动数据分析”又前进了一步。
近年来,研究人员也逐渐将这几类方法结合起来,如对原本是以“有监督学习为基础的”卷积神经网络,结合自编码神经网络进行无监督的预训练,进而利用鉴别信息微调网络参数形成的卷积深度置信网络。与传统的学习方法相比,深度学习方法预设了更多的模型参数,因此模型训练难度更大,根据统计学习的一般规律知道,模型参数越多,需要参与训练的数据量也越大。
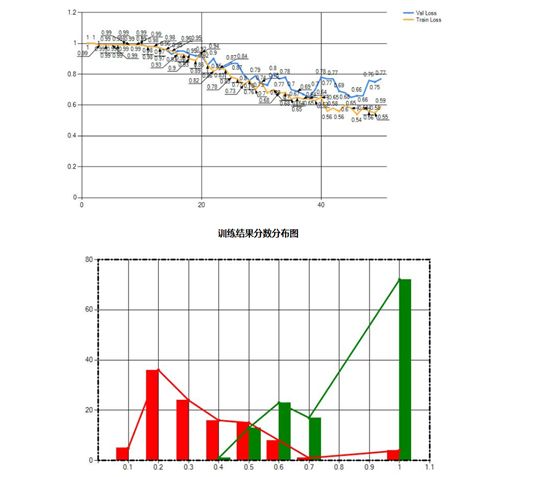
20世纪八九十年代,由于计算机计算能力有限和相关技术的限制,可用于分析的数据量太小,深度学习在模式分析中并没有表现出优异的识别性能。自2006年Hinton等提出快速计算受限玻耳兹曼机(RBM)网络权值及偏差的CD-K算法后,RBM就成了增加神经网络深度的有力工具,导致后面使用广泛的DBN(由 Hinton等开发并已被微软等公司用于语音识别中)等深度网络的出现。与此同时,稀疏编码等由于能自动从数据中提取特征,也被应用于深度学习中。基于局部数据区域的卷积神经网络方法今年来也被大量研究。本案例中的具体实现方式如下:
(1)收集大量缺陷样品图像和OK样品图像
(2)人工标注缺陷位置、范围
(3)算法自动根据标注内容自动学习
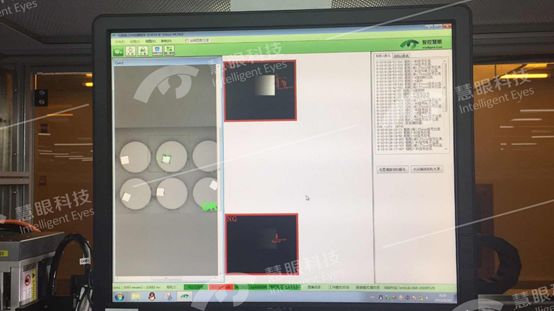
(4)载入训练好的检测程式,嵌入传统视觉程序中
深度学习的应用
在机器视觉应用中,外观检测一直是行业痛点。外观缺陷中的划痕、脏污、形态不一、大小不同、深浅和各种姿态都不同,很难用传统的视觉检测算法稳定检测。但是随着深度学习技术的发展,采用深度学习模式的外观检测程式,成为了外观检测的新方法。在A公司的这个案例中,我们也遇到了传统视觉算法难以解决的外观检测问题,我们的解决方案是采用深度学习搭配传统定位算法。
深度学习训练模式:
深度学习是一类模式分析方法的统称,就具体研究内容而言,主要涉及三类方法:
(1)基于卷积运算的神经网络系统,即卷积神经网络(CNN)。
(2)基于多层神经元的自编码神经网络,包括自编码(Auto encoder)以及近年来受到广泛关注的稀疏编码(Sparse Coding)。
(3)以多层自编码神经网络的方式进行预训练,进而结合鉴别信息进一步优化神经网络权值的深度置信网络(DBN)。
通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示后,用“简单模型”即可完成复杂的分类等学习任务。由此可将深度学习理解为进行“特征学习”(feature learning)或“表示学习”(representation learning)。
以往在机器学习用于现实任务时,描述样本的特征通常需要由人类专家来设计,这称为“特征工程”(feature engineering)。众所周知,特征的好坏对泛化性能有至关重要的影响,人类专家设计出好特征也并非易事;特征学习(表征学习)则通过机器学习技术自身来产生好特征,这使机器学习向“全自动数据分析”又前进了一步。
近年来,研究人员也逐渐将这几类方法结合起来,如对原本是以“有监督学习为基础的”卷积神经网络,结合自编码神经网络进行无监督的预训练,进而利用鉴别信息微调网络参数形成的卷积深度置信网络。与传统的学习方法相比,深度学习方法预设了更多的模型参数,因此模型训练难度更大,根据统计学习的一般规律知道,模型参数越多,需要参与训练的数据量也越大。
20世纪八九十年代,由于计算机计算能力有限和相关技术的限制,可用于分析的数据量太小,深度学习在模式分析中并没有表现出优异的识别性能。自2006年Hinton等提出快速计算受限玻耳兹曼机(RBM)网络权值及偏差的CD-K算法后,RBM就成了增加神经网络深度的有力工具,导致后面使用广泛的DBN(由 Hinton等开发并已被微软等公司用于语音识别中)等深度网络的出现。与此同时,稀疏编码等由于能自动从数据中提取特征,也被应用于深度学习中。基于局部数据区域的卷积神经网络方法今年来也被大量研究。本案例中的具体实现方式如下:
(1)收集大量缺陷样品图像和OK样品图像
(2)人工标注缺陷位置、范围
(3)算法自动根据标注内容自动学习
(4)载入训练好的检测程式,嵌入传统视觉程序中
End
近期活动 视觉系统设计用户单位,免费听会

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









