







一、算法概述
KNN也称为K近邻或最近邻(nearest neighbor),从字面来理解就是根据测试样本相对最近(属性相对最近)的K个训练样本的类别来决定该测试样本的类别(少数服从多数)。KNN是一种惰性学习方法(不需要训练模型),主要处理分类问题。有惰性学习方法,那么也有积极学习方法,前面讲到的决策树是积极学习方法。那怎么判断属性相对最近呢?其实KNN算法在寻找相对最近样本时使用的是计算样本属性的距离。然后根据计算出来的距离取距离最近的K个训练样本,再根据这K个样本的类别的数量来决定该测试样本的类别。这里起到决定性作用的是样本个数K值,具体影响看如下图:
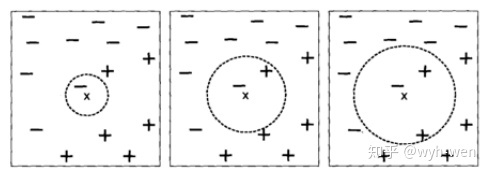
左图是K=1,则测试样本类别为负;中间图K=2,则测试样本类别没法判定;右图K=3,则测试样本类别是正。根据这三个图,我们可以看出,随着K值的变化,测试样本的类别会发生变化。因此可以看出K值的重要性。如果K值太小,则最近邻分类器容易受到由于训练数据中的噪声而产生的过分拟合的影响;如果K值太大,最近邻分类器可能会误分类测试样本,因为最近邻的K个样本中会包含距离较远的样本。
二、算法伪代码
数据集分为训练集和测试集,x和y分别代表特征向量和目标变量,一个训练样本为(x,y),训练样本空间为(x,y)∈D,测试样本为
KNN最近邻算法伪代码:
1.设置参数,K是最近邻样本个数,D是训练集;
2.for 每个测试样本
3.计算z和每个训练样本(x,y)∈D的距离
4.选择离z最近的K个训练样本的集合
6.end for
其中第5步式子中的v是类标号,而 I( )是指示函数,即若
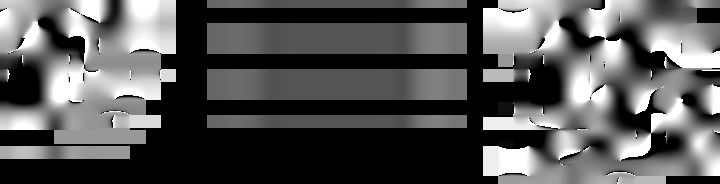
,则返回1,否则返回0。但由于此算法对K值很敏感,为了降低K值的影响,我们可以给不同距离的训练样本加上权重值,权重值设为距离平方的倒数,即距离越远的,影响越小。

最终测试样本类标号公式如下:
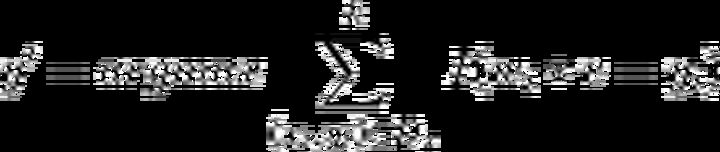
三、模型完善
关于K值取值大小是该算法中重点问题。一般情况,K值选取3、5、7是比较常见的,但具体选择多少才合适,模型可靠性多大,还需要具体方法来辅助决定。
1.学习曲线
学习曲线在机器学习中非常常见,一般用于非模型判别结果参数的展示和选取,例如KNN模型中K值的选取,可以通过绘制一条横轴为1-10、纵轴为选取该K值时模型的准确率,用折线图展示。
2.交叉验证
学习曲线的本质是基于一个既定的训练集和测试集进行的,但实际上,测试集和训练集的划分也会影响模型的准确率,而就KNN而言模型的准确率在一定程度上又会影响K值的选取,最终影响模型的建立。为了消除该影响,我们可以利用交叉验证来判别模型判别效力。交叉验证是首先将数据集划分为n等分,然后选取其中一份作为测试集,剩下的n-1份作为训练集。首先将训练集训练模型,训练完成后将测试集投入测试,得到一个模型评估指标,接着再换另外一份测试集,继续训练测试并评估。最后得到n个评估指标,取平均值,将其记为最终的模型评估指标。














 1155
1155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









