






分享2个项目
新闻热点爬取与挖掘
地址:https://github.com/Jacen789/HotNewsAnalysis
分类:Python爬虫,Python数据分析
简介:自动抓取新浪、搜狐、新华网新闻,通过对新闻内容聚类,得到新闻热点;再对热点进行分析,通过对某一热点相关词汇的聚类,得到热点问题所涉及的人物、行业或组织等。作者将该项目用于毕设,并附带了论文地址。
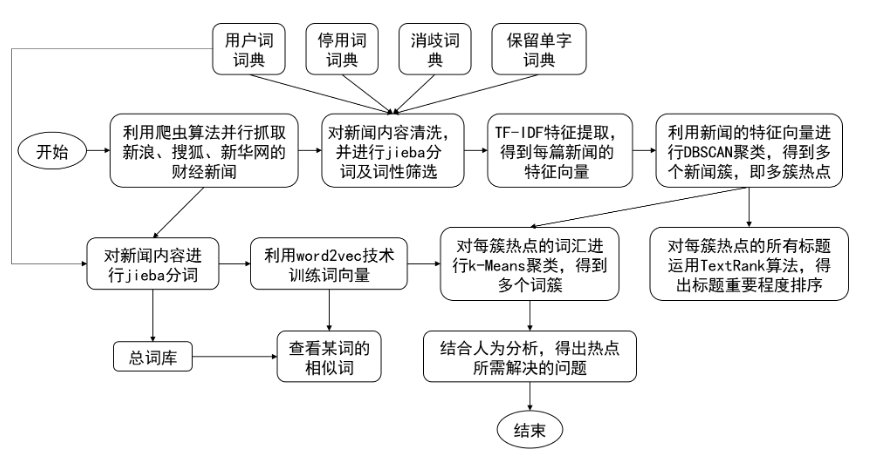
这个项目的优点是作者使用tkinter开发了一个图形化APP,上图中的所有步骤都可以通过图形化操作来完成。界面如下:
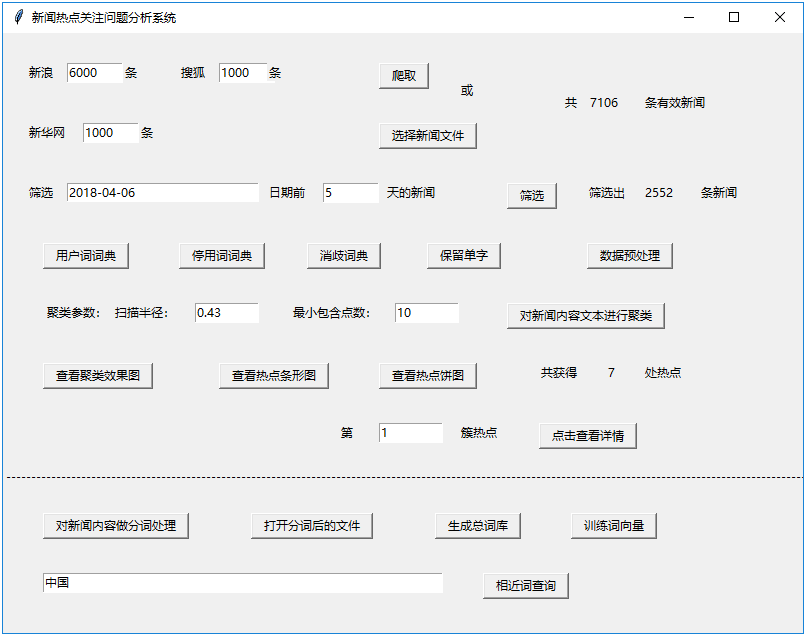
涉及的知识点:
- 多线程爬虫
- 中文分词,支持用户自定义用户词词典、停用词词典、消歧词典、保留单字词典
- TF-IDF提取特征,DBSCAN聚类算法聚类新闻热点
- 利用TextRank算法,对标题的重要程度排序,描述热点的话题
- 训练word2vec词模型,利用k-Means聚类算法计算相近词
运行项目前需要做一些设置,这个原文没有提及,这里我把准备工作简单梳理了一下。
- 项目需要运行在
Python 3环境下,我运行的Python版本是3.6.4 - 安装依赖
pip install lxml pandas matplotlib sklearn wordcloud textrank4zh gensim jieba - 创建程序运行所需要的目录,在
hot_news_analysis/data目录下分别创建models、news、results、temp_news、texts目录 - 创建用户词词典文件,在
hot_news_analysis\data\extra_dict目录下创建self_userdict.txt文件。这个文件是用户自定义的词性标注文件,jieba分词时会用到,这里我只创建了一个空文件
上面4步完成后就可以直接运行application.py文件运行程序了,另外大家在抓取数据是如果提示有效的新闻0条,那确认下是不是新闻的csv文件是不是乱码,如果是的话可以将源码中to_csv参数中的encoding='utf-8'改为encoding='utf_8_sig'。
我录制了一个操作视频,大家可以看下项目效果
获取直播流和弹幕
地址:https://github.com/wbt5/real-url
分类:Python应用
简介:该项目能够获取48个直播平台真实流媒体地址(直播源)和18个直播平台的弹幕。获取的地址经测试,均可在 PotPlayer、VLC、DPlayer(flv.js + hls.js)等播放器中播放。
包含的直播平台如下:

安装好依赖,需要获取哪个平台、哪个直播间的地址,直接运行对应的python源文件即可。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









