






1,描述统计学
描述统计学的作用是用几个关键的数字来描述数据集的整体情况,在《深入浅出统计学》中,作者指出使用简化的数字来描述数据之后的规律既有优点也缺点,优点是能让人快速的了解大量数据后面的意义,得出需要的结论,而缺点就是忽略了真实的数据源,容易得出有失准确的结论。
尽管描述统计学是把双刃剑,但是其中几个重要的数据还是需要我们掌握
2,平均数
在LIVE 中强调的平均值就是书中学到的均值,而书中一直将均值定义为平均数中的一种,在之后的课程中希望能从书本找找到答案,均值计算方法是将数据集中的数值型数据*频数相加的和处以频数和,从图中的计算过程可以看出,均值是对异常值十分敏感的一个h衡量标准,在作为一组数据集的总结量时,对于数据的对称性有着一定的要求,否则容易误导受众得出错误的结论;

3,四分位数
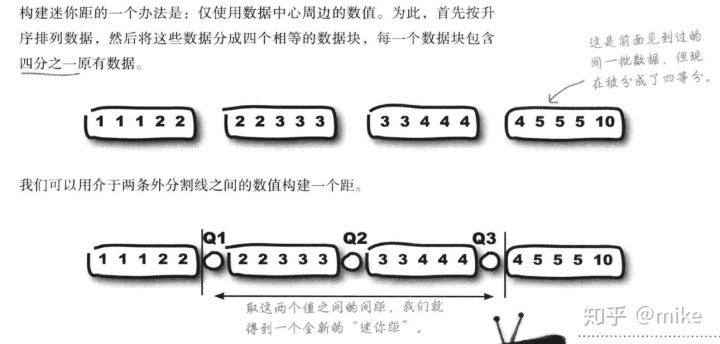
四分位数是我第一次在数据分析过程中接触的标准,四分位数的定义是将所要描述的数据集分成四等分的那个数据的值,若数据集的个数为偶数,那么上四分位数为3n/4的那个数和它下面的那个数的均值,下四分位数为n/4的bn那个数和他下面的那个数的均值;若n数据集的个数为奇数,则将n/4向上取整的那个数为下四分位数,3n/4向上取整的那个数作为上四分位数,四分位数和中位数是组成箱线图的重要部分,下图为将房间温度作为数据源画的箱线图,uy由于在作图过程中没有考虑到纵轴刻度的合理性,做出了多次修改,希望成为以后作图的经验。
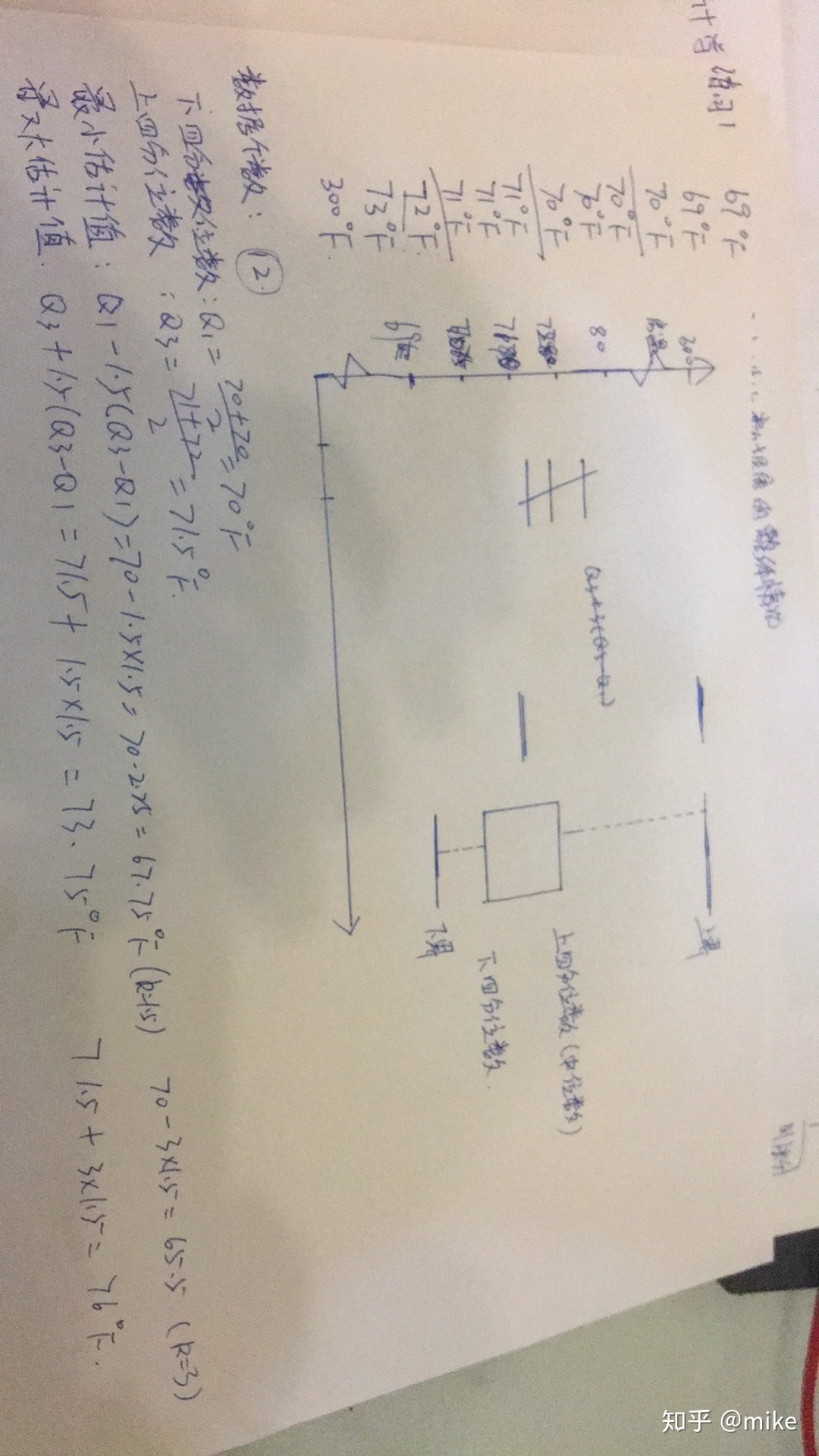
四分位数的应用:
1不同类别的数据的比较
2识别可能的异常值,对异常值进行检查处理(由于四分卫距只使用了中间50%的数据集,可以有效的排出两边的异常值对结果的干扰,live中提到了Tukey's Test 方法
最小估计值:Q1-K(Q3-Q1)
最大估计值:Q3+K(Q3-Q1)
其中K的取值:K=1.5 中度异常
K=3 极度异常
下图为求解四分位数的方法:


4 标准差
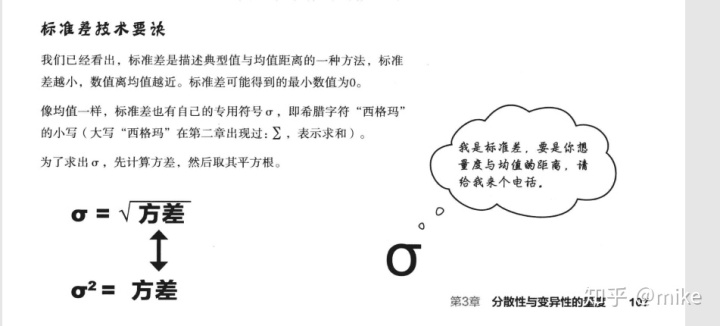
标准差是衡量数据集与均值之间的距离,而标准差的单位也是数据集的的单位,s标准差很好的表示了数据集的离散程度,其中一个案例就是
夏普比率 = (投资回报-无风险回报)/投资组合的标准差
5,标准分
标准分的意义
标准分 = 距离平均值多少个标准差(在这里用猴子老师的课件图)

对于描述统计学分析的课程总结:
一个统计学统计学量度标准可以非常准确的描述出数据集的特点以及趋势,必须根据数据集的特点来有选择的采用量度标准,否则只会得出南辕北辙的结论
基础概率:
1 什么是概率
设E是随机实验,S是实验E的样本空间。对于E的每一事件A赋予一个实数,记为P(A),称为事件A的概率
那么何为事件? 样本空间S为这次实验所有结果的结合,如抛一次硬币,结果为head,那么这次实验的样本空间就为{head},那此时事件有且只有一种,若一次实验中抛了3次硬币,可能出现的结果为{HHH,HHT,HTT,HTH,TTT,TTH,THH,THT},那么事件就可以是符合人为规定条件的集合,如规定事件A为第一次为Head的情况,那么事件A的集合为{HHH,HHT,HTT,HTH},概率为事件A集合个数/该次实验的样本空间元素总个数(在这里样本空间和事件A的集合都为理想状态,应当使用频率来描述实际中一个事件发生的频繁状态,在实验次数足够多的情况下,频率趋近于概率。
2如何计算概率
方法1:经验值
通过网上搜索已经给出的经验值,例如飞机上每个位置区域的在空难中的生存几率
方法2:数据分析
概率= 事件发生数/总数目
3概率有什么用
大数概率:如果统计数据足够大,那么事物出现的频率就能无限接近它的期望
小数概率:如果统计数据很少,那么事件就表现为各种极端情况,而这些情况都是偶然事件,跟他的期望值一点关系都没有
持续对大概率事件下注,并且同时预防那些足以毁掉你生活的风险
4 赌徒谬论
绝大多数赌徒倾向于相信之前的下注结果会对当前下注有影响,而事实上生活中有很多是独立事件,类似于掷色子,两次之间的结果并没有任何关联
而与独立事件相反的是相关事件,针对相关事件 的概率求解,则用到了决策树和i傲剑概率,在这里给出条件概率的公式:
P(A 和B)=P(A)*P(B | A)
解释:A和B发生的概率为A发生的概率乘以在A发生的前提下B发生的概率
决策数对于条件概率的求解具有具体化和简化的作用
决策树的建立有三个步骤:
第一步: 设立目标
第二步:确立所有的方案
第三步:所有方案的概率(减少主观判断的因素)
5 大数定律:
大数概率:如果统计数据足够大,那么事物出现的频率就能无限接近它的期望
6如何规避风险
1, 资本安全上:
投资你可支配资产的20%,本质上已经压上全部了
2, 在人生安全上:
买重大疾病险
课程总结:
在学习了概率之后,生活很多事都可以用更加科学和数据可视化的方法来自己做出更加理性的选择
这里是分割线----------------------------------------------------------------------------------
概率统计不分家,这边做一些 概率论的笔记
概率论相关的概念:
样本空间;一次试验中所有可能的结果组成的集合 ,称为该次试验的样本空间为S
事件:样本空间的子集,即集合中满足某些条件的元素组成的集合
事件的关系和运算即是集合的运算
等可能概型:
1样本空间只含有有限个元素
2每个基本事件发生的可能性相同
条件概率:事件A已发生的条件下事件B发生的概率
全概率公式:

划分的定义:各个事件之间没有重叠且所有集合的并集为整个样本空间
贝叶斯公式

2 随机变量极其分布律
随机变量根据取到的值的个数分为 离散型随机变量和连续型随机变量
2.1 离散型随机变量
离散型随机变量主要由随机变量X的所有可能取值以及每个取值的概率组成
2.2 三种重要的离散型随机变量
2.2.1 (0-1)分布

2.2.2伯努利实验,二项分布


2.2.3泊松分布

泊松分布逼近二项分布的定理;泊松定理

2.3 随机变量的分布函数
非离散型的随机变量,由于其可能取的值不能一一列举出来,因此无法像离散型的随机变量那样使用分布律来描述,并且在非离散型随机变量来说,我们不会关注特定某个数值的概率,而是某个区间的概率,所以我们使用分布函数来描述非离散型随机变量
2.3.1 分布函数
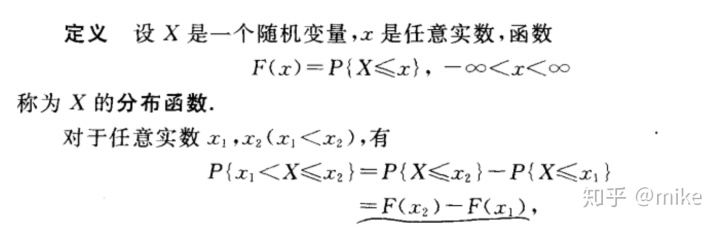
将随机变量X看成是数轴上的随机点的坐标,那么,分布函数在x处的函数值就表示X落在区间(负无穷,x]上的概率;
2.4.1 三种重要的连续型随机变量

(1) 均匀分布

(2)指数分布

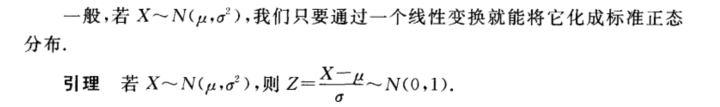
(3)正态分布(高斯分布)
4 随机变量的函数函数分布
前面讨论了基于随机变量得到分布函数,那么将随机变量中的值作为自变量的函数的分布又是如何描述呢?
如:知道直径d的随机变量,但是需要知道截面积的随机变量,那么此时就需要求关于d的函数 的分布规律了
以上是关于一个随机变量的讨论
下面讨论多个随机变量的情况
5.1 二维随机变量

边缘分布函数

相互独立的随机变量
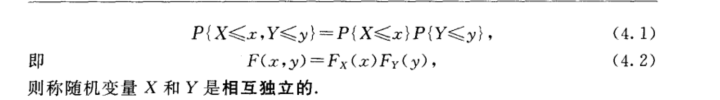
二维正态随机变量 X,Y相互独立的充要条件是参数rou = 0
两个随机变量的函数的分布
(1) Z= X+Y

第四章 随机变量的数字特征
4.1 数学期望

数学期望简称期望,又称为均值
这里记住几个分布的数学期望 泊松分布的 期望为 拉姆达
均匀分布的期望为区间边界的中点
当需要求W的数学期望,且W是另一随机变量V的函数,这时,可通过下面的定理来求W的数学期望

4.2 方差
有时候期望只能表示样本的集中趋势,不足以看出总体数据的分散程度,而方差体现了一组数据的分散程度。
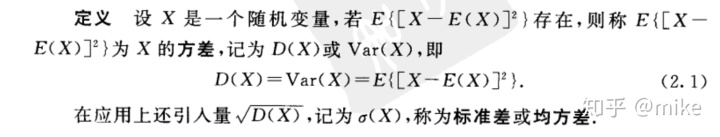
连续性随机变量的方差公式:

0-1 分布 的方差
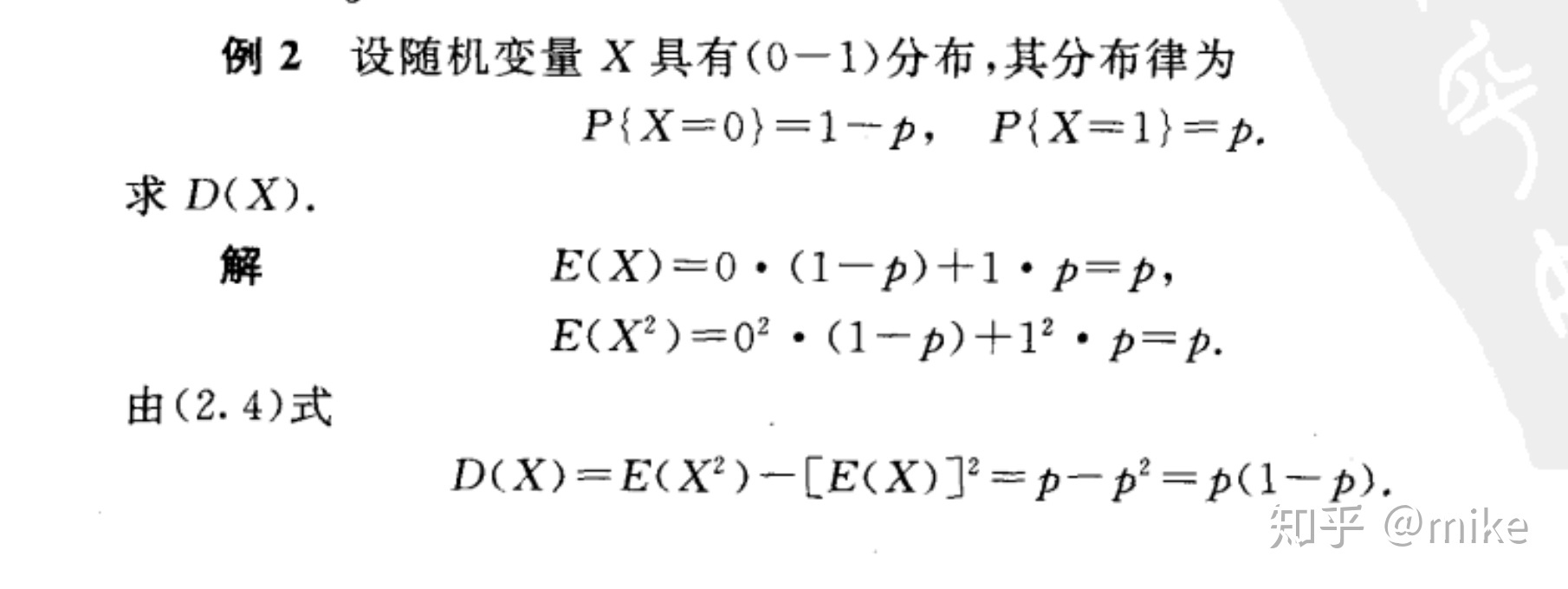
泊松分布的方差

均匀分布的方差
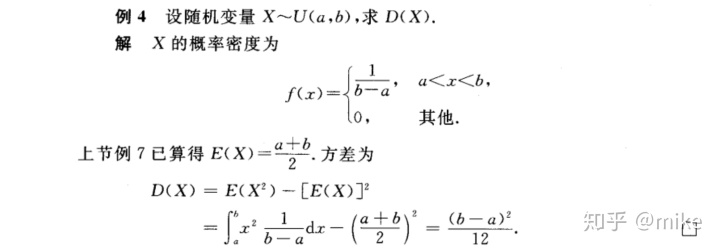
切比雪夫不等式
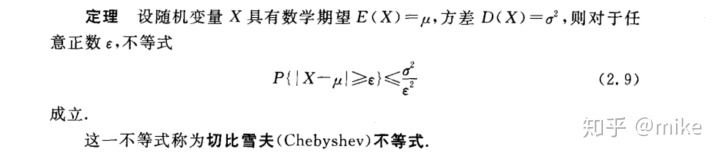
除了X和Y的数学期望和方差以外 ,还需要讨论X与Y之间相关关系的数字特征
概念1 : 协方差

协方差越大,说明两个随机变量线性不相关,但不一定相互独立;
矩,协方差矩阵

协方差矩阵

伯努利大数定律


中心极限定理
定理一:独立同分布的中心极限定理

即相互独立且服从同一分布,则这些随机变量之和的随机变量的分布函数符合标准正态分布,该定理的另一个形式是

中心极限定理
描述小部分样本的数字特征和总体样本之间的关系
从一个总体中抽取多个样本,当总体个数趋于无穷大时(N>=30)每个样本的均值组成的样本空间符合正态分布
样本的均值和总体的均值相同,而标准差为根号n分之源标准差
样本与抽样分布
几个常用的概念


往往总体的容量都非常大,不可能将所有的个体都统计到位,所以可以使用抽取部分个体的数字特征来描述总体的特征

查看样本分布状态和特征的一种有效方法就是 频率直方图和箱线图
箱线图在数据探索中往往用来侦测疑似异常值

在应用时,往往不是直接使用样本本身,而是针对不同问题构造样本的适当函数,利用这些样本的函数进行统计推断



第一种统计量的分布 ,卡方分布

从上图中可以看出,当n逐渐增大时,卡方分布的概率密度逐渐接近正态分布
卡方分布的数学期望为n,方差为2n
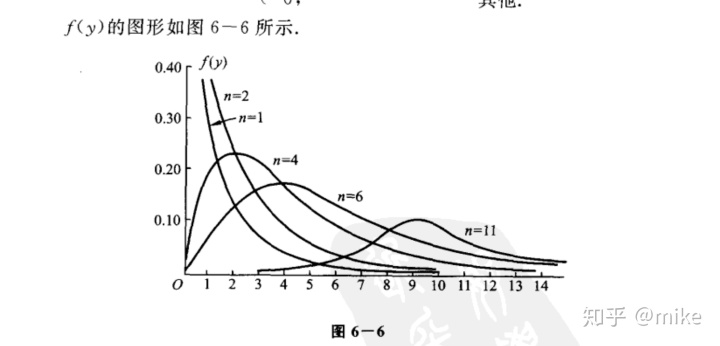
(2) t分布
(3)F分布

(4)正态总体的样本均值和样本方差的分布
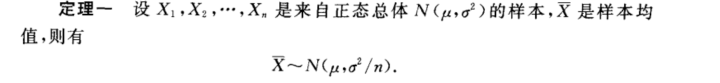

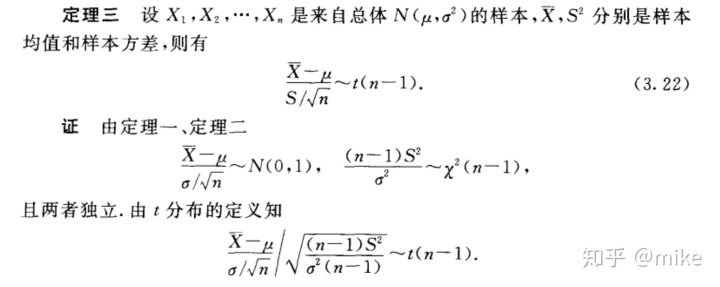
参数估计
(1) 点估计


点估计的两种方法
(1.1)矩估计法

(1.2)最大似然估计
例子:当普通人和猎人一同向一只鹿开枪,鹿倒下了,这时候大概率是由猎人打中的
同理,我们要找到一个参数使得似然函数的概率最大才能相信这个参数就是最好的估计,概率越大的,越值得被相信。
构造一个似然函数
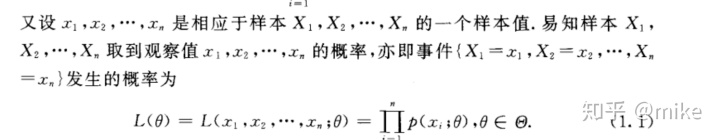
构造完似然函数以后,需要对两边取对数,然后对参数 Theta 求偏导,令倒数为零时,似然函数达到最大
分割线
最近整理了一份概率论和数理统计的知识点,有需要的可以参考参考
链接:https://pan.baidu.com/s/129qMQNzHs3StxipxybRLtg 密码:t2cs














 4923
4923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









