






温标是为了保证温度量值的统一和准确而建立的一个用来衡量温度的标准尺度。温标是用数值来表示温度的一套规则,它确定了温度的单位。各种温度计的数值都是由温标决定的。温度这个量比较特殊,它是利用一些物质的相平衡温度作为固定点刻在标尺上。固定点中间的温度值则利用一种函数关系来描述,称为内插函数(或称内插方程)。通常把温度计、固定点和内插方程叫做温标的三要素(或称为三个基本条件)
科普
知识
 前言
前言
还记得上周本系列文章我们学习了什么吗?学习过程?梯度下降?是的,我们用最简单的例子讲解了学习过程的具体步骤,让学习过程不至于那么难懂,通过对学习过程的讲解我们知道最原始的学习过程其实就是一个经验猜测(对于计算机来说),这是十分繁琐的任务,不具备数学意义的,因此才引出梯度下降算法,让学习过程变得更加科学化,并且有着严格的数学定义,这才能够被大多数人接受,如今,梯度下降算法已经成为了深度学习的基础,备受推崇,甚至诞生了各种随机梯度下降算法,批量梯度下降算法等等。然而,由于上周的文章已经比较长了,我们并没有对梯度下降的求解公式进行数学推导,今天就一起来看看吧!
一、数学推导
其实梯度下降算法对权重的更新公式的数学推导对现在的大多数人来说,已经很少亲自实操了,因为各种深度学习框架已经为我们实现了,我们只需要传入参数而已啦,但是,在我们公众号,我们坚持并尽可能的让大家知其然并知其所以然,我们还是带着大家一起来走进梯度下降算法的数学推导。一起感受数学的奥秘,相信大家都能看懂,不要退缩哦,相信小编,你一定可以的。
1. 上期回顾
(1)粉丝问题:上期文章发布不久,我就收到了粉丝朋友的提问,说实话他的问题其实挺实在的,实在到我们或许都忽略了问题存在的本身,最后,我也给粉丝解释清楚了,觉得问题有趣,小编就分享出来了,那位粉丝朋友的提问是:在你举例的学习过程的例子中,既然我们已经知道了真实值,为什么还需要去进行不断的学习呢?直接告诉计算机不就好了吗?是的,这个问题很简单,但是却问住了我一瞬间,我思索片刻便给出了解答,解答之前,我们可以思考一下这个问题的提出背景,是的,那位粉丝朋友是第一次接触深度学习这个领域,因此提出这样的问题不值得奇怪,但是为什么我们学习了一段时间深度学习的人来说却不会提出这样的问题呢?那是因为我们本身已经把训练过程,把真实值当作了存在的东西,换句话说只有当真实值存在,我们才可以进一步的深度学习,我们都默认了这个东西一直存在而且必须存在(监督学习是这样认为的),也就没有疑问为什么存在的东西还需要去学习。因此,针对哪位粉丝朋友我给出的解答是:因为我们最开始的学习过程是针对计算机来说的,但是计算机本身不知道外物为何物,真实值为何值,它仅仅只知道数据的运算,我们告诉它真实值是为了给它一个参考标准,使得它能够知道自己的输出结果与我们给定的真实值的差距是多大,我们真正的目的是要寻求我们的输入和真实值之间的映射关系(函数关系,对应关系)这个映射关系最后体现在权重w上,也就是需要找我们最需要的w, 那么问题还是没有解决,我都已经知道真实值了,我直接给计算机不就行了吗?不需要学习啦啊,是的,你可以给计算机真实值,但是计算机只知道这个的数据的真实值,那么下一次你换一个数据,计算机还知道真实值吗,此时的新数据如果输入,计算机就会说一句:你已非你,它已不在,不好意思,我不认识你,也就不能给你输出结果啦,下一个,别挡着 哈哈,答案是肯定不知道的啊,因此,我们必须去学习输入与输出之间的映射关系,把这种映射关系推广到其他类似数据上,这样才能保证其他类似的数据的输入也能得到一个准确的值,而不仅仅是只认识一个数据(物种),这就好比我们小时候的家长说这是汽车(假设当时是小汽车),那万一遇到大巴车,难道我们就不认识是汽车了吗?因此,正确的做法是,我们认识了当时的汽车,然后学习到了外观为那个样子的东西都可以称之为汽车,这也就是如上所说,从一个数据推广到类似的数据,我们都能够知道结果,怎么样,这个解释很好懂吧。
(2)梯度下降算法公式
还记的上期的梯度下降算法公式吗(其实梯度下降算法公式不太准确,正确应该是应用了梯度下降算法的权重更新公式,但是网上好多都放在一起说了,也就随大流吧)?见下图吧,带new的权重w是更新后的值,带old的权重w是前一次的w值,除开n不看,剩下的就是我们的梯度(误差函数对权重w的梯度,也就是求导)
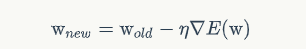
我们今天的重点是对后面的梯度进行数学推导,大家稳住啊,很简单的,推导之前,我们还得把上周的误差公式拿出来:
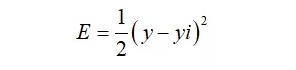
其中y为真实值,yi为我们的计算机的每一次输出值(yi=w*x),由于我们都不是仅仅训练一个样本,而是好几个数据,因此,我们的误差函数需要对每一个样本的误差求和:
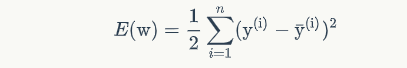
因此,误差函数变成了上面这个,这里的求和符号上面是n,也就说我们有n个数据,带上标i的y还是我们的真实值,i代表的是第i个数据,而后面的带了平均符号(-)并且带了上标i的y为我们的计算机的每一次输出值,我知道,这里可能有点不好转换,大家可以慢慢想一想,很简单的
接着,我们开始正式进入梯度求导了,也就是下面这个部分我们还没有推导出来。

很显眼,学过高数的我们都知道,这个地方是误差函数E对w的偏导,因此,我们可以写为:
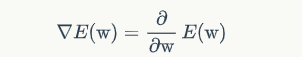
紧接着把E(w)根据之前的误差函数的公式进行替换后:
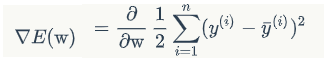
接下来就是对右边部分进行求导了,首先是复合函数求导,平方项2放到1/2的地方,即 2*1/2=1, 求和符号部分不变化,照写,紧接着对求和符号里面的东西进行对w求偏导,第一个是带上标i的真实值,为常数,求导为0,而,输出值的y= w*x(带了平均符号(-)并且带了上标i的y), 对其求导后只剩下了x,因此,我们就得到了:
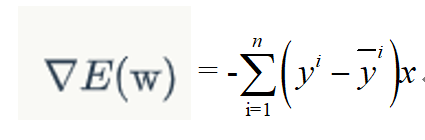
上图就是我们的最终梯度求解啦,在进行实际训练的时候,我们只需要将它带入到最开始的权重更新公式就可以进行反复迭代了,怎么样很简单吧,为了大家看的方便,小编这里手写一份推导给大家了:

公式和字都写的太丑了 ,不忍直视,大家将就着看哈
END
 结语
结语
今天的分享结束了,通过对梯度下降公式的数学推导,相信大家对其已不陌生,如有机会,我们将在深度学习实战篇中用代码实现梯度下降的训练过程,另外一点必须要知道的是,既然我们是深度学习,那么后面的梯度下降公式就会根据深度而出现略微的变化,我们现在的例子都是在仅有一层w的情况下推导的,然而真实的情况是,我们w可能有好几层,因此后期的反向传播,链式推导法则接应而来,希望大家不要退缩哦,我们,一同前行,无所畏惧。
编辑:玥怡居士|审核:小圈圈居士
 IT进阶之旅
IT进阶之旅



●深度学习理论篇之 (四) -- 梯度下降算法的魅力展现
●深度学习理论篇之 (三) -- 感知机的横空出世
●深度学习理论篇之 ---- 开山之石
 点亮在看哦~
点亮在看哦~














 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









