





本文提出了在一组带有掩膜的图像区域和它们对应的文本描述上微调CLIP的方法。通过挖掘现有的图像-标题数据集来收集训练数据,使用 CLIP 将遮罩图像区域与图像标题中的名词进行匹配。
论文地址:https://arxiv.org/pdf/2210.04150.pdf
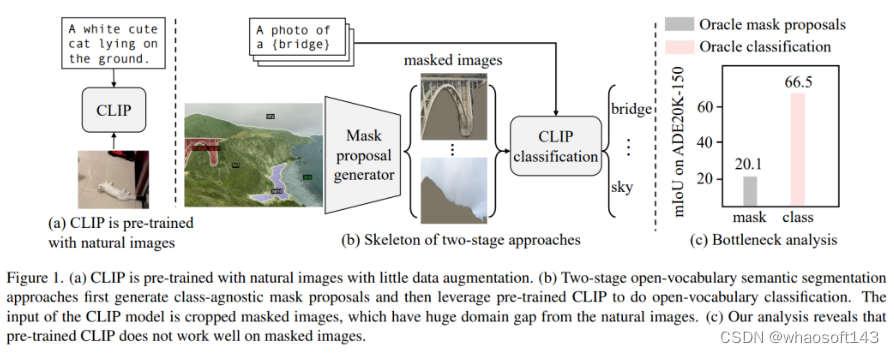
本文研究了开放式语义分割(Open-vocabulary semantic segmentation)问题,该问题旨在根据文本描述将图像分割为语义区域,这些描述在训练期间可能没有被看到。常用的Two-Stage方法首先是生成无类别掩码提议,然后利用预先训练的视觉语言大模型(如CLIP)对掩码区域进行分类。作者分析了这种方法的性能瓶颈主要在预训练的CLIP模型,因为它在掩膜图像上表现不佳。
为了解决这个问题,作者提出了在一组带有掩膜的图像区域和它们对应的文本描述上微调CLIP的方法。通过挖掘现有的图像-标题数据集(如COCO Captions)来收集训练数据,使用CLIP将掩码图像区域与图像标题中的名词进行匹配。与更精确且手动注释的具有固定类别的分割标签(如COCO-Stuff)相比,作者发现带噪声且多样化的数据集可以更好地保留CLIP的泛化能力。除了对整个模型进行微调外,作者还利用掩码图像中的“空白”区域,使用作者称之为“mask prompt tuning”的方法。
实验表明,在不修改CLIP任何权重的情况下,mask prompt tuning可以带来显着的改进,并且可以进一步改善完全微调的模型。特别是,在COCO数据集上训练并在ADE20K-150上进行评估时,该模型实现了29.6%的mIoU,比先前的最新技术水平高出8.5%。这也是第一次,开放式词汇的通用模型在没有Dataset specific adaptations的情况下性能能与2017年的有监督模型相媲美。
Introduction
首先还是对研究问题的描述。语义分割旨在将像素分组为具有相应语义类别的有意义的区域,虽然已经取得了显著的进展(例如2015年的FCN,2017年的DeepLab,2018年的Encoder-Decoder等),但现代语义分割模型主要是用预定义的类别进行训练,无法推广到未知类别。相反,人类以开放词汇方式理解场景,通常有成千上万种类别。为了接近人类水平的感知,作者研究了开放式语义分割,其中模型通过文本描述的任意类别对图像进行分割。
视觉语言模型(例如CLIP)可以从十亿级别的图像-文本对中学习丰富的多模态特征。先前的研究表明,视觉语言模型对于开放式词汇分类具有优越的能力,因此提出了使用预训练视觉语言模型进行开放式语义分割的方法。其中,Two-Stage方法表现出了巨大的潜力:该方法首先生成无类别掩码提议,然后利用预先训练的CLIP执行开放式词汇分类。作者认为这种Two-Stage方法的成功依赖于两个假设:
(1)模型可以生成无类别的掩膜。
(2)预训练的CLIP可以将其分类性能转移到对掩膜的分类上。
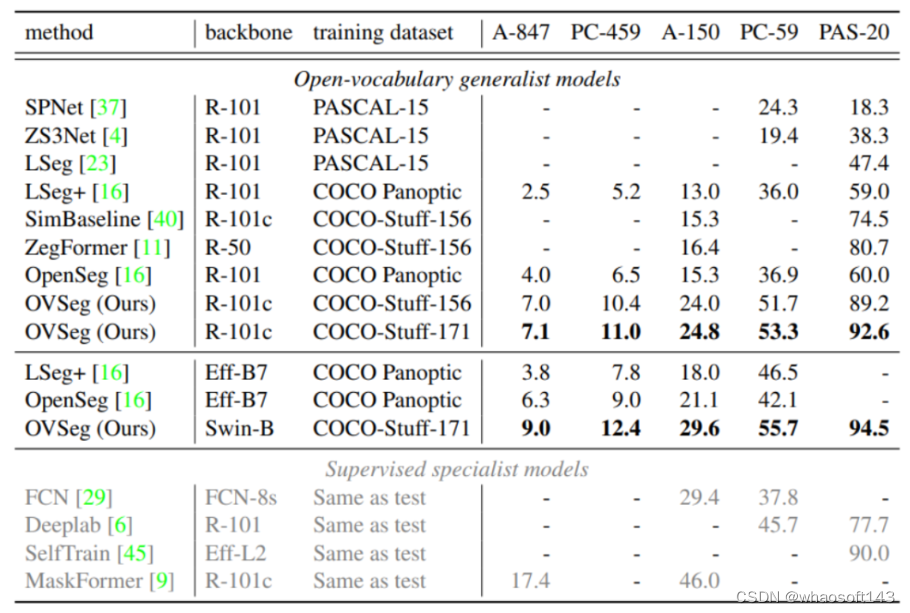
为了验证这两个假设,作者进行了以下分析:首先,作者假设有一个绝对正确的掩膜生成器和一个正常的CLIP分类器。我们使用真实的掩膜作为这个生成器,并将生成的掩膜输入到预训练的CLIP进行分类。该组合在ADE20K-150数据集上仅达到20.1%的mIoU。接下来,我们假设拥有一个绝对正确的分类器,但是只使用普通的掩膜生成器-一个在COCO数据集上预训练的MaskFormer。作者首先提取生成的掩膜,然后将每个区域与地面真实物体掩膜进行比较,找到重叠最大的物体,并将物体标签分配给该提取的掩膜区域。尽管掩膜生成器并不完美,但该组合的mIoU显着提高至66.5%。
作者所做的这个实验清楚地表明,预训练的CLIP无法对生成的掩膜进行令人满意的分类,并且这是Two-Stage开放词汇分割模型的性能瓶颈。作者认为这是由于掩膜图像与CLIP的训练图像之间存在 Domain gap。另一方面,生成的掩膜是从原始图像中裁剪并调整了大小,会受到嘈杂的分割掩膜的干扰。
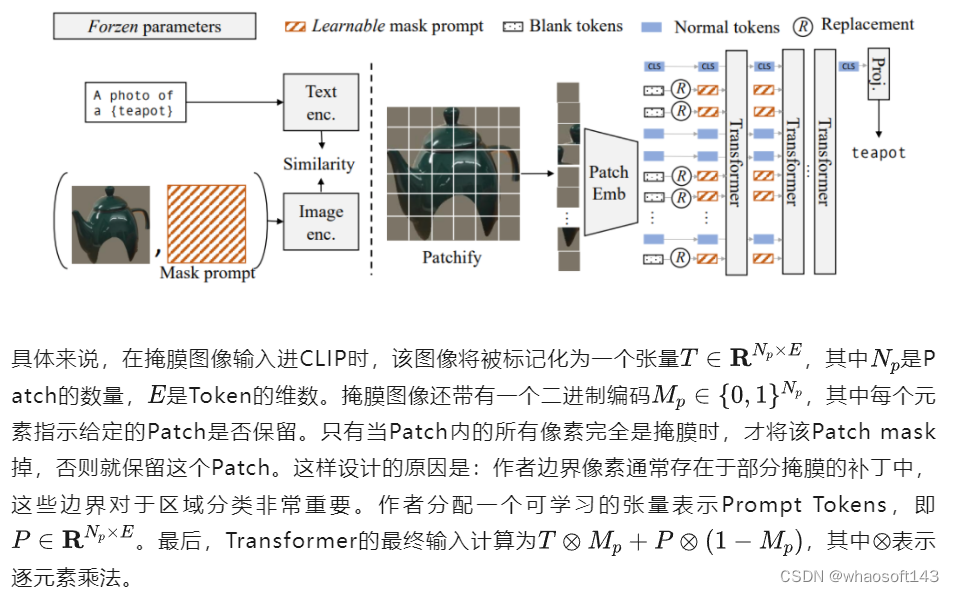
紧接着,作者提出的下一个问题是如何有效地微调CLIP?掩膜图像和自然图像之间最显著的区别在于掩膜图像中的背景像素被掩蔽掉,导致许多空白区域,在将其输入CLIP Transformers时将被转换为“Zero Tokens”。这些tokens不仅不包含任何有用的信息,而且还会造成模型的Domain偏移(因为这些Zero Tokens在自然图像中不存在),并导致性能下降。为了解决这个问题,作者提出了Mask Prompt Tuning。在对掩膜图像进行tokenize的时候,作者使用可学习的Prompt Tokens替换“Zero Tokens”。作者发现,仅使用Mask Prompt Tuning就可以显著提高CLIP在掩膜上的性能。这说明Mask Prompt Tuning可以进一步提高性能,对于打破性能瓶颈具有非常重要的作用。
Method
1. Two-Stage模型
作者设计的Two-Stage开放词汇语义分割模型如下图所示。它由一个生成掩膜的分割模型和一个开放词汇分类模型组成。
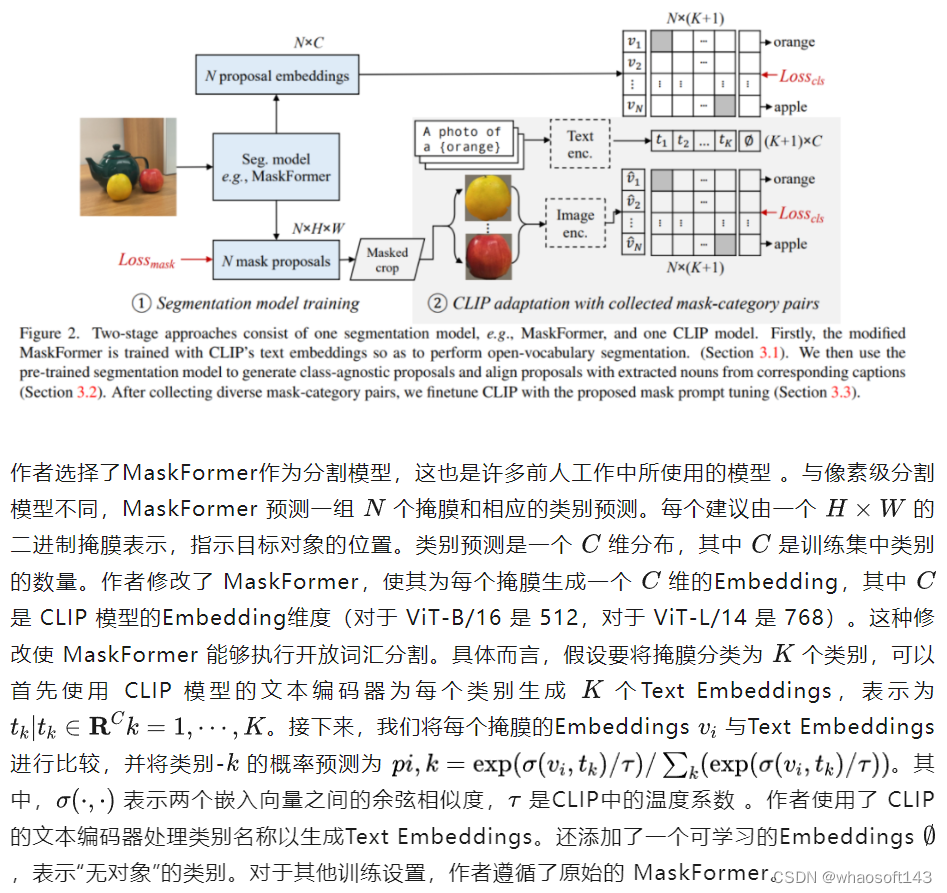
作者同时也指出,以这种方式训练的掩蔽建议生成器并不严格“类别无关”,因为对象的定义是由训练集中的类别定义确定的。例如,如果训练集只包含“人”作为一个类别,那么模型不太可能自动将人分割成“面部”、“手”、“身体”或更精细的身体部位。如何训练一个通用的、类别无关的模型来生成掩蔽建议是一个重要的话题,但超出了本文的范围。
2. 收集掩膜-类别对
为了使CLIP更好地处理掩蔽图像,作者尝试在由掩膜图像和文本对组成的数据集上微调CLIP。一种直接的解决方案是利用人工注释的分割标签,例如来自COCO-Stuff。这些标签很准确,但类别集合是封闭的。作者尝试了这种解决方案,并从COCO-Stuff中收集了965K个掩膜-类别对,涵盖了171个类别(例如香蕉、橙子)。然后,作者微调了CLIP的图像编码器,同时冻结文本编码器。然而,作者发现这种朴素的方法限制了CLIP的泛化能力,如果出现了更多的未见类别,性能会下降。作者认为由于数据集中文本词汇量有限,微调后的CLIP过度拟合于171个类别,而失去了对未知类别的泛化能力。
作者敏锐地察觉到,与分割标签相比,图像标题包含关于图像的更丰富的信息,并涉及更大的词汇表。例如,在下图中,图像的标题是“There are apple and orange and teapot.”。尽管“apple”和"orange"是COCO-Stuff中有效的类别,但其他非有效类别的信息却被忽略了。
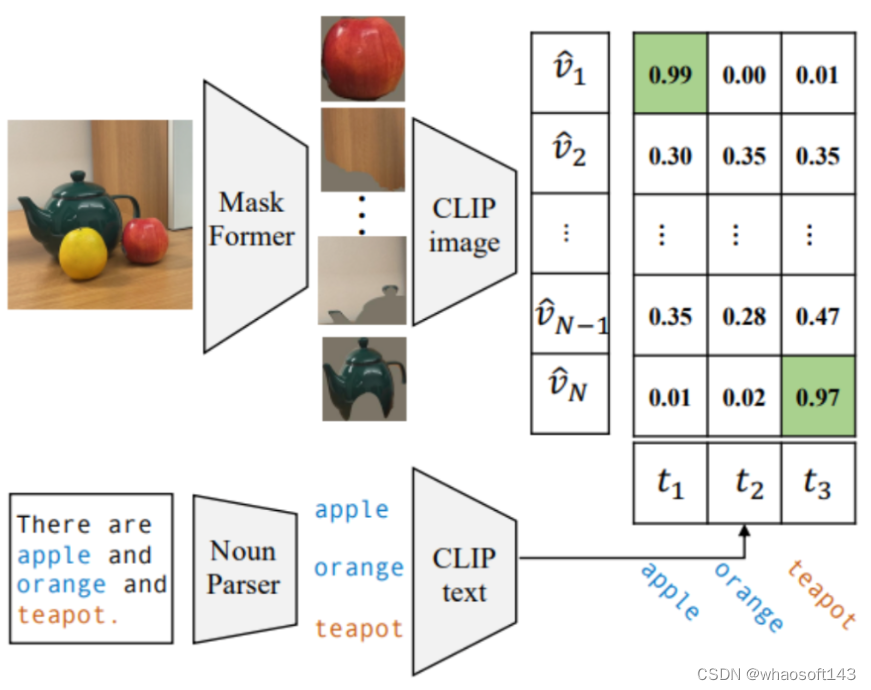
基于这一观察,作者设计了一种自标记策略来提取掩蔽-类别对。如上图所示,给定一张图片,作者首先使用预训练的MaskFormer生成掩膜。同时,从相应的图像标题中,使用现成的语言解析器(Noun Parser)提取所有名词,并将它们视为潜在的类别。然后,我们使用CLIP将最匹配的掩膜与每个类别配对。从COCO-Captions中,我们使用每张图片的5个标题收集了1.3M个掩蔽-类别对和27K个唯一名词,或者使用每张图片的1个标题收集了440K个掩蔽-类别对和12K个名词。实验表明,这个带有噪声但多样化的掩膜-类别数据集比手动分割标签可以使模型更加鲁棒。
3. Mask Prompt Tuning
收集数据集后,一个自然的问题就是如何有效地微调CLIP?作者指出:掩膜与自然图像之间最显著的区别是掩膜中的背景像素被设置为零,导致许多空白区域。当将掩膜图像输入给CLIP时并进行Tokenize的时候,这些空白区域将变成“Zero Tokens”。这些Zero Tokens不仅不包含有用的信息,而且会给模型带来Domain的偏移(因为这些令牌在自然图像中不存在),从而导致性能降低。为了缓解这个问题,作者提出了Mask Prompt Tuning,如下图所示。
讨论
总结一下,作者的主要工作如下:
- 分析了目前主流的Two-Stage方法架构,设计了对比试验,说明了制约该方法性能的主要因素在于预训练的CLIP在掩膜图像上的分类性能不够好,为后续的改进指明了方向。
- 设计了一种自标记策略来提取掩膜-类别对用于CLIP微调,以适应掩膜图像并保留其泛化能力,试验表明,这样的自标记策略能够很好提升模型的泛化性。
- 针对掩膜图像的特点:具有大量的Zero Patch提出了Mask Prompt Tuning方法。这种方法不改变CLIP的权重,通过引入可编码的Prompt Tokens来替换Zero Tokens,使多任务权重共享成为可能。
- 首次展示了Open-Vocabulary Models可以在不进行特定于数据集适应的情况下达到可以媲美2017年有监督模型的性能。















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









