






1、StyleDiffusion: Controllable Disentangled Style Transfer via Diffusion Models
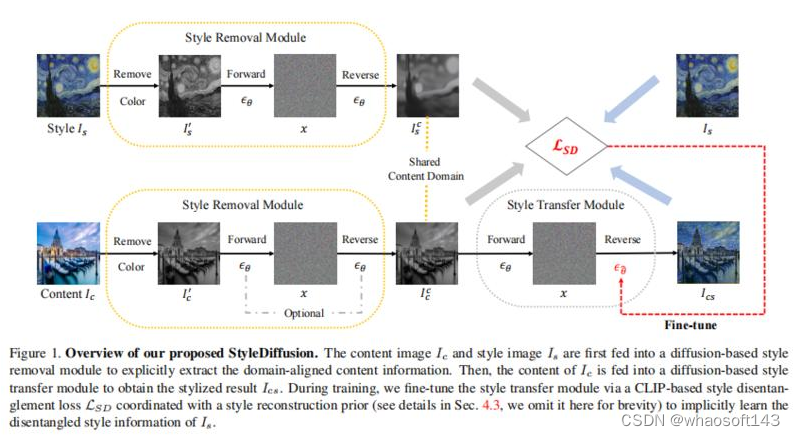
内容和风格(Content and style disentanglement,C-S)解耦是风格迁移的一个基本问题和关键挑战。基于显式定义(例如Gram矩阵)或隐式学习(例如GANs)的现有方法既不易解释也不易控制,导致表示交织在一起并且结果不尽如人意。
本文提出一种新的C-S解耦框架,不使用先前假设。关键是明确提取内容信息和隐式学习互补的风格信息,从而实现可解释和可控的C-S解耦和风格迁移。提出一种简单而有效的基于CLIP的风格解耦损失,其与风格重建先验一起协调解耦C-S在CLIP图像空间中。通过进一步利用扩散模型强大的风格去除和生成能力,实现了优于现有技术的结果,并实现了灵活的C-S解耦和权衡控制。
工作为风格迁移中的C-S解耦提供了新的见解,并展示了扩散模型在学习良好解耦的C-S特征方面的潜力。
2、Zero-Shot Contrastive Loss for Text-Guided Diffusion Image Style Transfer

扩散模型在文本引导的图像风格迁移中显示出巨大潜力,但由于其随机的性质,风格转换和内容保留之间存在权衡。现有方法需要通过耗时的扩散模型微调或额外的神经网络来解决这个问题。
为解决这个问题,提出一种零样本对比损失的扩散模型方法,该方法不需要额外的微调或辅助网络。通过利用预训练扩散模型中生成样本与原始图像嵌入之间的分块对比损失,方法可以以零样本的方式生成具有与源图像相同语义内容的图像。
方法不仅在图像风格迁移方面优于现有方法,而且在图像到图像的转换和操作方面也能保持内容并且不需要额外的训练。实验结果验证了方法有效性。https://github.com/YSerin/ZeCon
3、Diffusion in Style

基于这样一个关键观察:由Stable Diffusion生成的图像的风格与初始潜在张量相关联。如果不将这个初始潜在张量调整到风格,则微调会变得缓慢、昂贵且不切实际,特别是当只有少数目标样式图像可用时。相反,如果调整这个初始潜在张量,则微调会变得更加容易。
Diffusion in Style在样本效率和速度上具有数个数量级的提升。与现有方法相比,它还可以生成更加令人满意的图像,这一点在定性和定量比较中得到了证实。https://ivrl.github.io/diffusion-in-style/
4、PODIA-3D: Domain Adaptation of 3D Generative Model Across Large Domain Gap Using Pose-Preserved Text-to-Image Diffusion

最近,在3D生成模型方面取得重大进展,然而在多领域训练这些模型是一项具有挑战的工作,需要大量的训练数据和对姿势分布的了解。
文本引导的域自适应方法通过使用文本提示将生成器适应于目标域,避免收集大量数据。最近,DATID-3D在文本引导域中生成令人印象深刻的视图一致图像,利用文本到图像扩散模型保持文本的多样性。然而,将3D生成器调整到与源域存在显著领域差异的领域,仍具挑战,包括:1)转换中的形状和姿势权衡,2)姿势偏差,以及3)目标域中的实例偏差,导致生成的样本中3D形状差、文本图像对应性差和域内多样性低。
为解决这些问题,提出PODIA-3D流程,用保留姿势的文本到图像扩散式域适应的方法来进行3D生成模型训练。构建一个保留姿势的文本到图像扩散模型,在进行领域变化时使用极高级别的噪声。提出专用于一般的采样策略,以改善生成样本的细节。此外,为克服实例偏差,引入一种文本引导的去偏方法,以提高域内多样性。因此,方法生成出色的文本图像对应性和3D形状,而基线模型大多失败。定性结果和用户研究表明,方法在文本图像对应性、逼真程度、生成样本的多样性和3D形状的深度感方面优于现有的3D文本引导域自适应方法。https://gwang-kim.github.io/podia_3d/
5、DS-Fusion: Artistic Typography via Discriminated and Stylized Diffusion

介绍一种新方法,通过将一个或多个字体的字母进行风格化,视觉上传达输入单词语义,并确保输出保持可读性,自动生成艺术字体。
为应对一系列挑战,包括冲突的目标(艺术化风格化 vs. 可读性)、缺乏事实根据和庞大的搜索空间,方法利用大型语言模型将文本和视觉图像进行风格化,并基于扩散模型骨干构建一个无监督的生成模型。具体而言,采用潜在扩散模型(LDM)中的去噪生成器,并加入一个基于CNN的判别器,将输入风格调整到输入文本上。判别器使用给定字体的光栅化图像作为真实样本,将去噪生成器的输出作为伪样本。模型被称为DS-Fusion,表示具有有区分度和风格化的扩散。
大量示例、定性定量评估及消融研究展示方法质量和多样性。与CLIPDraw、DALL-E 2、Stable Diffusion以及由艺术家精心制作的字体进行的用户研究显示DS-Fusion的强大性能。https://ds-fusion.github.io/















 3182
3182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









