





本文解释CockroachDB复制和分布特性如何影响读和写。
本文以总结某些重要的CockroachDB架构概念开始,接着,介绍几个简单的读写场景。
--注意:
1)一个查询通过CockroachDB架构各层的更多细节,请参考分布式事务的生命周期。
一.重要概念
1.集群(Cluster):CockroachDB部署,充当单个逻辑应用。
2.节点(Node):运行CockroachDB的单个机器。多个节点联合一起创建集群。
3.范围(Range):CockroachDB存储所有的用户数据(表,索引等。),以及几乎一个巨大的键值对排序映射的所有系统数据。该键空间分成"范围",键空间的连续块,以便每个键值总是能在单个范围内发现。
从SQL角度,表及其二级索引最初映射到单个范围,范围中的每个键值对代表表(也称为主键索引,因为表通过主键排序)中的一行数据,或二级索引中的一行数据。范围一达到512MiB大小,其将分成两个范围。当表和二级索引持续变大时,该过程对新范围会持续。
4.副本(Replica):CockroachDB复制每个范围(默认为三倍)且将每个副本存储到不同的节点上。
5.租约持有者(Leaseholder):对每个范围,其中一个副本持有"范围租约(range lease)"。该副本,称为"租约持有者",为接收和协调该范围上所有读写请求的副本。
不像写,读请求访问租约持有者并将结果发给客户端,而无需与其他范围副本协调。这减少了相关网络往返和可能的,因为租约持有者保证是最新的,这是由于所有写请求都会到租约持有者的事实。
6.Raft领导者(Raft Leader):对每个范围,副本之一是写请求的领导者。通过Raft共识协议,该副本确保提交写前,多数副本(领导者和足够的追随者)基于它们的Raft日志会同意。Raft领导者和租约持有者几乎总是同一个副本。
7.Raft日志(Raft log):对每个范围,是一个其副本已同意的范围的写按时间排序的日志。该日志存储于每个副本的磁盘上,且是范围一致复制的真实来源。
如上所述,当查询执行时,集群将请求路由到包含相关数据范围的租约持有者。如果查询接触多个范围,请求会到多个租约持有者。对读请求,仅相关范围的租约持有者获取数据。对写请求,Raft共识协议规定写提交前相关范围的多数副本必须达成一致。
让我们考虑一下这些机制如何在一些假设的查询中发挥作用。
二.读场景
首先,设想一个简单的读场景:
1.集群中有3个节点。
2.有3个小表,每个可以在单个范围内容纳。
3.范围被复制3次(默认)。
4.查询在节点2执行,从表3中读取数据。
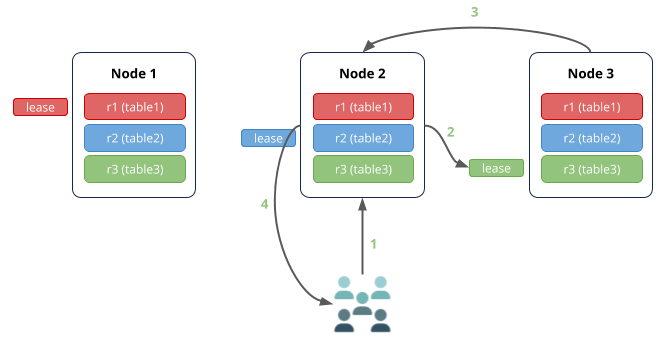
该场景中:
1.节点2(网关节点)从接收从表3读取数据的请求。
2.表3的租约持有者在节点3,因此,该请求被路由到那里。
3.节点3将数据返回到节点2。
4.节点2响应客户端。
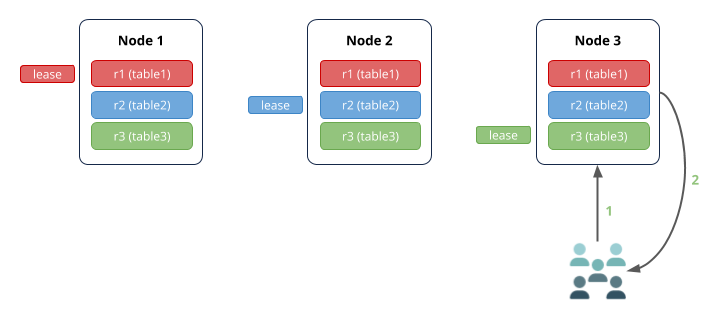
如果拥有相关范围租约持有者的节点接收到该查询,网络跳数更少:
三.写场景
现在,设想一个简单写场景,其中,查询在节点3执行,往表1写数据:
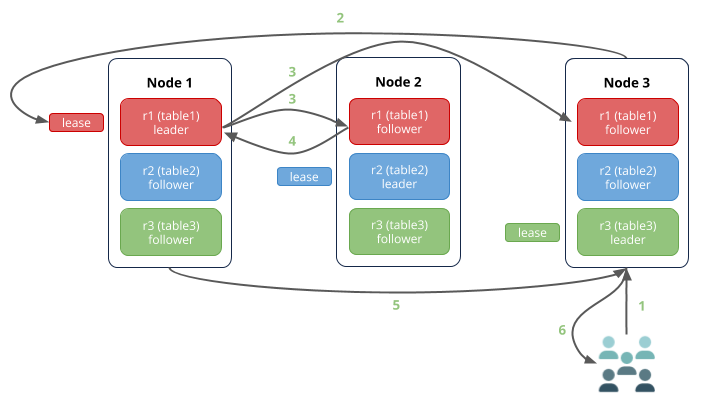
该场景中:
1.节点3(网关节点)接收往表1写数据的请求。
2.表1的租约持有者在节点1,因此,请求被路由到那里。
3.租约持有者与Raft领导者为同一副本(典型地),因此,其同时将写附加到其自己的Raft日志,并通知其节点2和节点3上的追随者副本。
4.一旦一个追随者将写附加到其Raft日志(这样,大部分副本基于同一Raft日志达成一致),其通知领导者,并将写提交到一致副本的键值。该图中,节点2上的追随者确认写,但其也可以是节点3上的追随者。也注意未涉及一致同意的追随者通常其他副本后很快提交写。
5.节点1向节点3返回提交确认。
6.节点3响应客户端。
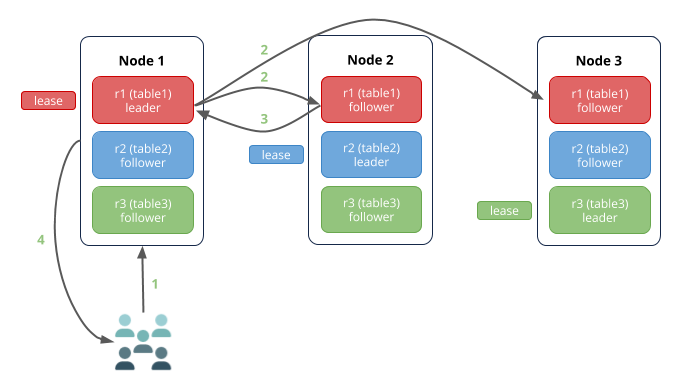
正像读场景,如果拥有相关范围租约持有者和Raft领导者的节点接收了写请求,网络跳数更少:
四.网络和I/O瓶颈
记住上述的例子,将网络延迟和磁盘I/O认为潜在的性能瓶颈总是很重要。总之:
1.对读来说,网关节点和租约持有者间的跳数会增加延迟。
2.对写来说,网关节点和租约持有者/Raft领导者将的跳数,以及租约持有者/Raft领导者和Raft追随者间的跳数,会增加延迟。此外,由于写条件前Raft日志项目被持久化到磁盘,因此,磁盘I/O很重要。
五.个人观点
1.本文对通过特定场景对Cockroach读写机制及过程进行了详尽讲述。
2.本文对CockroachDB中各层间机制和原理的理解和掌握起到了巩固和加强作用。















 1257
1257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









