







简介:OpenAI研发的GPT-3模型,尤其是其Davinci版本,代表了自然语言处理领域的重大突破,具有1750亿参数,提升了AI在理解和生成语言的能力。GPT-3的Davinci版本以顶级性能著称,在多种语言任务中表现卓越。它不仅丰富了AI在创意写作和内容生成的应用,还激发了人们对下一代GPT-4模型的期待。AIGC的未来充满潜力,同时也带来了伦理和版权上的挑战。 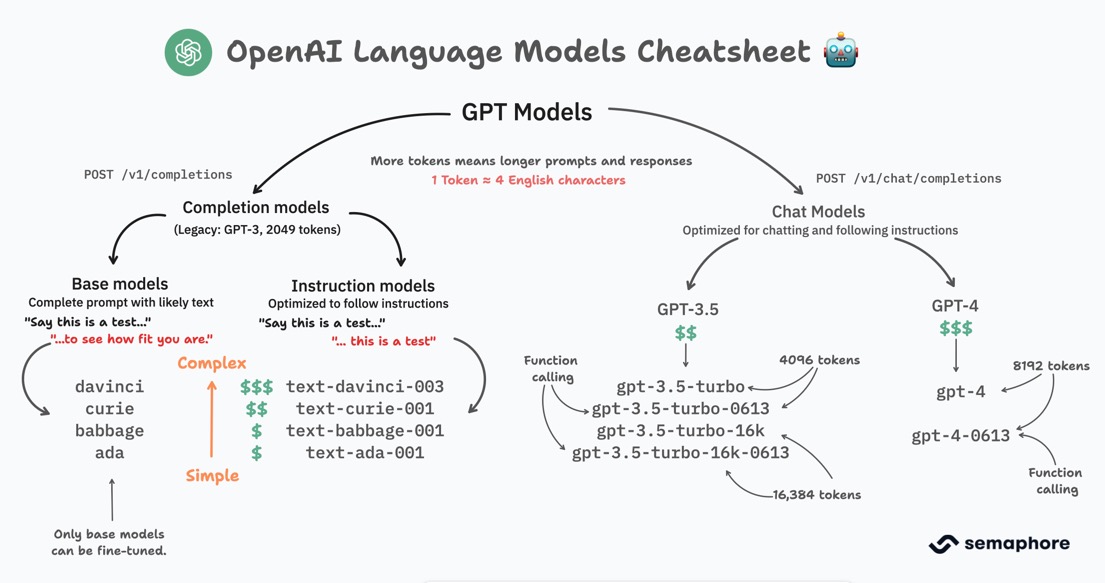
1. OpenAI组织简介及其在AI自然语言处理领域的地位
在当今AI技术日新月异的时代,OpenAI无疑站在了时代的前沿。OpenAI作为一个非盈利的AI研究公司,自成立以来,就以开放和透明为理念,致力于推动AI技术的积极发展,尤其是在自然语言处理(NLP)领域取得了显著的成就。
OpenAI由一群有远见的科技界人士于2015年创立,其目标是开发出能够有益于全人类的AI技术。公司发展至今,不仅推出了许多引人注目的AI研究成果,如DALL·E和GPT系列模型,还在AI安全、伦理和公平性方面做出了大量工作。
OpenAI的成就不仅体现在技术上,它的开放文化、对AI的长期承诺以及与全球研究者的合作,共同塑造了它在AI自然语言处理领域的权威地位。接下来,我们将探讨OpenAI旗下的GPT-3模型,它如何定义了当前AI技术的前沿,以及其对未来AI应用的深远影响。
2. GPT-3模型特性与突破性进展
2.1 GPT-3模型的核心技术解析
2.1.1 架构设计和学习机制
GPT-3(Generative Pretrained Transformer 3)是OpenAI研发的一种基于Transformer架构的大型语言模型,它代表了自然语言处理(NLP)技术的前沿。GPT-3模型的核心在于其庞大的参数规模(175B个参数),这使它能够捕捉语言中的细微差别和上下文关系。
架构设计方面,GPT-3基于深度学习的Transformer模型,该模型由多层的注意力机制堆叠而成,能够有效地处理长距离依赖问题。模型的每一层都是由自注意力(self-attention)机制和前馈神经网络组成,自注意力机制能够让模型在不同位置的输入之间建立直接关系,而前馈神经网络则对这些关系进行处理。
学习机制方面,GPT-3采用了无监督的预训练(pre-training)加有监督的微调(fine-tuning)模式。在预训练阶段,GPT-3通过在大量文本数据上进行自我监督学习,掌握语言的通用规律。预训练完成后,模型可以针对特定任务进行微调,这通常需要更少的数据,因为模型已经具备了理解语言的能力。
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 初始化分词器和模型
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 编码文本输入
input_text = "The new GPT-3 model is"
inputs = tokenizer(input_text, return_tensors="pt")
# 生成文本
outputs = model.generate(**inputs, max_length=50, num_return_sequences=1)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
在上述代码中,我们首先导入了PyTorch库和transformers库中的GPT-2模型和分词器。然后我们对模型进行了初始化,并对一段文本进行了编码。最后,我们调用模型生成文本的方法,对输入的文本进行了延续。
参数说明: - from_pretrained('gpt2') :加载预训练的GPT-2模型和分词器。 - input_text :模型输入的文本内容。 - tokenizer(input_text, return_tensors="pt") :使用分词器对输入文本进行编码。 - model.generate() :模型生成文本的方法,其中 max_length=50 定义了生成文本的最大长度。
逻辑分析: - 预训练模型在大规模文本语料库上学习通用语言知识。 - model.generate 方法运用了预训练模型,通过自回归方式逐词预测,生成连贯的文本序列。 - 生成过程中模型会根据前面生成的词不断调整接下来的预测,这是典型的自回归模型行为。
2.1.2 模型训练与优化策略
训练一个GPT-3这样的模型是一个资源密集型的过程,需要使用大量的数据和计算资源。为了有效地训练GPT-3,OpenAI采取了一系列优化策略。其中最重要的是使用了分布式训练技术,这允许模型在多个GPU或TPU上并行计算,大幅度缩短了训练时间。
为了进一步优化模型训练,GPT-3采用了混合精度训练,这是一种提高计算效率和训练速度的技术,通过在训练过程中混合使用单精度(FP32)和半精度(FP16)浮点数运算来实现。此外,梯度累积技术也被应用,它可以在内存受限的情况下通过累积多个小批次的梯度来模拟一个大批次的梯度更新。
from transformers import AdamW, get_linear_schedule_with_warmup
# 假设我们已经有了预训练好的模型和分词器
optimizer = AdamW(model.parameters(), lr=5e-5)
total_steps = len(train_dataloader) * num_epochs
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for batch in train_dataloader:
inputs = tokenizer(batch['input'], padding=True, return_tensors="pt")
labels = tokenizer(batch['labels'], padding=True, return_tensors="pt")
outputs = model(**inputs, labels=labels['input_ids'])
loss = outputs.loss
loss.backward()
optimizer.step()
scheduler.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_dataloader)
print(f'Epoch {epoch} Average Training Loss: {avg_loss}')
在上面的代码示例中,我们使用了 AdamW 优化器和与之配套的学习率调度器 get_linear_schedule_with_warmup 。在训练的每个epoch中,我们会遍历训练数据加载器 train_dataloader ,为每一批次的数据计算损失并进行梯度回传,然后更新模型参数。同时,调度器会在每个步骤调用后更新学习率。
参数说明: - lr=5e-5 :设置学习率为5e-5,这是根据实验结果选定的一个比较小的学习率,有助于稳定训练过程。 - num_warmup_steps=0 :在此示例中,我们没有设置预热步骤,这通常用于当学习率开始时小幅度增加,以防止训练初期的不稳定性。 - num_training_steps :这是总的学习步骤数,由数据加载器的长度和训练轮次决定。
逻辑分析: - 通过优化器 AdamW ,模型参数根据损失函数进行调整,以最小化损失。 - 学习率调度器 get_linear_schedule_with_warmup 控制学习率的变化趋势,确保训练过程的稳定和效率。 - 在训练过程中,每个批次的数据输入模型后,模型会对损失进行反向传播并更新参数,同时梯度被累积和优化。 - 这些优化策略共同确保了在有限的计算资源下,大规模模型如GPT-3能够高效地进行训练。
3. Davinci版本特点与任务处理能力
3.1 Davinci版本的创新点
3.1.1 模型微调与个性化应用
Davinci版本的创新之一在于其模型微调功能,允许开发者或用户根据特定任务的需求对模型进行个性化调整。这一特性不仅提高了模型的适应性,也极大地拓展了GPT-3在不同领域内的应用广度。通过微调,可以在保持模型原有能力的基础上,赋予模型新的任务导向性知识和处理细节的能力。
在微调过程中,首先需要准备一个较小的数据集,该数据集包含与特定任务相关的样本。然后,通过在该数据集上继续训练GPT-3模型,使之学会针对特定任务的处理方式。这个步骤通常需要对模型的底层结构进行细微的修改,并使用更小的、专门的任务数据集进行训练。
为了演示模型微调的具体过程,假设我们要调整GPT-3以优化其在法律文档生成方面的能力。我们可能会选择一个小型的法律文书样本集合,并在这个数据集上进行微调。这需要对模型进行多次迭代,直到它在法律文本生成任务上表现出色。
import torch
from transformers import GPT3Tokenizer, GPT3ForCausalLM
# 初始化分词器和模型
tokenizer = GPT3Tokenizer.from_pretrained("openai")
model = GPT3ForCausalLM.from_pretrained("openai")
# 准备微调数据集
train_dataset = [
"Legal agreement template for service contract.",
"A brief note on the terms of employment.",
"Court hearing notice template.",
# ... 更多样本
]
# 对数据集进行编码
inputs = tokenizer(train_dataset, padding=True, truncation=True, return_tensors="pt")
# 微调模型
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
for epoch in range(3): # 一般需要多轮训练
model.train()
optimizer.zero_grad()
outputs = model(**inputs)
loss = outputs.loss
loss.backward()
optimizer.step()
print(f"Epoch {epoch}, Loss: {loss.item()}")
# 保存微调后的模型
model.save_pretrained("./davinci_finetuned")
3.1.2 处理复杂任务的案例研究
复杂任务处理是Davinci版本另一个引人注目的特点。在很多情况下,单一模型很难直接应对那些需要高度推理、决策和问题解决能力的任务。Davinci版本通过引入多层次结构和更复杂的优化算法,提高了模型对于复杂任务的处理能力。
比如,在处理自然语言理解(NLU)和自然语言生成(NLG)相结合的任务时,Davinci能够更好地理解用户意图,并生成连贯和逻辑性强的回答。一个典型的案例是情感分析和摘要生成的结合,Davinci可以首先分析一段文本的情感倾向,然后基于这种理解生成一个精准的摘要。
3.2 Davinci在AI写作中的应用
3.2.1 内容生成与编辑辅助
Davinci版本在AI写作领域中的一个显著应用是内容生成与编辑辅助。Davinci不仅可以生成高质量的文本,还能根据用户的反馈进行自我修正,从而在写作和编辑过程中提供有效帮助。这一特点对于作家、记者、市场营销人员等职业尤为重要,因为它可以显著提高他们的工作效率和内容质量。
AI写作模型如Davinci通常会在一个给定的提示(prompt)下生成文本。例如,我们可以给模型提供一个开头段落,并请求模型继续写下去。Davinci模型会根据这个开头产生一个连贯的、符合逻辑的文本段落。
prompt = "The future of technology is"
# 生成文本
completion = model.generate(tokenizer.encode(prompt), max_length=100, do_sample=True)
print(tokenizer.decode(completion))
3.2.2 互动式写作与反馈循环
互动式写作是Davinci的另一个亮点。通过提供即时反馈,Davinci版本的模型能够让用户参与到一个动态的写作和修正过程中。在这个过程中,模型不断地根据用户的输入进行调整,同时用户也可以根据模型生成的文本提供反馈。这种循环互动的模式极大地提高了生成文本的质量和相关性。
为了实现这个功能,Davinci通常需要集成到一个交互式应用中,这样模型就可以实时地处理用户的输入和反馈。例如,我们可以构建一个简单的聊天机器人应用,它使用Davinci模型来响应用户的输入,并根据用户的评价来调整其响应策略。
# 假设这是一个基于Davinci的交互式对话应用
user_input = input("You: ")
while user_input.lower() != "exit":
response = model.predict(user_input) # 这里简化了调用过程
print("AI: ", response)
user_input = input("You: ")
通过这些创新点,Davinci版本的GPT-3不仅展示了其在AI写作领域的潜力,还推动了自然语言处理技术的前沿发展。通过进一步微调和优化,我们有理由期待Davinci在未来的AI写作应用中将扮演更为重要的角色。
4. AI写作能力的提升及其应用潜力
4.1 AI写作能力的进化历程
4.1.1 从模板驱动到语义理解
在早期的AI写作系统中,模板驱动的写作方法是主流,这些模板通常基于大量的文本数据构建,通过填空或者替换模板中的元素来生成文本。这种方式在很大程度上依赖于设计者为特定类型的文档预设的结构和内容。然而,这种方法的局限性在于灵活性和创造性不足,无法应对更加丰富多变的写作需求。
随着技术的发展,尤其是深度学习技术的突破,AI写作能力得到了显著提升。现在,高级的AI写作系统能够通过语义理解来生成内容,这得益于自然语言处理(NLP)技术的进步,尤其是上下文理解和预测模型的改进。例如,基于Transformer架构的模型,如GPT系列,能够捕捉长距离依赖关系,理解复杂的语言结构,并基于语境生成连贯、有意义的文本。
4.1.2 自然语言生成技术的演进
自然语言生成(NLG)技术的演进是AI写作能力提升的关键因素之一。NLG技术从最初的基于规则的系统,通过模板和脚本来生成固定的文本,逐渐发展到基于统计的系统,能够根据大量文本数据学习语言的概率分布,并根据输入的指令生成文本。现在,深度学习的引入使得NLG系统能够进行端到端的学习,不仅能够模仿特定的写作风格,还能够创造性地生成新的内容。
举例来说,基于深度学习的文本生成模型如GPT系列,采用了大量的预训练数据进行训练,这些模型在理解了语言的深层结构之后,能够自动生成包括故事、诗歌、技术文档等在内的多种类型文本。模型的这种生成能力,依托于其庞大的参数规模以及先进的训练方法,如无监督学习、微调等技术。
4.2 AI写作的应用场景探索
4.2.1 内容创作与个性化营销
AI写作的能力不仅仅局限于生成文本,更重要的是,它能够根据目标受众的兴趣和行为习惯,创建个性化的内容。在内容创作领域,AI能够分析大量的历史数据,结合用户反馈,生成符合目标市场口味的文章、报告或者故事。这种个性化的内容创作在营销领域尤为有价值,因为营销内容需要经常更新,并且高度相关于目标客户。
例如,电商平台上,AI可以自动撰写产品描述,或者根据用户的搜索历史和购买记录生成个性化的推荐内容。这不仅提高了效率,还增加了用户黏性。在内容创作方面,AI可以通过分析热门趋势和用户偏好,创作出可能引发病毒式传播的热点文章。
4.2.2 教育辅助与语言学习工具
AI写作技术的进步为教育领域带来了革新性的改变。现在的AI写作工具可以作为教师的助手,自动批改学生的作文,提供及时的反馈,帮助学生改进写作技巧。更进一步,AI可以根据学生的写作水平和学习进度,生成个性化的写作练习和提示,使得学习过程更加高效。
在语言学习方面,AI写作工具可以模拟真实的语言使用场景,帮助学习者在实践中学习写作。例如,通过与AI聊天机器人进行交互,学习者可以得到即时的写作指导和修正建议。这种方法不仅提高了学习者的写作能力,还加强了他们对语言的语境理解。
这些应用场景仅仅是AI写作能力的冰山一角。随着AI技术的不断进步,我们可以预见,AI将在更多领域发挥其强大的写作能力,提供更加丰富和个性化的文本内容。
5. 对GPT-4模型的猜测和期待
5.1 模型升级的可能性与方向
5.1.1 模型规模与计算效率的平衡
随着技术的持续进步,对于GPT-4模型的猜测和期待主要集中在模型规模的进一步增大和计算效率的显著提高之间的平衡。在模型规模上,更大型的语言模型能够捕捉到更丰富的语言特征和世界知识,但同时也带来了更高的计算成本。因此,GPT-4可能会采取新型的模型压缩技术、更高效的训练算法或更加优化的硬件支持来达到这种平衡。
代码示例(非实际代码,仅作示例用):
# 假设函数来优化模型规模与计算效率的平衡
def optimize_model_efficiency(model, hardware_info):
"""
此函数代表一个优化过程,将大型模型与硬件信息进行匹配优化。
"""
# 模型压缩技术应用
model.apply_compression_techniques()
# 训练效率优化算法
model.apply_efficiency_optimized_algorithms()
# 针对硬件优化模型权重和结构
model.match_to_hardware(hardware_info)
return model
# 假定硬件信息
hardware_info = {
"GPU_count": 4,
"GPU_memory": 16,
"CPU_cores": 16,
"storage_speed": 5000,
}
# 调用优化函数
optimized_model = optimize_model_efficiency(model, hardware_info)
5.1.2 任务泛化能力与知识整合
GPT-4模型的另一个期待方向是增强任务泛化能力以及跨领域的知识整合。现有的大语言模型在面对特定领域或复杂任务时仍有局限性。为了解决这一问题,GPT-4可能会使用更先进的知识整合技术,例如引入外部知识库、图网络或者跨领域预训练方法。这将使模型能更好地理解并处理各种不同类型的输入,提供更准确的输出。
代码示例(非实际代码,仅作示例用):
# 假设函数用于整合跨领域知识
def integrate_cross_domain_knowledge(model, knowledge_base):
"""
此函数代表知识整合过程,将外部知识库信息与模型进行整合。
"""
# 对知识库进行处理和编码
encoded_knowledge = process_knowledge_base(knowledge_base)
# 整合知识到模型中
model.integrate_knowledge(encoded_knowledge)
return model
# 假定知识库
knowledge_base = {
"domain_1": {"facts": ["fact_1", "fact_2"], "relations": [["fact_1", "fact_2"], ["fact_3", "fact_4"]]},
"domain_2": {"facts": ["fact_5", "fact_6"], "relations": [["fact_5", "fact_6"], ["fact_7", "fact_8"]]},
}
# 调用知识整合函数
knowledge_integrated_model = integrate_cross_domain_knowledge(optimized_model, knowledge_base)
5.2 行业对未来AI写作的期待
5.2.1 AI创作与版权法律的挑战
AI写作技术的快速进步,特别是对于GPT-4这样的先进模型,将可能对现有的版权法律提出新的挑战。内容创作的自动化引发了对原创性和版权归属的讨论,因为机器生成的内容很难界定其创作权。因此,行业对于GPT-4的期待之一是它能带来关于AI创作与版权法律的讨论和解决方案,或者在模型设计中加入相应的机制以避免潜在的法律问题。
5.2.2 人机协作的新模式探索
随着GPT-4的期待进一步提升AI写作能力,探索人机协作的新模式将成为行业的重要课题。期望GPT-4能够更好地理解人类用户的需求,与人进行更自然的交互,并提供创造性的辅助。同时,期待GPT-4能够促进人机协作效率,使得人类创作者能够更加专注于创新和创意的提炼,而不是耗费时间在细节性的文字工作上。
6. AIGC的含义、发展及其伴随的问题
随着人工智能技术的飞速发展,AIGC(人工智能生成内容)已成为一个日益受到关注的领域。AIGC不仅代表了一种新兴的内容创造方式,也意味着我们对内容的生产、分发和消费的方式将发生根本性的变化。
6.1 AIGC(人工智能生成内容)的概念框架
6.1.1 AIGC的技术基础与实现路径
AIGC依赖于多种技术的融合,包括自然语言处理(NLP)、机器学习(ML)、深度学习(DL)等。这些技术共同构成了AIGC的基础,使其能够模仿人类创作过程,生成多样化的文本、图像、音频和视频内容。
具体来说,自然语言生成(NLG)是AIGC的关键组成部分之一。NLG技术使计算机能够根据给定的数据自动生成自然语言文本。这通常包括从简单的模板填写到复杂的文本生成,涵盖了从数据报告到创意写作等多个领域。
深度学习技术,尤其是基于Transformer架构的模型,如GPT系列,在AIGC的文本生成方面取得了显著进展。这些模型能够理解语言的复杂性和上下文,并生成连贯、有逻辑的内容。
实现路径上,AIGC的发展分为几个阶段: 1. 基础模型训练:通过大量的数据对模型进行训练,让模型学习语言的基础规律。 2. 特定领域的微调:在特定领域或任务上进行模型微调,以提高生成内容的质量和相关性。 3. 应用开发:构建各种应用程序和工具,通过AIGC技术为用户提供服务。
6.1.2 AIGC的市场趋势与商业价值
AIGC的市场正处于快速增长阶段。根据相关研究报告,AIGC市场预计将从2020年的约100亿美元增长到2027年的近400亿美元。市场增长的驱动力包括内容需求的不断上升、数字营销的普及以及实时内容生成技术的发展。
商业价值方面,AIGC可以帮助企业以较低成本快速生成大量个性化内容。例如,电商平台可以利用AIGC技术生成商品描述、营销邮件以及客户支持对话等。新闻机构可以使用AIGC来快速生成基于数据分析的报道。
6.2 AIGC面临的技术与伦理问题
6.2.1 机器偏见与内容真实性
尽管AIGC技术取得了显著的进步,但它也带来了一系列技术挑战和伦理问题。机器偏见是其中的一个重要问题。由于训练数据可能存在偏见,生成的AIGC内容也可能携带并放大这些偏见,从而影响公平性和多样性。
内容真实性是另一个需要关注的问题。AIGC可以生成高度逼真的假新闻、虚假信息,这对社会的信任基础构成威胁。因此,内容验证机制的开发和部署变得尤为重要。
6.2.2 人机协作中的角色定位
随着AIGC技术的普及,人机协作成为未来工作的常态。这种协作模式要求重新定义人类和机器在内容创作过程中的角色和责任。人类应该作为监督者和创意指导,确保AIGC生成的内容质量与准确性,而机器则发挥其自动化和高效性的优势。
同时,教育和培训体系需要更新,以培养工作者与AI协作的能力。例如,新闻工作者除了学习传统的写作技能外,还需要掌握如何利用AIGC工具生成新闻报道的技巧。
AIGC正处于一个充满挑战和机遇的十字路口。正确地解决伴随其发展而来的技术和伦理问题,将帮助我们更好地利用AI技术为社会创造价值。
7. GPT-3与AI写作工具的集成与使用体验
7.1 GPT-3集成到现有AI写作工具的方法
在深入探讨GPT-3集成到AI写作工具的过程中,首先需要了解的是如何通过API将模型能力引入到写作软件中。GPT-3的API提供了一种简单但强大的方法来整合模型到应用程序中,我们可以通过以下步骤来实现:
- 注册并获取GPT-3的API密钥。
- 阅读官方文档,了解API调用方式和参数设置。
- 在应用程序中集成API,通常需要使用HTTP客户端库。
- 实现一个函数,用来调用API并接收返回的数据。
- 对API返回的数据进行解析和格式化,以便在写作工具中使用。
下面是一个简单的Python代码示例,展示了如何使用 requests 库调用GPT-3的API:
import requests
def get_gpt3_response(prompt, api_key):
url = "***"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
data = {
"prompt": prompt,
"max_tokens": 100,
"temperature": 0.7,
}
response = requests.post(url, headers=headers, json=data)
return response.json()
api_key = "YOUR_API_KEY"
prompt = "Write a short story about AI in the future."
response = get_gpt3_response(prompt, api_key)
print(response["choices"][0]["text"])
在这个例子中, prompt 是一个输入参数,可以是一个简单的问题或者更复杂的文本段落,用来引导模型生成回答。API密钥是必需的,以便让OpenAI的服务知道谁在发起请求。
7.2 使用集成的GPT-3进行AI写作的体验
在成功将GPT-3集成到AI写作工具后,接下来可以体验模型的创作能力。通过以下步骤可以进行:
- 启动写作工具,并创建一个新的写作项目。
- 输入一个初始的写作提示或主题,例如“如何成为一名优秀的软件开发者”。
- 选择GPT-3作为生成内容的引擎。
- 调整生成参数,如生成长度、温度设置等。
- 启动生成过程,并观察AI写作工具如何根据你的提示提供文本。
GPT-3生成的文本通常需要一些后期的编辑和调整,以确保符合写作的风格和精确度要求。尽管如此,它在很多时候能够提供高质量的初稿,特别适合处理那些需要丰富背景知识或创造性的写作任务。
下面是一个用户体验的流程图,展示了集成GPT-3后的使用流程:
graph LR
A[启动写作工具] --> B[输入写作提示]
B --> C[选择GPT-3引擎]
C --> D[调整生成参数]
D --> E[生成文本]
E --> F[编辑和调整生成文本]
使用集成GPT-3的AI写作工具可以极大提高内容创作者的工作效率,特别是在需要大量创意写作或信息整合的场景。然而,创作者也需要对生成内容进行细致的校对和润色,以确保最终作品的质量符合标准。
简介:OpenAI研发的GPT-3模型,尤其是其Davinci版本,代表了自然语言处理领域的重大突破,具有1750亿参数,提升了AI在理解和生成语言的能力。GPT-3的Davinci版本以顶级性能著称,在多种语言任务中表现卓越。它不仅丰富了AI在创意写作和内容生成的应用,还激发了人们对下一代GPT-4模型的期待。AIGC的未来充满潜力,同时也带来了伦理和版权上的挑战。















 9103
9103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









