






一、group by 子句
group by 字句可对数据进行分组。
以MySQL5.5的sakila数据库中的film数据表举例:查找出各个电影等级的电影总数
mysql>SELECT rating, COUNT(*) AS ratingCount FROMfilm> GROUP BY rating
结果如下:
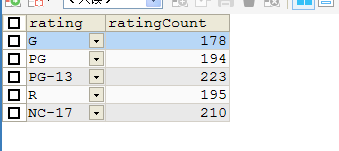
可以看出,group by 子句对其后接的字段进行了分组,而这里也用了聚集函数count()对各分组中的项目数进行统计。
二、聚集函数
由上例可以知道,聚集函数是对某个分组的所有行执行特定的操作。下面介绍一些通用的聚集函数:
MAX() : 返回集合中的最大值
MIN() :返回集合中的最小值
AVG() : 返回集合中的平均值
SUM() : 返回集合所有值之和
COUNT() : 返回集合的总条数
还是以film 数据表举例:注:length字段在数据表中代表电影时长
mysql> select max(length),-> min(length),-> avg(length),-> sum(length),-> count(*)-> from film;
结果以下

聚集函数可以创建参数表达式,可以根据需要任意增加复杂度,只需要保证最后返回一个数字、字符串或日期即可。
三、聚集函数对null值的处理
sum()、avg()、max()函数都会忽略分组集合中的null值。需要注意,count(字段)是对分组集合中的个数统计,会忽略null,而count(*)表示统计分组集合的行数,不会忽略null。
四、having 子句
先看例子:查找出各个电影等级的电影总数且总数大于200
mysql> SELECT rating, COUNT(*) AS ratingCount FROMfilm-> GROUP BYrating-> WHERE ratingCount>200;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that -- 报错
corresponds to your MySQL server version for the right syntax to use near 'WHERE
ratingCount>200' at line 3
查询的where 子句中不能包含聚集函数,这是因为where 子句是在分组前执行的,服务器此时还不能对分组执行任何函数。因此,可用having 子句使用聚集函数进行过滤数据
mysql> select rating, count(*) as ratingCount fromfilm-> group byrating-> having ratingCount>200;+--------+-------------+
| rating | ratingCount |
+--------+-------------+
| PG-13 | 223 |
| NC-17 | 210 |
+--------+-------------+
2 rows in set (0.00 sec)
五、分组查询中的where 和 having
当在包含group by子句的查询中增加过滤条件时,需要考虑过滤是针对原始数据(此时过滤条件应放在where 子句中),还是针对分组后的数据(此时过滤条件应放到having 子句中)。















 972
972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









