






系统高可用/容灾,是系统运维人员非常关心的一个话题。
基于AWS云平台的数据库,我们能做哪些高可用的架构设计呢?
目前中国区,有北京和宁夏两个独立的Region。关于RDS,不仅能做到Multi-AZ的设置,同时AWS还支持RDS的跨Region主从同步。
今天,我们就讨论基于Mysql的高可用/容灾架构的性能测试。
1. 创建Replica Slave

2. 这里我们可以选择将Replica slave创建到“北京region”或者“宁夏region”。
3. 由于北京和宁夏的距离因素,大家都会关心北京Master和宁夏Replica的同步,会不会因为网络延时,而导致lag较大?
今天我就进行测试,看看网络延迟,会对主从同步有多大影响。
(注: 北京region和宁夏region是没有直接连通的,也就是说,客户的EC2或者其他服务的跨Region数据同步,都只能通过公网,或者自己准备的专线方式传输数据。但是AWS内部,会为RDS的主从同步,以及S3 的 Cross Region Replication功能提供专用的线路,并且针对每个account提供一定的带宽)
测试环境准备,
<1. EC2 m4.xlarge (4CPU 16G)
<2. RDS db.r4.xlarge (4CPU 16G ) Mysql版本5.7.12
<3. 创建两个replica,一个在宁夏,一个在北京,主要是为了比较同步情况,确认和区分网络因素的差异
<4. Mysql创建20个表,每个表1000W行数据,数据量在40G左右
<5. 主库使用sysbench进行压力测试 ,sysbench使用方法参考:
https://blog.51cto.com/hsbxxl/2068181
<6. 主库的参数修改
binlog_format=row
<7. 从库的下面参数设置,利用5.7的relay work的并发性能
slave_parallel_workers=50
4. sysbench脚本通过定时任务,执行sysbench脚本,每5分钟执行一次
# crontab -l
*/5 * * * * /root/test.sh
每次执行150s,50个session并发读写20个表,每个表1000W行数据
# cat test.sh
date >> sync.log
sysbench /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua \
--mysql-host=bjs.cbchwkqr6lfg.rds.cn-north-1.amazonaws.com.cn --mysql-port=3306 \
--mysql-user=admin --mysql-password=admin123 --mysql-db=testdb2 --oltp-tables-count=20 \
--oltp-table-size=10000000 --report-interval=10 --rand-init=on --max-requests=0 \
--oltp-read-only=off --time=150 --threads=50 \
run >> sync.log
5. 在主库上,sysbench测试数据输出如下,可以根据输出,确定主库的读写数据,进行参考:[ 10s ] thds: 50 tps: 1072.24 qps: 21505.53 (r/w/o: 15060.08/4296.37/2149.08) lat (ms,95%): 89.16 err/s: 0.00 reconn/s: 0.00
[ 20s ] thds: 50 tps: 759.83 qps: 15195.04 (r/w/o: 10640.78/3034.21/1520.05) lat (ms,95%): 215.44 err/s: 0.00 reconn/s: 0.00
[ 30s ] thds: 50 tps: 631.10 qps: 12645.47 (r/w/o: 8853.55/2529.71/1262.21) lat (ms,95%): 262.64 err/s: 0.00 reconn/s: 0.00
......
[ 130s ] thds: 50 tps: 765.94 qps: 15295.77 (r/w/o: 10701.91/3062.27/1531.59) lat (ms,95%): 125.52 err/s: 0.00 reconn/s: 0.00
[ 140s ] thds: 50 tps: 690.08 qps: 13776.96 (r/w/o: 9636.39/2761.41/1379.16) lat (ms,95%): 150.29 err/s: 0.00 reconn/s: 0.00
[ 150s ] thds: 50 tps: 749.51 qps: 15033.64 (r/w/o: 10532.97/3000.45/1500.22) lat (ms,95%): 147.61 err/s: 0.00 reconn/s: 0.00
SQL statistics:
queries performed:
read: 1458030
write: 416580
other: 208290
total: 2082900
transactions: 104145 (689.50 per sec.)
queries: 2082900 (13790.04 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 151.0422s
total number of events: 104145
Latency (ms):
min: 8.92
avg: 72.39
max: 7270.55
95th percentile: 167.44
sum: 7538949.20
Threads fairness:
events (avg/stddev): 2082.9000/18.44
execution time (avg/stddev): 150.7790/0.44
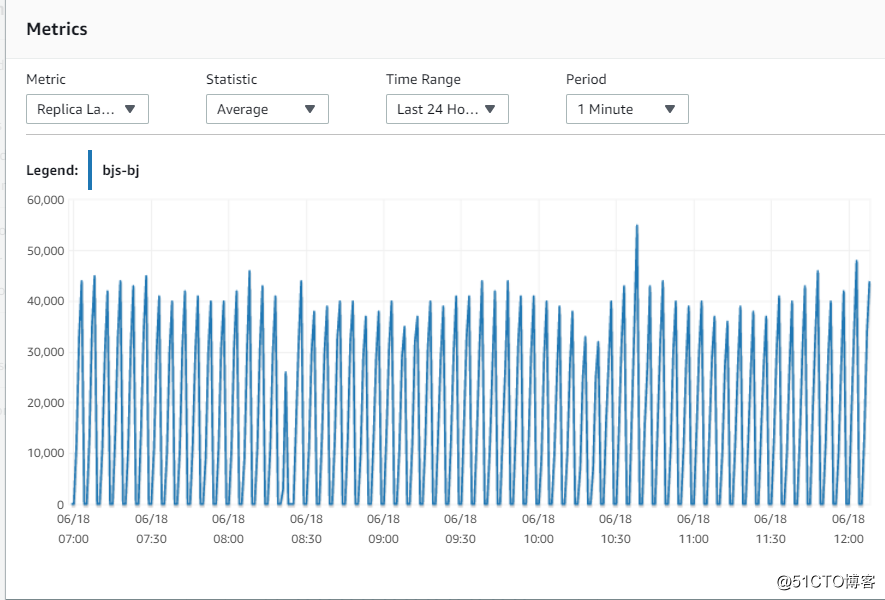
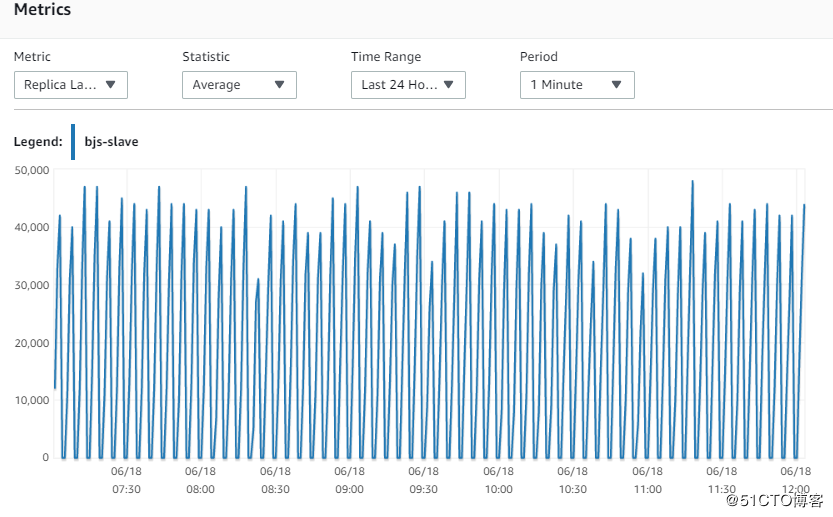
现在我们一起看一下,在北京和宁夏的两个replica的同步情况
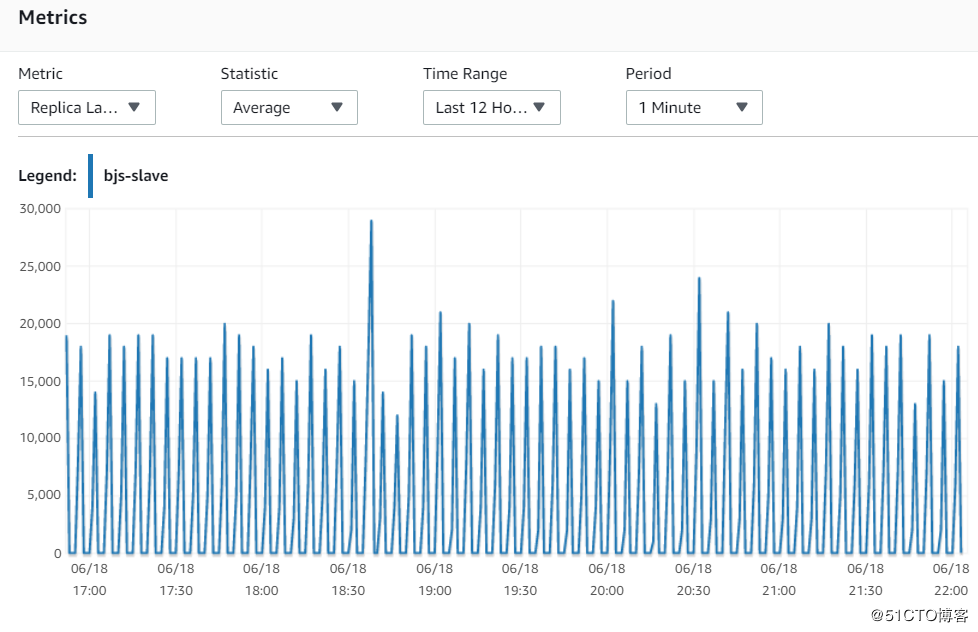
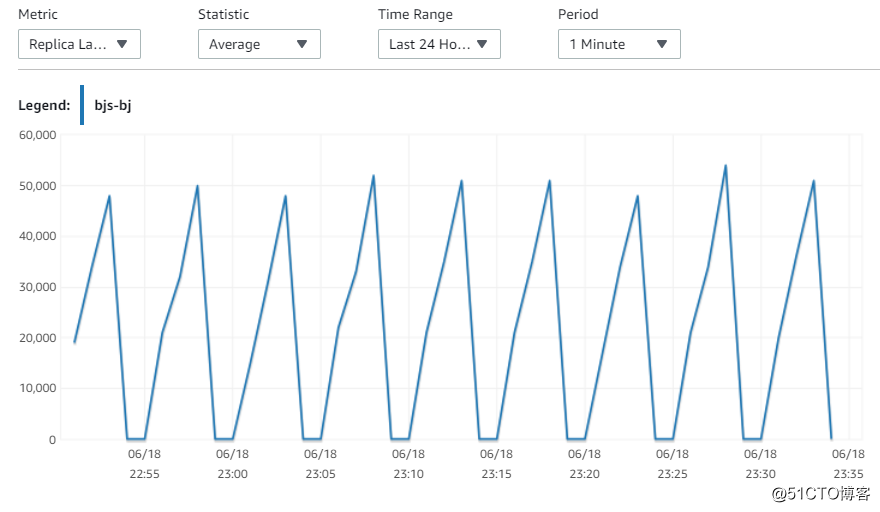
6. 指标Replica Lag (Milliseconds)
可以看到,北京和宁夏的replica的同步性能基本是一致的,在每个150s的写周期,都会有lag的上升,基本延迟在40~50s左右。这说明,网络不是瓶颈,因为北京的replica和Master在同一个AZ的同一个subnet。
北京
宁夏
7. 根据上图结果可以分析,主从的延迟,在Mysql自身replay的过程没有跟上导致的延迟。
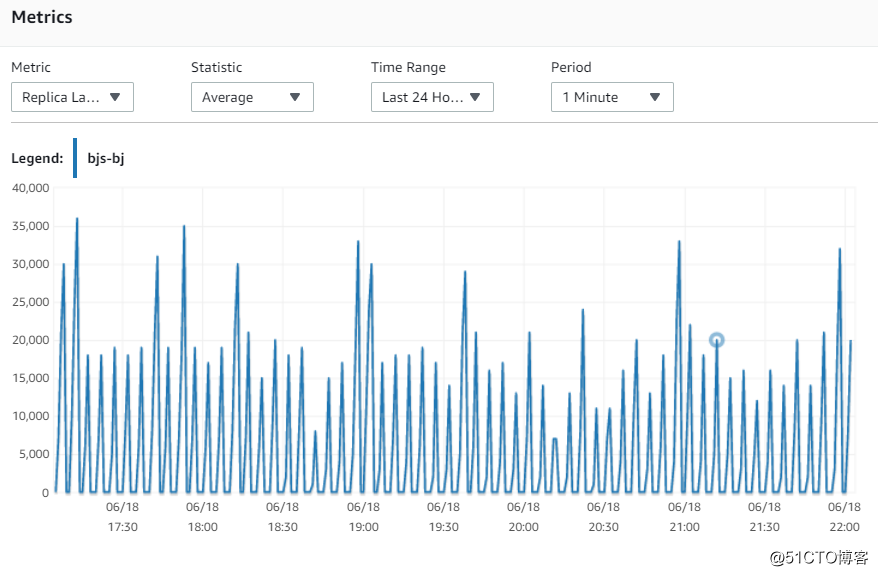
那么,我将两个replica的RDS机型升级到 8CPU 32G,进行测试,并比较结果。
可以看到,升级机型,还是有帮助的,lag明显下降不少,将延迟维持在20~30S
北京
宁夏
也保持和北京相同的lag,更说明了,网络不是同步的瓶颈。Mysql自身replay log,是一个性能瓶颈。
8. 再观察CPU的使用率
由于两个replica只有同步数据的负载,所以可以看到,同步数据的性能消耗,只有15%
后面的曲线是在我升级到8CPU 32G之后,只有7.5%的负载。说明硬件资源是足够的,但是Mysql自身的原因导致同步lag。
北京
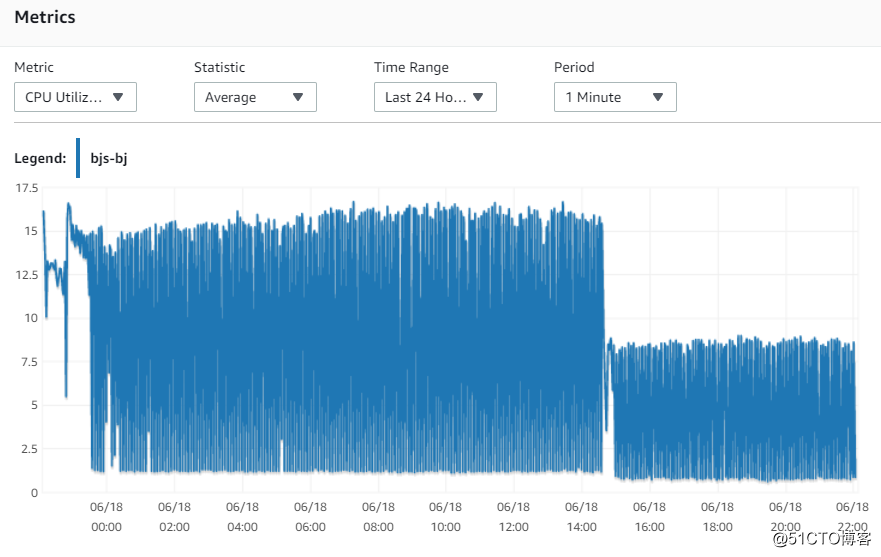
宁夏
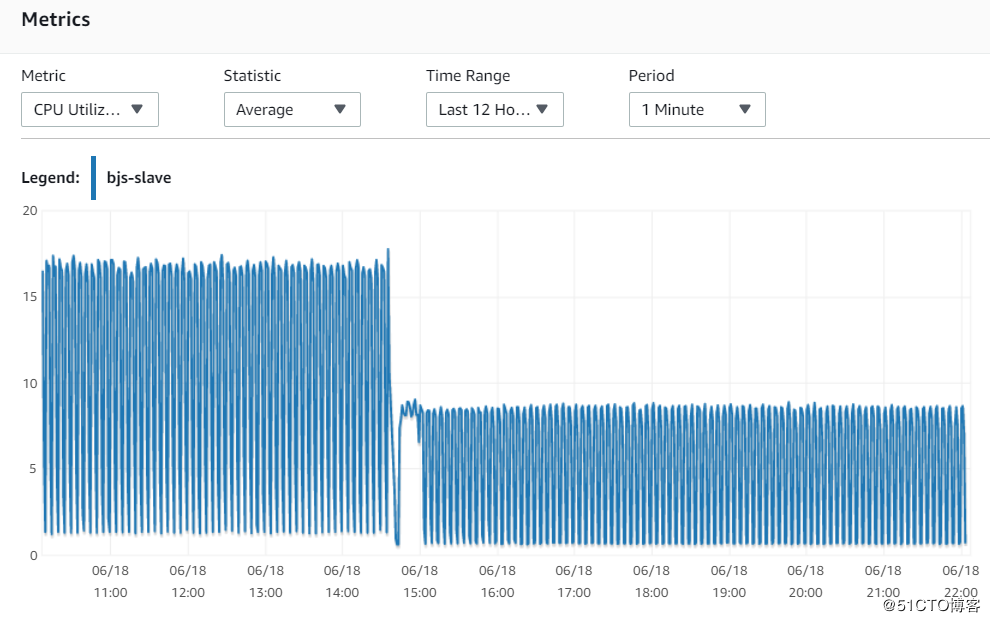
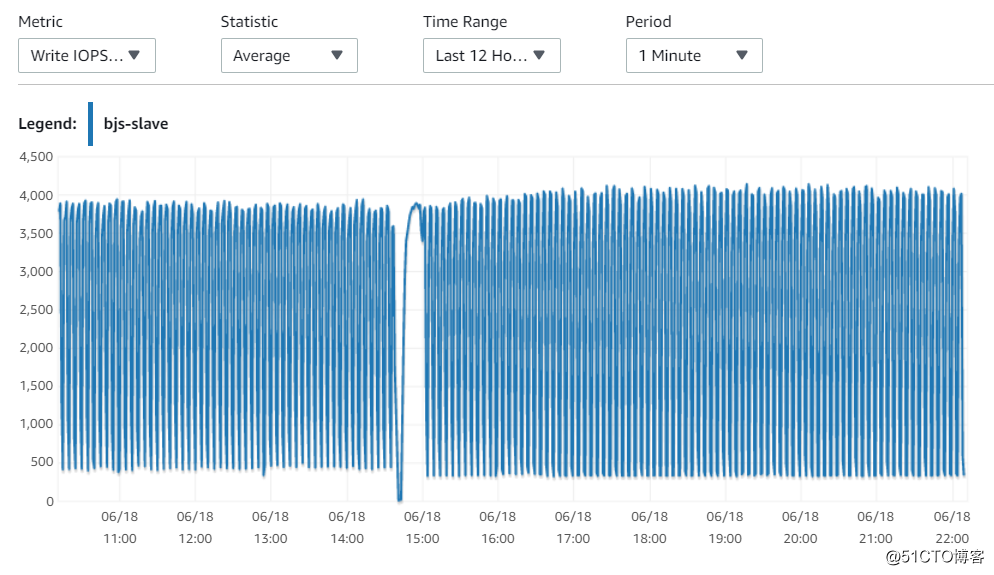
9. Write IOPS
稳定在4000左右,我实际分配的IOPS是6000,所以磁盘也不是瓶颈。另外,主库能完成读写操作,理论上从库只有写操作,负载更低。物理硬件资源不会是限制。
北京
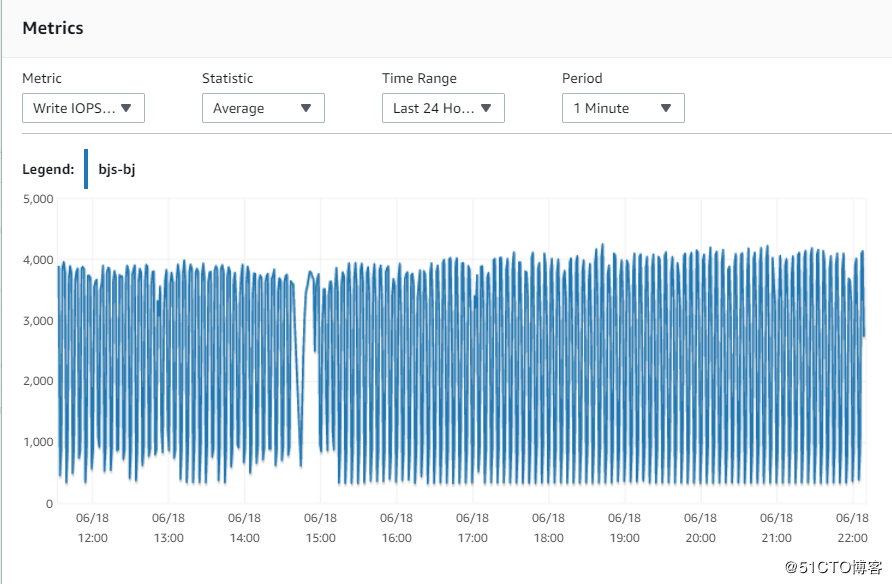
宁夏
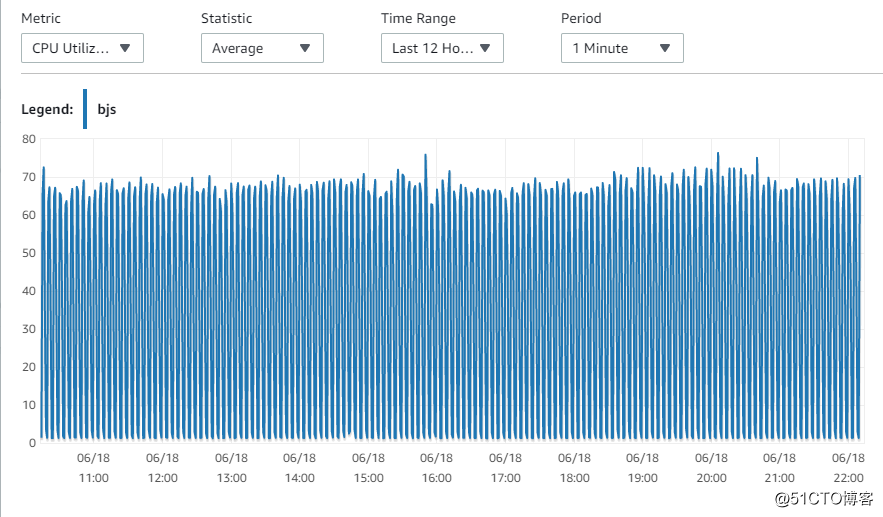
10. 主库的性能指标,可以看到,同样的配置,主库的资源还是够用的。能满足读和写的需求。
CPU性能指标
11. Write IOPS性能指标

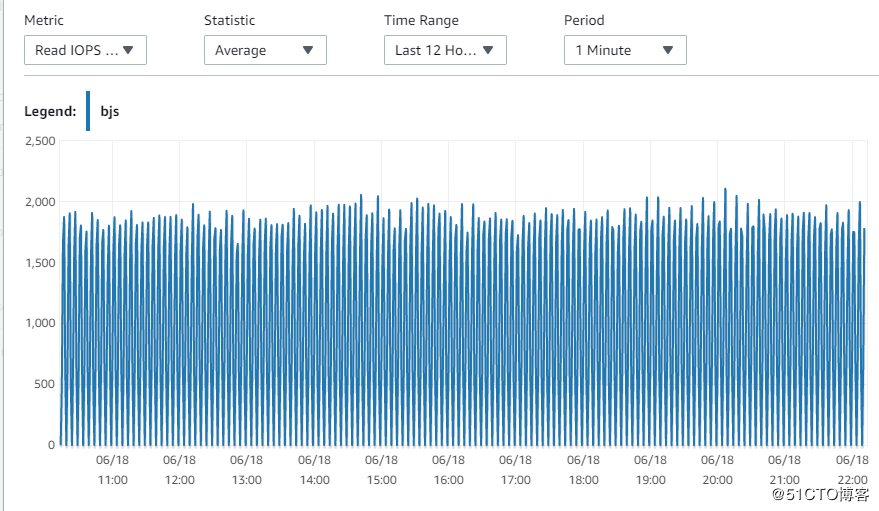
12. Read IOPS性能指标
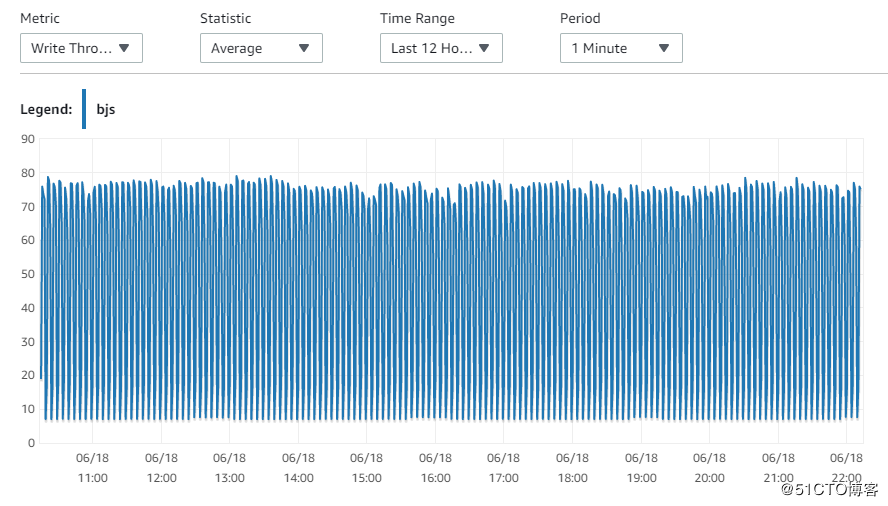
13. Write throughput性能指标
14. 既然数据库主机资源,和网络不是瓶颈。那么Mysql自身的问题,就需要我们去逐步调整了。
接下来,针对mysql的参数进行调整优化。
说是优化,是尽量降低备库相关参数的影响,将IO相关的参数基本全部关闭,去跟随OS层面的机制进行落盘。
实际上,replica的数据安全性要求相对主库要小很多,所以,在从库同步速度较慢的时候,结合实际情况,调整下面参数,会有显著的效果。innodb_flush_log_at_trx_commit=0
innodb_flush_neighbors=0
innodb_flush_sync=0
sync_binlog=0
sync_relay_log=0
slave_parallel_workers=50
master-info-repository = TABLE
relay-log-info-repository = TABLE
15. 调优之后的结果
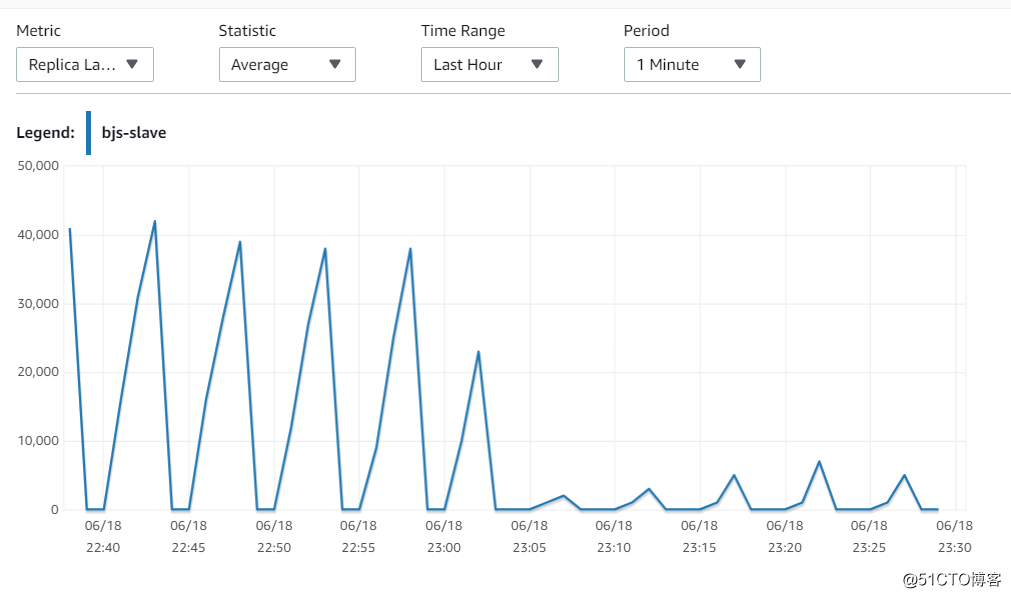
宁夏
在调整完参数之后,效果立竿见影,从40s的延迟,降低到 5s左右
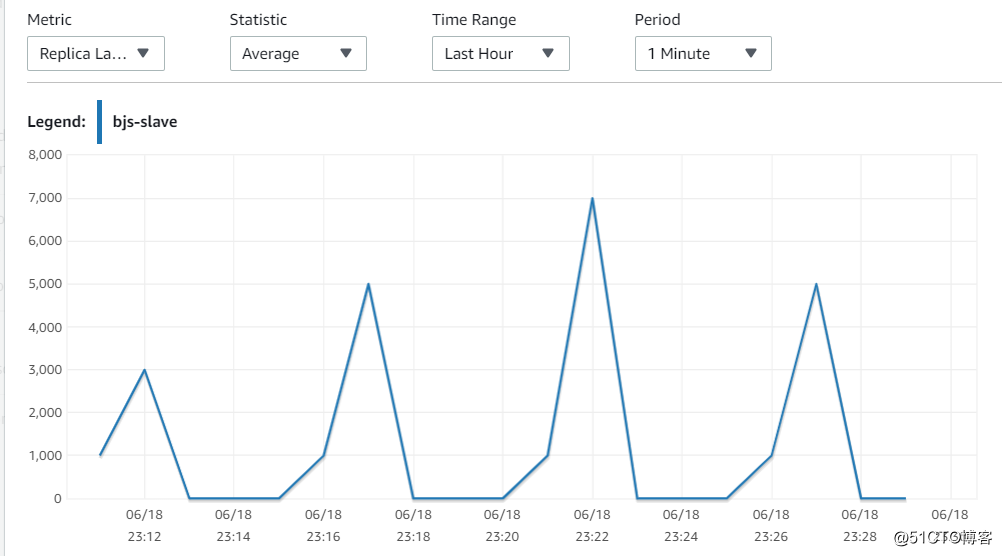
16. 再观察一下北京区的replica(未调整Mysql参数)
依然还是维持之前的lag,保持在50s的延迟情况。
北京
17. 最后再调整一个参数,让worker并行.默认情况下,这个参数是database,也就是只有在多个database被修改的情况下,worker才会并行工作。而实际情况下,大部分客户都是一个database(schema)多个tables的情况。所以,将参数修改成LOGICAL_CLOCK,才能起到并行的作用。slave_parallel_type=LOGICAL_CLOCK
当worker并行之后,已经能够将主从延迟降低到2S以内了,基本能满足绝大部分业务场景了。

18. 测试总结
基于以下条件
硬件:4CPU 16G内存 6000IOPS磁盘
50个并发,每秒700个TPS,1.5W个QPS,1W个写,的情况下。
北京到宁夏的Mysql主从,能控制在10S以内的延迟。
如果对于replica的数据安全性要求比较高,即不调整Mysql落盘的参数情况下,延迟在40~50s范围。
根据实际情况,大家可以通过调整mysql参数,加大replica机型的方式,来获取更好的同步性能。
Mysql作为一个开源RDBMS,虽然在Oracle的技术支持下,有了很大的进步。但是replica的种种性能,和Oracle的Dataguard的同步相比,还是有很大的差距。
后续我会继续研究,如何能让Mysql同步的更快。
19. 关于Mysql主从同步的调优:
<1. MySQL数据库主从同步延迟原理。
答:谈到MySQL数据库主从同步延迟原理,得从mysql的数据库主从复制原理说起,mysql的主从复制都是单线程的操作,主库对所有DDL和 DML产生binlog,binlog是顺序写,所以效率很高,slave的Slave_IO_Running线程到主库取日志,效率很比较高,下一步, 问题来了,slave的Slave_SQL_Running线程将主库的DDL和DML操作在slave实施。DML和DDL的IO操作是随即的,不是顺 序的,成本高很多,还可能可slave上的其他查询产生lock争用,由于Slave_SQL_Running也是单线程的,所以一个DDL卡主了,需要 执行10分钟,那么所有之后的DDL会等待这个DDL执行完才会继续执行,这就导致了延时。有朋友会问:“主库上那个相同的DDL也需要执行10分,为什 么slave会延时?”,答案是master可以并发,Slave_SQL_Running线程却不可以。
<2. MySQL数据库主从同步延迟是怎么产生的。
答:当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能承受的范围,那么延时就产生了,当然还有就是可能与slave的大型query语句产生了锁等待。
<3. MySQL数据库主从同步延迟解决方案
答:最简单的减少slave同步延时的方案就是在架构上做优化,尽量让主库的DDL快速执行。还有就是主库是写,对数据安全性较高,比如 sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog也 可以设置为0来提高sql的执行效率。另外就是使用比主库更好的硬件设备作为slave。
参考文档:















 581
581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









