







输出雷军的名言(利用特殊字符编码输出特殊符号 chr)
# *_* coding: UTF-8 *_* # 开发团队:明日科技 # 明日学院网站:www.mingrisoft.com # 1.1 输出雷军的名言 #方法一:利用特殊字符编码输出特殊符号 print(' ',chr(9477)*27,' ') print(chr(9479),' '*4,'天道不一定酬勤,深度思考比勤奋工作更重要!',' '*4,chr(9479)) print(' ',chr(9477)*27,' ') #方法二:使用搜狗输入法工具箱中的符号大全输出特殊符号(制表符) print(" ┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅") print("┇ 天道不一定酬勤,深度思考比勤奋工作更重要! ┇") print(" ┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅")

输出中英文版的“时间不等人” (使用 print )
# *_* coding: UTF-8 *_* # 开发团队:明日科技 # 明日学院网站:www.mingrisoft.com # 1.2 输出中英文版的“时间不等人” print("╔═════════════════════╗") print("║ 时间不等人。 ║") print("║ Time and tide wait for no man. ║") print("╚═════════════════════╝")

可复制的字符:(使用*15)
# *_* coding: UTF-8 *_* # 开发团队:明日科技 # 明日学院网站:www.mingrisoft.com # 1.4 哪来直接登顶的人生,只有不断迭代的历程 print("& "*15) print("& &") print("& 哪来直接登顶的人生 &") print("& 只有不断迭代的历程 &") print("& &") print("& "*15)

print可换行:(使用\n)
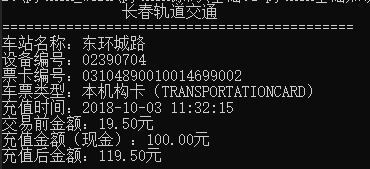
# *_* coding: UTF-8 *_* # 开发团队:明日科技 # 明日学院网站:www.mingrisoft.com # 1.9 输出轨道交通充值信息 print(" 长春轨道交通\n" "============================================\n" "车站名称:东环城路\n" "设备编号:02390704\n" "票卡编号:03104890010014699002\n" "车票类型:本机构卡(TRANSPORTATIONCARD)\n" "充值时间:2018-10-03 11:32:15\n" "交易前金额:19.50元\n" "充值金额(现金):100.00元\n" "充值后金额:119.50元\n")
输出特殊符号♠ ♣ ♥ ♦ (使用chr)
# *_* coding: UTF-8 *_* # 开发团队:明日科技 # 明日学院网站:www.mingrisoft.com # 1.16 输出特殊符号♠ ♣ ♥ ♦ print(chr(9824),chr(9827),chr(9829),chr(9830))
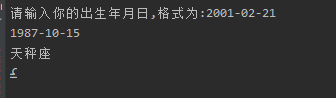
判断星座:(使用split)
sdate=[20,19,21,20,21,22,23,23,23,24,23,22] # 星座判断列表 conts =['摩羯座','水瓶座','双鱼座','白羊座','金牛座','双子座','巨蟹座','狮子座','处女座','天秤座','天蝎座','射手座','摩羯座'] signs=['♑','♒','♓','♈','♉','♊','♋','♌','♍','♎','♏','♐','♑'] # 输入生日,输出星座 birth = input('请输入你的出生年月日,格式为:2001-02-21\n').strip(' ') cbir=birth.split('-') # 分割年月日到列表 cmonth=str(cbir[1]) # 提取月数据 cdate=str(cbir[2]) # 提取日数据 def sign(cmonth,cdate): # 判断星座函数 if int(cdate)<sdate[int(cmonth)-1]: # 如果日数据早于对应月列表中对应的日期 print(conts[int(cmonth)-1]) # 直接输出星座列表对应月对应的星座 print(signs[int(cmonth)-1]) # 直接输出星座列表对应月对应的星座 else: print(conts[int(cmonth)]) # 否则输出星座列表下一月对应的星座 print(signs[int(cmonth)]) # 否则输出星座列表下一月对应的星座 sign(cmonth,cdate) # 调用星座判断程序
猜数字游戏:
list=[['小米手环4',209],['荣耀手环5',199],['华为手环B5',849],['ZNNCO智能血压手环',379]] order=0 price =0 print("数字猜谜游戏!") print('可以竞猜的商品如下:\n','1',list[0][0],'\n 2',list[1][0],'\n 3',list[2][0],'\n 4',list[3][0]) number = input("请输入竞猜商品前面的数字:") # 竞猜价格 if number.isdigit() ==True: order=int(number) if order<4 and order>0 : print("您选择的竞猜商品是:",list[order-1][0]) price=list[order-1][1] guess = -1 while guess != price: guess = input("请输入竞猜价格(只能输入整数价格):") if guess.isdigit() ==True: guess=int(guess) if guess == price: print("恭喜,你猜对了!") elif guess < price: print("猜的价格小了...") elif guess > price: print("猜的价格大了...") else: print("输入价格非法,请重新输入!")

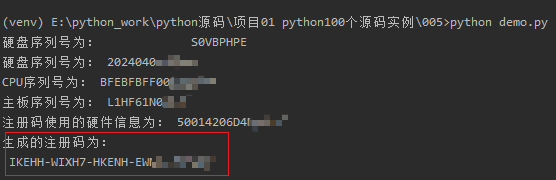
生成基于当前操作系统和设备的注册码:
import wmi import random import os sec="t95p0q2f6dz1cxmowgjensr7yh384bvualki" dec="dn7vhlk3wx1efsyc56zu2bomjtq8i0g4rp9a" c = wmi.WMI() for physical_disk in c.Win32_DiskDrive(): hard_seral=physical_disk.SerialNumber # 获取硬盘序列号 print("硬盘序列号为:",hard_seral) if len(hard_seral)>6: hard_seral=hard_seral[-6:] else: print("硬盘信息获取错误!") os.exit(0) for cpu in c.Win32_Processor(): cpu_seral=cpu.ProcessorId.strip() # 获取CPU序列号 print("CPU序列号为:",cpu_seral) if len(cpu_seral)>4: cpu_seral=cpu_seral[-4:] else: print("CPU信息获取错误!") os.exit(0) for board_id in c.Win32_BaseBoard(): board_id=board_id.SerialNumber # 获取主板序列号 print("主板序列号为:",board_id) if len(board_id)>6: board_id=board_id[-5:] else: print("主板信息获取错误!") os.exit(0) seral=hard_seral+cpu_seral+board_id print("注册码使用的硬件信息为:",seral) cha_seral="" for i in range(0,14,2): cha_seral+=seral[14-i]+seral[i+1] # 字符串尾和首递进连接生成新的字符串 cha_seral=cha_seral+ seral[7] # 字符串的中间值放到新字符串最后 list_seral=list(cha_seral) # 字符串转为列表 list_seral.reverse() # 列表反转 rand_seral="" for i in range(10): # 将前10个字符串和其位置索引(16进制)连接 j=random.randint(1,len(list_seral)) rand_seral+=hex(j)[2:]+list_seral[j-1] # hex(j)[2:] ,去掉16进制前的符号0x list_seral.remove(list_seral[j-1]) rand_seral=''.join(list_seral) +rand_seral # 形成25位的字符串 low_seral="" rand_seral=rand_seral.lower() for item in rand_seral: j=sec.index(item) low_seral+=dec[j] low_seral=low_seral.upper() last_seral=low_seral[0:5]+"-"+low_seral[5:10]+"-"+low_seral[10:15]+"-"+low_seral[15:20]+"-"+low_seral[20:25] print("生成的注册码为:\n",last_seral)
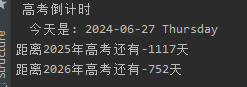
写一个倒计时:
import datetime print(" 高考倒计时 " ) now = datetime.datetime.today() # 获取当前日期 print(" 今天是:", now.strftime("%Y-%m-%d %A ")) time1 = datetime.datetime(2021,6,7) # 2021年高考日期 time2 = datetime.datetime(2022,6,7) # 2022年高考日期 print("距离2025年高考还有" + str((time1-now).days) +"天") print("距离2026年高考还有" + str((time2-now).days) +"天")
根据身份证号判断省份 生日和性别:
dic={'11':'北京市','12':'天津市','13':'河北省','14':'山西省','15':'内蒙古自治区','22':'吉林省','23':'黑龙江省','31':'上海市', '32':'江苏省','33':'浙江省','35':'福建省','36':'江西省','37':'山东省','41':'河南省','42':'湖北省','44':'广东省','45':'广西壮族自治区','46':'海南省','50':'重庆市','51':'四川省','53':'云南省','54':'西藏自治区','61':'陕西省','62':'甘肃省','63':'青海省','65':'新疆维吾尔自治区','71':'台湾省','81':'香港','82':'澳门' } def idget(str): newstr='' if dic.get(str): newstr=dic[str] return newstr instr=input('请输入您的身份证号:\n') if instr[:16].isdigit()and len(instr) == 18: print('你来自:',idget(instr[0:2])) print('你的生日是:' + instr[6:10] + '年' +instr [10:12] + '月' + instr[12:14] + '日') gender = '女' if int(instr[16]) % 2 == 0 else '男' print('你的性别是:' + gender )
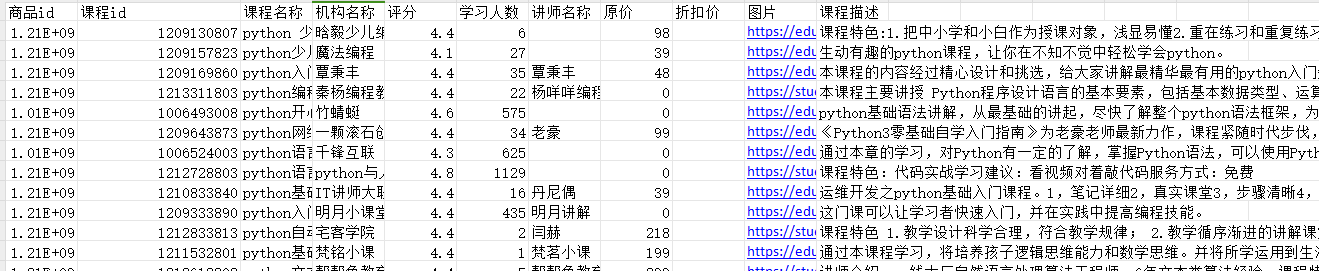
post一个url 并且保存Excel:(爬取网易云课堂教程并且保存Excel)
import requests import xlsxwriter def get_json(index): # 爬虫功能 url = "https://study.163.com/p/search/studycourse.json" payload = { "activityId": 0, "keyword": "python", "orderType": 5, "pageIndex": index, "pageSize": 50, "priceType": -1, "qualityType": 0, "relativeOffset": 0, "searchTimeType": -1, } headers = { "accept": "application/json", "content-type": "application/json", "origin": "https://study.163.com", "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36" } try: response = requests.post(url,json=payload,headers=headers) content = response.json() if content and content["code"] == 0: return content return None except: print("出错了") def get_course(content): course_list = content["result"]["list"] return course_list def save_excel(course_list): # 填充爬取的课程信息 # page1 行数 1 50 50*(1-1) + 1 # page2 行数 51 100 50*(2-1) + 1 # page3 行数 101 150 50*(3-1) + 1 for num,course in enumerate(course_list): row = 50*(index-1)+ num+1 worksheet.write(row, 0, course["productId"]) worksheet.write(row, 1, course["courseId"]) worksheet.write(row, 2, course["productName"]) worksheet.write(row, 3, course["provider"]) worksheet.write(row, 4, course["score"]) worksheet.write(row, 5, course["learnerCount"]) worksheet.write(row, 6, course["lectorName"]) worksheet.write(row, 7, course["originalPrice"]) worksheet.write(row, 8, course["discountPrice"]) worksheet.write(row, 9, course["bigImgUrl"]) worksheet.write(row, 10, course["description"]) def main(index): content = get_json(index) # 获取json数据 course_list = get_course(content) # 获取第index页的50条件记录 save_excel(course_list) # 写入到excel if __name__ == "__main__": # 存入excel workbook = xlsxwriter.Workbook("网易云课堂Python课程数据.xlsx") # 创建excel worksheet = workbook.add_worksheet("first_sheet") worksheet.write(0, 0, "商品id") worksheet.write(0, 1, "课程id") worksheet.write(0, 2, "课程名称") worksheet.write(0, 3, "机构名称") worksheet.write(0, 4, "评分") worksheet.write(0, 5, "学习人数") worksheet.write(0, 6, "讲师名称") worksheet.write(0, 7, "原价") worksheet.write(0, 8, "折扣价") worksheet.write(0, 9, "图片") worksheet.write(0, 10, "课程描述") total_page_count = get_json(1)["result"]["query"]["totlePageCount"] # 总页数 for index in range(1,total_page_count+1): main(index) workbook.close()
post一个url 并且保存MySQL:(爬取网易云课堂教程并且保存MySQL:)
MySQL创建表:
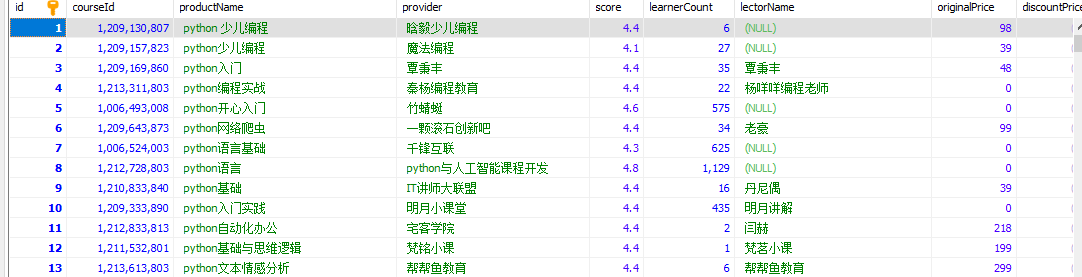
CREATE TABLE course ( id INT AUTO_INCREMENT PRIMARY KEY, courseId INT NOT NULL, productName VARCHAR(255) NOT NULL, provider VARCHAR(255), score FLOAT, learnerCount INT, lectorName VARCHAR(255), originalPrice FLOAT, discountPrice FLOAT, imgUrl VARCHAR(255), bigImgUrl VARCHAR(255), description TEXT ); course安装pip pymsql:
pip install pymysql代码:
import requests import pymysql conn = pymysql.connect( host="localhost", port=3306, user="root", passwd="root", db="test", charset="utf8" ) cur = conn.cursor() def get_json(index): # 爬虫功能 url = "https://study.163.com/p/search/studycourse.json" payload = { "activityId": 0, "keyword": "python", "orderType": 5, "pageIndex": index, "pageSize": 50, "priceType": -1, "qualityType": 0, "relativeOffset": 0, "searchTimeType": -1, } headers = { "accept": "application/json", "content-type": "application/json", "origin": "https://study.163.com", "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36" } try: response = requests.post(url, json=payload, headers=headers) content = response.json() if content and content["code"] == 0: return content return None except: print("出错了") def get_course(content): course_list = content["result"]["list"] return course_list def save_to_mysql(course_list): course_data = [] for item in course_list: course_value = ( 0, item["courseId"], item["productName"], item["provider"], item["score"], item["learnerCount"], item["lectorName"], item["originalPrice"], item["discountPrice"], item["imgUrl"], item["bigImgUrl"], item["description"] ) course_data.append(course_value) string_s = ('%s,' * 12)[:-1] sql_course = f"insert into course values ({string_s})" cur.executemany(sql_course, course_data) def main(index): content = get_json(index) # 获取json数据 course_list = get_course(content) # 获取第index页的50条件记录 save_to_mysql(course_list) # 写入到excel if __name__ == "__main__": print("开始执行") total_page_count = get_json(1)["result"]["query"]["totlePageCount"] # 总页数 for index in range(1, total_page_count + 1): main(index) cur.close() conn.commit() conn.close() print("执行结束")展示:
post url 执行多进程 并且保存到MySQL中:
import requests import time import pymysql from multiprocessing import Pool def get_json(index): """ 爬取课程的Json数据 :param index: 当前索引,从0开始 :return: Json数据 """ url = "https://study.163.com/p/search/studycourse.json" payload = { "activityId": 0, "keyword": "python", "orderType": 5, "pageIndex": index, "pageSize": 50, "priceType": -1, "qualityType": 0, "relativeOffset": 0, "searchTimeType": -1, } headers = { "accept": "application/json", "host": "study.163.com", "content-type": "application/json", "origin": "https://study.163.com", "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36" } try: # 发送POST请求 response = requests.post(url, json=payload, headers=headers) # 获取JSON数据 content_json = response.json() if content_json and content_json["code"] == 0: return content_json return None except Exception as e: print('出错了') print(e) return None def get_content(content_json): """ 获取课程信息列表 :param content_json: 获取的Json格式数据 :return: 课程数据 """ if "result" in content_json: return content_json["result"]["list"] def save_to_course(course_data): """ 保存到course表 :param course_data: 元组数据 :return: None """ # 连接数据库 conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='test', charset='utf8') cur = conn.cursor() sql_course = """INSERT INTO course2 (courseId, productName, provider, score, learnerCount, lessonCount, lectorName, originalPrice, discountPrice, discountRate, imgUrl, bigImgUrl, description) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) """ cur.executemany(sql_course, course_data) conn.commit() cur.close() conn.close() def save_mysql(content): """ 保存到MySQL :param content: 爬取的数据 :return: """ course_data = [] # 连接数据库 conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='test', charset='utf8') cur = conn.cursor() def check_course_exit(course_id): """ 检查课程是否存在 :param course_id: 课程id :return: 课程存在返回True,否则返回False """ sql = f'SELECT courseId FROM course2 WHERE courseId = {course_id}' cur.execute(sql) course = cur.fetchone() return bool(course) # 遍历课程列表 for item in content: if not check_course_exit(item['courseId']): course_value = ( item['courseId'], item['productName'], item['provider'], item['score'], item['learnerCount'], item['lessonCount'], item['lectorName'], item['originalPrice'], item['discountPrice'], item['discountRate'], item['imgUrl'], item['bigImgUrl'], item['description'] ) course_data.append(course_value) cur.close() conn.close() if course_data: save_to_course(course_data) def main(index): content_json = get_json(index) if content_json: content = get_content(content_json) if content: save_mysql(content) if __name__ == '__main__': print('开始执行') start = time.time() totlePageCount = get_json(1)['result']["query"]["totlePageCount"] with Pool() as pool: pool.map(main, range(1, totlePageCount + 1)) print('执行结束') end = time.time() print(f'程序执行时间是{end - start}秒。')
get请求一个页面,并进行HTML解析:(租房网的返回页面解析)
''' 爬取链家网 ''' from fake_useragent import UserAgent # 导入伪造头部信息的模块 import asyncio # 异步io模块 import aiohttp # 异步网络请求模块 import requests # 导入网络请求模块 from lxml import etree # 导入lxml解析html的模块 import pandas # 导入pandas模块 class HomeSpider(): # 链家爬虫的类 def __init__(self): # 初始化 self.data = [] # 创建数据列表 self.headers = {"User-Agent": UserAgent().random} # 随机生成浏览器头部信息 async def request(self, url): # 异步网络请求的方法 async with aiohttp.ClientSession() as session: # 创建异步网络请求对象 try: # 根据传递的地址发送网络请求 async with session.get(url, headers=self.headers, timeout=3) as response: print(response.status) if response.status == 200: # 如果请求码为200说明请求成功 result = await response.text() # 获取请求结果中的文本代码 return result except Exception as e: print(e.args) # 打印异常信息 def get_page_all(self, city): # 请求一次,获取租房信息的所有页码 city_letter = self.get_city_letter(city) # 获取城市对应的字母 url = 'https://{}.lianjia.com/zufang/ab200301001000rco11rt200600000001rs{}/'.format(city_letter, city) response = requests.get(url, headers=self.headers) # 发送网络请求 if response.status_code == 200: html = etree.HTML(response.text) # 创建一个XPath解析对象 # 获取租房信息的所有页码 page_all = html.xpath('//*[@id="content"]/div[1]/div[2]/@data-totalpage')[0] print('租房信息总页码获取成功!') return int(page_all) + 1 else: print('获取租房信息所有页码的请求未成功!') # 解析数据 async def parse_data_all(self, page_all, city): for i in range(1,page_all): # 根据租房信息的总页码,分别对每一页信息发送网络请求 city_letter = self.get_city_letter(city) # 获取城市对应的字母 url = 'https://{}.lianjia.com/zufang/ab200301001000pg{}rco11rt200600000001rs{}/'.format(city_letter,i, city) html_text = await self.request(url) # 发送网络请求,获取html代码 html = etree.HTML(html_text) # 创建一个XPath解析对象 print('获取'+url+'页信息!') title_all = html.xpath('//*[@id="content"]/div[1]/div[1]/div/div/p[1]/a/text()') # 获取每页中所有标题 big_region_all = html.xpath('//*[@id="content"]/div[1]/div[1]/div/div/p[2]/a[1]/text()') # 获取每页中所有大区域 small_region_all = html.xpath('//*[@id="content"]/div[1]/div[1]/div/div/p[2]/a[2]/text()') # 获取每页中所有小区域 square_all = html.xpath('//*[@id="content"]/div[1]/div[1]/div/div/p[2]/text()[5]') # 获取每页中所有房子的面积 floor_all = html.xpath('//*[@id="content"]/div[1]/div[1]/div/div/p[2]/span/text()[2]') # 获取每页中所有房子的楼层 price_all = html.xpath('//*[@id="content"]/div[1]/div[1]/div/div/span/em/text()') # 获取每页中所有房子的价格 title_list = self.remove_spaces(title_all) # 删除标题信息中的空格与换行符 region_list = self.combined_region(big_region_all, small_region_all) # 组合后的区域信息 square_list = self.remove_spaces(square_all) # 删除面积信息中的空格与换行符 floor_list = self.remove_spaces(floor_all) # 删除楼层信息中的空格与换行符 price_list = self.remove_spaces(price_all) # 删除价格信息中的空格与换行符 # 每页数据 data_page = {'title': title_list, 'region': region_list, 'price': price_list, 'square': square_list, 'floor': floor_list} print('写入第'+str(i)+'页数据!') df = pandas.DataFrame(data_page) # 创建DataFrame数据对象 df.to_csv('{}租房信息.csv'.format(city),mode='a', encoding='utf_8_sig',index=None) # 写入每页数据 # 删除字符串中的空格与换行符 def remove_spaces(self, info): info_list = [] # 保存去除空格后的字符串 for i in info: # 循环遍历包含空格信息 x=i.replace(' ', '').replace('\n', '') if x =='': pass else: info_list.append(x) # 将去除空格后的字符串添加至列表中 return info_list # 返回去除空格后的信息 # 获取北、上、广城市名称对应的字母 def get_city_letter(self, city_name): city_dict = {'北京': 'bj', '上海': 'sh', '广州': 'gz'} return city_dict.get(city_name) # 返回城市名称对应的英文字母 # def get_city_letter(self, city_name): # city_dict = {'北京': 'bj', '上海': 'sh', '广州': 'gz','深圳':'sz'} # return city_dict.get(city_name) # 返回城市名称对应的英文字母 # 将大区域小区域合并 def combined_region(self, big_region, small_region): region_list = [] # 保存组合后的区域信息 # 循环遍历大小区域,并将区域组合 for a, b in zip(big_region, small_region): region_list.append(a + '-' + b) return region_list # 启动异步 def start(self, page_all, city): loop = asyncio.get_event_loop() # 创建loop对象 # 开始运行 loop.run_until_complete(self.parse_data_all(page_all, city)) if __name__ == '__main__': input_city = input('请输入需要下载租房信息的城市名称!') home_spider = HomeSpider() # 创建爬虫类对象 page_all = home_spider.get_page_all(input_city) # 获取所有页码 print(page_all) # 打印所有页码信息 home_spider.start(page_all, input_city) # 启动爬虫程序
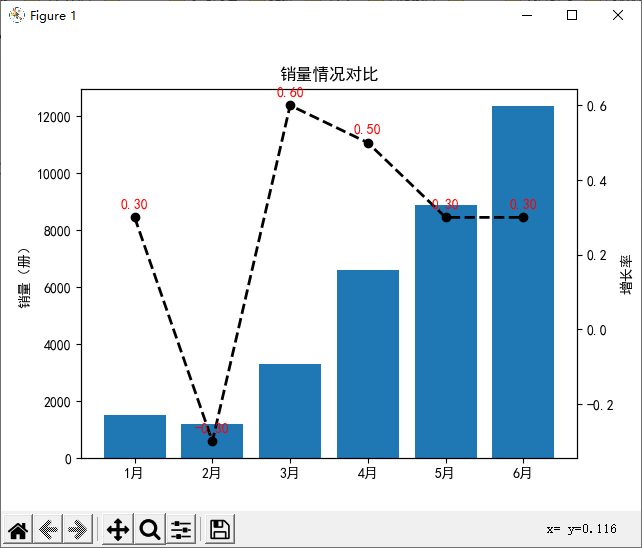
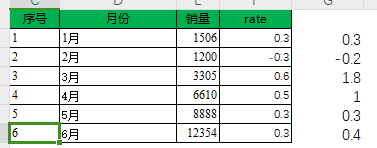
解析Excel并且画一个柱状图:
import pandas as pd import matplotlib.pyplot as plt # 使用 openpyxl 作为引擎来读取 .xlsx 文件 df = pd.read_excel('mrbook.xlsx', engine='openpyxl') # 假设 df 中的 '销量' 和 'rate' 列有相同的行数 y1 = df['销量'] y2 = df['rate'] x = range(1, len(y1) + 1) # 生成与 x 轴刻度数量匹配的标签 months = ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月', '13月', '14月'] # 检查数据长度 print("Length of x:", len(x)) print("Length of y1:", len(y1)) print("Length of y2:", len(y2)) fig = plt.figure() plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 ax1 = fig.add_subplot(111) # 添加子图 plt.title('销量情况对比') # 图表标题 plt.xticks(x, months[:len(x)]) # 图表x轴标题 # 绘制柱状图 ax1.bar(x, y1, label='销量') ax1.set_ylabel('销量(册)') # y轴标签 # 共享x轴添加一条y轴坐标轴 ax2 = ax1.twinx() ax2.plot(x, y2, color='black', linestyle='--', marker='o', linewidth=2, label=u"增长率") ax2.set_ylabel(u"增长率") # 在折线图上添加数据标签 for a, b in zip(x, y2): plt.text(a, b + 0.02, '%.2f' % b, ha='center', va='bottom', fontsize=10, color='red') plt.show()
解析Excel并且生成柱状图:
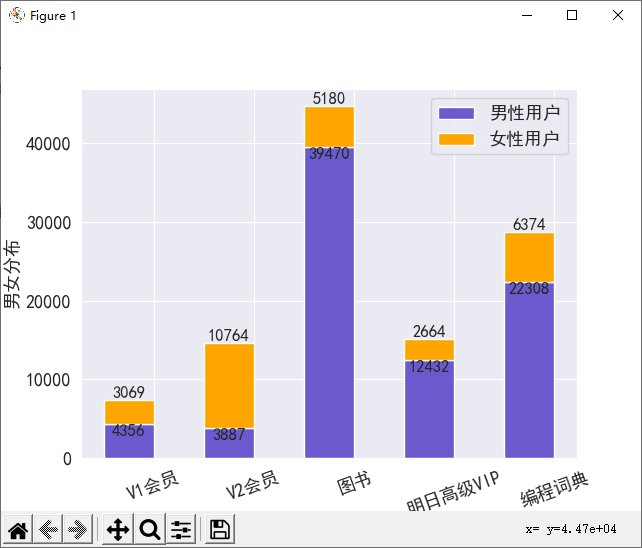
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np sns.set_style('darkgrid') file = './data/mrtb_data.xlsx' df = pd.read_excel(file, engine='openpyxl') plt.rc('font', family='SimHei', size=13) # 通过reset_index()函数将groupby()的分组结果重新设置索引 df1 = df.groupby(['类别'])['买家实际支付金额'].sum() df2 = df.groupby(['类别', '性别'])['买家会员名'].count().reset_index() men_df = df2[df2['性别'] == '男'] women_df = df2[df2['性别'] == '女'] men_list = list(men_df['买家会员名']) women_list = list(women_df['买家会员名']) num = np.array(list(df1)) # 消费金额 # 计算男性用户比例 ratio = np.array(men_list) / (np.array(men_list) + np.array(women_list)) np.set_printoptions(precision=2) # 使用set_printoptions设置输出的精度 # 设置男生女生消费金额 men = num * ratio women = num * (1 - ratio) df3 = df2.drop_duplicates(['类别']) # 去除类别重复的记录 name = list(df3['类别']) # 生成图表 x = name width = 0.5 idx = np.arange(len(x)) plt.bar(idx, men, width, color='slateblue', label='男性用户') plt.bar(idx, women, width, bottom=men, color='orange', label='女性用户') plt.xlabel('消费类别') plt.ylabel('男女分布') plt.xticks(idx + width / 2, x, rotation=20) # 在图表上显示数字 for a, b in zip(idx, men): plt.text(a, b, '%.0f' % b, ha='center', va='top', fontsize=12) # 对齐方式'top', 'bottom', 'center', 'baseline', 'center_baseline' for a, b, c in zip(idx, women, men): plt.text(a, b + c + 0.5, '%.0f' % b, ha='center', va='bottom', fontsize=12) plt.legend() plt.show()
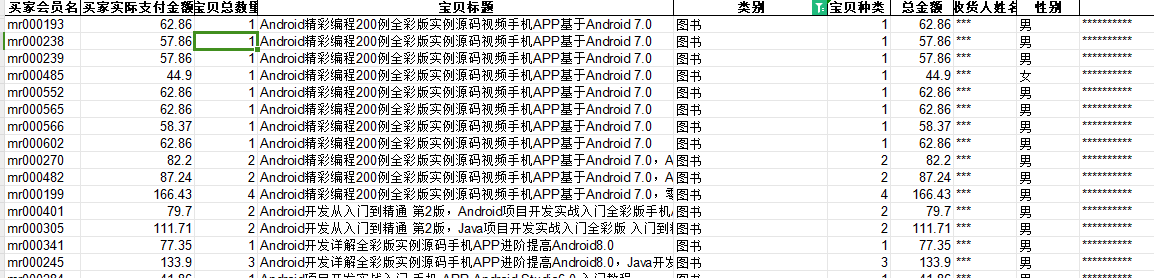
解析txt文本:
import re import matplotlib.pyplot as plt from matplotlib import colors import jieba import wordcloud # 按行读取群聊天记录(文本文件) f = open('qun.txt','r',encoding='utf-8') fl = f.readlines() del fl[:8] #del删除切片(前8行数据) fl = fl[1::3] #提取下标为1,步长为3的切片 str1 = ' '.join(fl) #join()函数分割文本数据 #滤除无用文本 str1 = str1.replace('[QQ红包]请使用新版手机QQ查收红包。','') str1 = str1.replace('[群签到]请使用新版QQ进行查看。','') #通过re模块的findall将[表情]和[图片]转义成字符,然后使用replace滤除 list1 = re.findall(r'\[.+?\]', str1) for item in list1: str1 = str1.replace(item, '') #自定义颜色 color_list=['#CD853F','#DC143C','#00FF7F','#FF6347','#8B008B','#00FFFF','#0000FF','#8B0000','#FF8C00','#1E90FF','#00FF00','#FFD700','#008080','#008B8B','#8A2BE2','#228B22','#FA8072','#808080'] colormap=colors.ListedColormap(color_list) # 分词制作词云图 word_list = jieba.cut(str1, cut_all=True) word = ' '.join(word_list) Mywordcloud= wordcloud.WordCloud(mask=None, font_path='simhei.ttf',width=3000,colormap=colormap,height=2000,background_color = '#383838').generate(word) plt.imshow(Mywordcloud) plt.axis('off') plt.show()
















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









