







本节讲解XGBoost的原理~
目录
1、回顾:
1.1 有监督学习中的相关概念
1.2 回归树概念
1.3 树的优点
2、怎么训练模型:
2.1 案例引入
2.2 XGBoost目标函数求解
3、XGBoost中正则项的显式表达
4、如何生长一棵新的树?
5、xgboost相比原始GBDT的优化:
6、代码参数:
1、回顾:
我们先回顾下有监督学习中的一些核心概念:
1.1 有监督学习中的相关概念
我们模型关注的就是如何在给定xi的情况下获得ŷi。在线性模型里面,我们认为
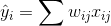
i是x的横坐标,j是x的列坐标,本质上linear/logistic regression中的yi^都等于这个,只不过在logistic regression里面,分了两步,第一步ŷi=∑j wj xij,此时ŷi含义是一个得分,第二步你把这得分再扔到Sigmoid函数里面,才会得到概率。所以预测分值的ŷi在不同的任务中会有不同的解释。对于线性回归(linear regression)来说,ŷi就是最终预测的结果。对于逻辑回归(logistic regression)来讲,把ŷi丢到Sigmoid函数里面去,是预测的概率。在其它的一些模型里面,ŷi还有其它的作用。而在线性模型里面的参数就是一组w,叫做θ。即
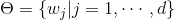
对于参数型模型,要优化的目标函数有两项组成,一项是Loss,一项是Regularization。表达公式即
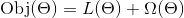
常见的损失函数Loss如:平方误差损失函数(square loss),表示为:
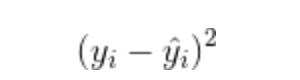
交叉熵损失函数(Logistic loss),表示为
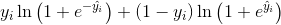
正则项Ωθ是用来衡量模型简单程度的,有L1正则,即
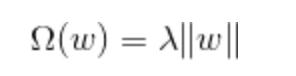
有L2正则即L2范数的平方,乘一个λ。即
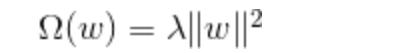
λ是我们要调节的超参数,用来衡量Obj函数到底是更在乎简单程度,还是更在乎在训练集上的经验损失。所谓经验损失就是你在训练集上错了多少就叫经验损失。对于不同的loss和不同的Regularization这两项加合起来,让这两项的和最小,就达到了一个兼顾的目的,所以它们俩都要相对比较小,才是最好的模型效果。如果说为了达到使L(θ)让它下降一点点,而Ωθ上升好多,就代表着过拟合。模型复杂度上升了好多才带来了一点点提升,这种事情并不是我们想要的。我们希望一个简单的模型,能给我一个最好的答案;如果做不到这俩的话,也希望一个相对简单的模型给我一个相对比较好的结果就行了。加法在这里面达到了兼顾的目的。
对于不同的loss和不同的Regularization组合,再对它进行最优化,就构成了我们所谓的不同的算法。
比如对于mse损失函数组合一个L2正则就是岭回归,表达为:
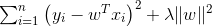
对于mse损失函数组合一个L1正则就是lasso回归,表达为:
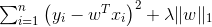
对于Logistic loss交叉熵损失函数组合一个L2正则就叫做逻辑回归,表达为:
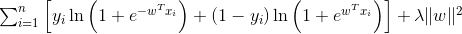
所以逻辑回归的损失函数里必定会带这λw^2这项,没有这项就不能叫做逻辑回归。
1.2 回归树概念
在来回顾下回归树的相关概念,对于回归树(CART树Classification and Regression Trees)来讲,它的决策的分裂条件和决策树是一样的,也是多次尝试分裂,哪次结果最好就留下来。最后它会得到一个叶子节点,也能表达是一个连续的值,我们在此称之为score分数,对于回归树我们得到的是一组分数。比如下面例子:
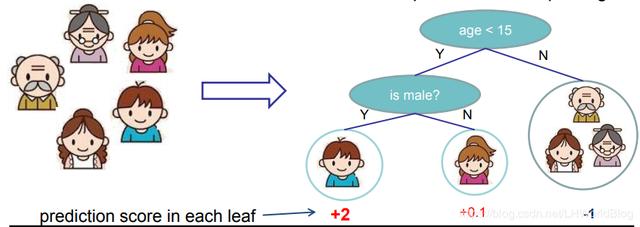
我们要判断这个人是否喜欢电脑游戏,通过一个回归树来训练,年龄小于15的点被分到左边,是否是男的分到左边。所以小男孩最终落到了左边叶子节点,小女孩通过分裂落在了右边叶子节点,而另外三位落到了右边叶子节点。最终通过某种方法,先不用考虑是什么方法,它通过y平均得到了小男孩得分是+2,小女孩+0.1,而另外三位对于计算机游戏的喜好程度是-1,这是一个回归树的形式。
1.3 树的优点
树有这么一个优势,就是inputs对于输入数量的大小,不太在意。做分类,原来最强的霸主是SVM,但它有一个问题就时间复杂度是O(n3)。所以它在小数据集上表现得非常好,代码也跑得起来,但一旦到海量数据集上,它就会变得不可接受。如果一千条数据用十分钟,10万条数据可能就以年来记了。三次方实在太可怕了,这是它最慢的情况,当然它内部也做了一些优化,不是所有情况都会达到O(n3)。但是树的训练基本就是O(n)或者O(n*m),它需要遍历所有的维度,它比O(n3)要scaling了好多,scaling在机器学习领域特指的是小数据量上表现的好不好,在小数据量上能跑的,在大数据量上还跑得起来的这个方面的性能。 这是一个非常重要的特性。树模型最不怕的就是这个东西,它表现的时间复杂度比较稳定。另外它对于数据集的是否归一化,不需要太过在意,参数型模型里y是通过x计算出来的,它们之间有一个等式关系,而对于树一系列的模型来讲,x和y实际上是被割裂开的。x值只用来分裂,跟y值最后的结果没有直接的计算关系,它有间接的关系。y的计算结果是通过落在叶子节点上的其它的y算出来的,而不是通过x算出来。
这里先给大家铺垫下,在xgboost中,第一,它虽然用的是C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









