







这篇应该是你见过的讲xgboost的文章里最细的。
简单介绍
首先需要介绍GBDT,它是一种基于boosting增强策略的加法模型,训练的时候采用前向分布算法进行贪婪的学习,每次迭代都学习一棵CART树来拟合之前 t-1 棵树的预测结果与训练样本真实值的残差。
在核心思想不变的情况下,XGBoost对GBDT进行了一系列优化,主要是损失函数进行了二阶泰勒展开,另外还有目标函数加入正则项、支持并行和默认缺失值处理等,在可扩展性和训练速度上有了巨大的提升。
模型核心思想
- Boosting提升方法
- 使用二阶泰勒展开来近似拟合残差:相对于GBDT的一阶导数,XGBoost采用二阶泰勒展开,可以更为精准的逼近真实的损失函数
- 贪婪方法分裂节点
模型前提设定
训练数据集 D = { ( x i , y i ) } i = 1 n D=\{\left(x_i,y_i\right)\}_{i=1}^{n} D={ (xi,yi)}i=1n,其中 x i ∈ R m , y i ∈ R x_i\in\mathbb{R}^m,y_i\in\mathbb{R} xi∈Rm,yi∈R。又有实例 x x x。
01 - 单棵决策树模型表示方法
假设某棵决策树有 T T T个叶子节点,则单棵决策树模型可记为:
f ( x ) = w q ( x ) f(x)=w_{q(x)} f(x)=wq(x)
其中 q : R m → { 1 , … , T } q:\mathbb{R}^m\to \{1,\dots,T\} q:Rm→{
1,…,T}是由输入 x x x向叶子节点编号的映射,其本质是树的分支结构;而 w ∈ R T w\in\mathbb{R}^T w∈RT是叶子权重向量。
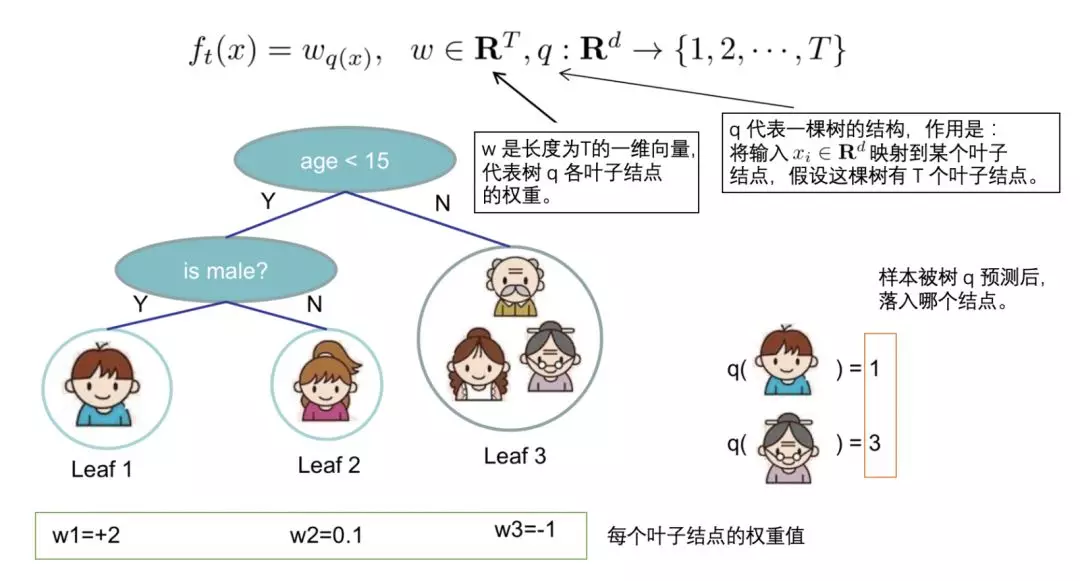
例如实例 x x x 落在了决策树的第 j j j 个节点,则其输出值即为 w j w_j wj 的值。而叶子节点向量即为
w = ( w 1 , ⋯ , w j , ⋯ , w T ) w=(w_1,\cdots,w_j,\cdots,w_T) w=(w1,⋯,wj,⋯,wT)
02 - 加法模型结构
使用 Boosting \text{Boosting} Boosting思想,对于实例 x x x,总模型的预测输出为
y ^ = ϕ ( x ) = ∑ k = 1 K f k ( x ) \hat{y}=\phi\left(x\right)=\sum_{k=1}^K f_k\left(x\right) y^=ϕ(x)=k=1∑Kfk(x)
其中, f k ( x ) f_k\left(x\right) fk(x) 为第 k k k 棵决策树。
核心生成原理
03 - XGBoost的正则化目标函数及其变量解释
X G B o o s t XGBoost XGBoost的正则化目标函数由损失函数和正则化项两部分组成,定义如下:
L = ∑ i = 1 n l ( y i , y ^ i ) + ∑ k = 1 K Ω ( f k ) L=\sum_{i=1}^nl(y_i,\hat y_i)+\sum_{k=1}^K \Omega(f_k) L=i=1∑nl(yi,y^i)+k=1∑KΩ(fk)
以下逐一解释各个参数:
-
l l l表示损失函数。由于模型将使用二阶泰勒展开,因此要求损失函数一阶和二阶可导。常见的损失函数有:
- 用于回归的平方损失函数: l ( y , y ^ ) = ( y − y ^ ) 2 l(y,\hat y)=(y-\hat y)^2 l(y,y^)=(y−y^)2
- 用于分类的逻辑回归损失函数: l ( y , y ^ ) = y ln ( 1 + e − y ^ ) + ( 1 − y ) ln ( 1 + e y ^ ) l(y,\hat y)=y\ln(1+e^{-\hat y})+(1-y)\ln(1+e^{\hat y}) l(y,y^)=yln(1+e−y^)+(1−y)ln(1+ey^)
-
y ^ i \hat y_i y^i表示第 i i i个样本 x i x_i xi的预测值。作为加法模型,预测得分是每棵树打分的累加之和:
y ^ i = ∑ k = 1 K f k ( x i ) , f k ∈ F \hat y_i=\sum_{k=1}^K f_k(x_i),f_k \in \mathcal F y^i=k=1∑Kfk(xi),fk∈F
如上式,此模型中共有 k k k 棵树, f k f_k fk 为第 k k k 棵树的函数(模型)。 -
Ω ( f ) \Omega(f) Ω(f)为单棵数的复杂度。模型将全部 k k k 棵树的复杂度进行求和,添加到目标函数中作为正则化项,以防止模型过拟合:
∑ k = 1 K Ω ( f k ) \sum_{k=1}^K \Omega(f_k) k=1∑KΩ(fk)
04 - 学习第 t t t 棵树
假设在第 t t t 轮,也是生成第 t t t 棵树时,要训练的树模型为 f t f_t ft ,则在第 t t t 轮迭代后,实例 x x x 的预测结果 y ^ ( t ) \hat y^{(t)} y^(t) 为:
y ^ ( t ) = ∑ k = 1 t f k ( x ) = y ^ ( t − 1 ) + f t ( x ) \hat y^{(t)}=\sum_{k=1}^t f_k(x)=\hat y^{(t-1)}+f_t(x) y^(t)=k=1∑tfk(x)=y^(t−1)+ft(x)
公式中 y ^ ( t − 1 ) \hat y^{(t-1)} y^(t−1) 为前 t − 1 t-1 t−1 棵树的预测结果。
注意,在第 t t t 轮迭代时,前 t − 1 t-1 t−1 棵树已知,因此 y ^ ( t − 1 ) \hat y^{(t-1)} y^(t−1) 也是一个已知常量。
将上式代入模型的基本目标函数,得到第 t t t 轮的目标函数为
L ( t ) = ∑ i = 1 n l ( y i , y ^ i ( t ) ) + ∑ k = 1 t Ω ( f k ) = ∑ i = 1 n l ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) + Ω ( f t ) + constant \begin{aligned} L^{(t)} &=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}^{(t)}\right)+\sum_{k=1}^{t} \Omega\left(f_{k}\right) \\ & = \sum_{i=1}^{n} l\left(y_{i}, \hat{y}_{i}^{(t-1)}+f_{t}\left(x_{i}\right)\right)+\Omega\left(f_{t}\right)+\text { constant } \end{aligned} L(t)=i=1∑nl(yi,y^i(t))+k=1∑tΩ(fk
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 150
150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









