









1 构建中文tokenization
参考链接:https://zhuanlan.zhihu.com/p/639144223
1.1 为什么需要 构建中文tokenization?
原始的llama模型对中文的支持不太友好,接下来本文将讲解如何去扩充vocab里面的词以对中文进行token化。
1.2 如何对 原始数据预处理?
每一行为一句或多句话。保存为语料corpus
1.3 如何构建中文的词库?
一般的,目前比较主流的是使用sentencepiece训练中文词库。
运行后会得到tokenizer.model和tokenizer.vocab两个文件。
1.4 如何使用transformers库加载sentencepiece模型?
它可以用transformers库里面的tokenizer对象加载读取。
1.5 如何合并英文词表和中文词表?
将原始词表中没有的新加入进去vocab.model。
for p in chinese_spm.pieces:
piece = p.piece
if piece not in llama_spm_tokens_set:
new_p = sp_pb2_model.ModelProto().SentencePiece()
new_p.piece = piece
new_p.score = 0
llama_spm.pieces.append(new_p)
1.6 怎么使用修改后的词表?
如果我们重新从头开始训练,那么其实使用起来很简单:
config = AutoConfig.from_pretrained(…)
tokenizer = LlamaTokenizer.from_pretrained(…)
model = LlamaForCausalLM.from_pretrained(…, config=config)
model_vocab_size = model.get_output_embeddings().weight.size(0)
model.resize_token_embeddings(len(tokenizer))但是如果我们想要保留原始模型embedding的参数,那么我们可以这么做:
- 找到新词表和旧词表id之间的映射关系。
- 将模型里面新词表里面包含的旧词表用原始模型的embedding替换。
- 如果新词在旧词表里面没有出现就进行相应的初始化再进行赋值。
具体怎么做可以参考一下这个:https://github.com/yangjianxin1/LLMPruner
1.7 总结一下 构建中文tokenization?
1、使用sentencepiece训练一个中文的词表。
2、使用transformers加载sentencepiece模型。
3、怎么合并中英文的词表,并使用transformers使用合并后的词表。
4、在模型中怎么使用新词表。
2 继续预训练篇
2.1 为什么需要进行继续预训练?
我们新增加了一些中文词汇到词表中,这些词汇是没有得到训练的,因此在进行指令微调之前我们要进行预训练。预训练的方式一般都是相同的,简单来说,就是根据上一个字预测下一个字是什么。
2.2 如何对 继续预训练 数据预处理?
先使用tokenizer()得到相关的输入,需要注意的是可能会在文本前后添加特殊的标记,比如bos_token_id和eos_token_id,针对于不同模型的tokneizer可能会不太一样。这里在input_ids前后添加了21134和21133两个标记。
然后将所有文本的input_ids、attention_mask, token_type_ids各自拼接起来(展开后拼接,不是二维数组之间的拼接),再设定一个最大长度block_size,这样得到最终的输入。
2.3 如何 构建模型?
我们可以使用同样的英文原模型,但是tokenizer换成我们新的tokenizer.由于tokenizer词表个数发生了变化,我们需要将模型的嵌入层和lm_head层的词表数目进行重新设置:
model_vocab_size = model.get_output_embeddings().weight.size(0)
model.resize_token_embeddings(len(tokenizer))
2.4 如何 使用模型?
按照transformer基本的使用模型的方法即可。可以用automodel, automodelforcasualLm等方法
3 对预训练模型进行指令微调
3.1 为什么需要对预训练模型进行指令微调?
如果需要模型能够进行相应的下游任务,我们就必须也对模型进行下游任务的指令微调。
只经过上面的继续与训练,模型能够获得基本的知识,但是更加领域的,特别的精细的指令还需要指令微调来获得。
对数据处理到训练、预测的整个流程有所了解,其实,基本上过程是差不多的。我们在选择好一个大语言模型之后。比如chatglm、llama、bloom等,要想使用它,得了解三个方面:输入数据的格式、tokenization、模型的使用方式。
3.2 对预训练模型进行指令微调 数据 如何处理?
指令微调的数据处理和继续与训练的数据处理相同。
需要注意的是根据微调任务不同,
将原本的分类或者预测任务,直接转变为特定单词或者句子的生成任务。并且添加特殊的标记。来区分不同的任务以及不同的结果。
3.3 对预训练模型进行指令微调 tokenization 如何构建?
与与训练的基本一致。
如果有针对某些特殊的字或者语言需要扩充语料库。可以使用保留字符,或者重新进行上面的【构建tokenization】任务
3.4 对预训练模型进行指令微调 模型 如何构建?
使用原有的模型,进行全参数微调。
也可以使用adapter的结构,将模型固定住,只训练少量参数
还可以使用prompt等其他的方式。不进行参数调整。只改变输入数据的信息
3.5 是否可以结合 其他库 使用?
可以
其它的一些就是结合一些库的使用了,比如:
deepspeed
transformers
peft中使用的lora
datasets加载数据
需要注意的是, 我们可以把数据拆分为很多小文件放在一个文件夹下,然后遍历文件夹里面的数据,用datasets加载数据并进行并行处理后保存到磁盘上。如果中间发现处理数据有问题的话要先删除掉保存的处理后的数据,再重新进行处理,否则的话就是直接加载保存的处理好的数据。
在SFT之后其实应该还有对齐这部分,就是对模型的输出进行规范,比如使用奖励模型+基于人类反馈的强化学习等,这里就不作展开了。
4 一个项目介绍怎么搞数据和处理数据
https://github.com/zhanshijinwat/Steel-LLM/tree/main
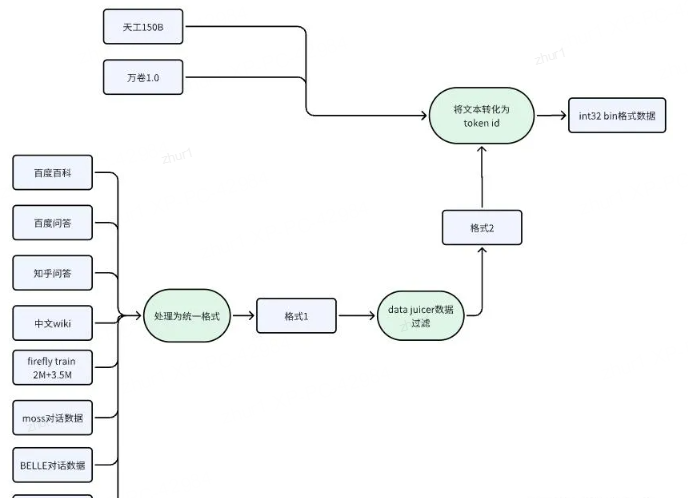
4.1 收集预训练数据&过滤清洗
1.WanjuanCC数据处理
论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2402.19282.pdf
(1) 从Common Crawl的WARC格式数据中提取文本,得到"原始数据"。
(2) 通过启发式规则对原始数据进行过滤,生成"清洗数据"。
(3) 利用基于MinHash( datasketch 库)的去重方法对清洗数据进行处理,得到"无重复数据"。
(4)使用基于关键词和域名列表的过滤方法,以及基于Bert的有害内容分类器和淫秽内容分类器对"无重复数据"进行过滤,产生"安全数据"。
(5)采用基于Bert的广告分类器和流畅性分类器对"安全数据"进行进一步过滤,得到最终的"高质量数据"
2.Dolma数据处理
论文地址:https://arxiv.org/abs/2402.00159
完全开源LLM OLMo的训练数据,论文有83页之多。
(1)语言过滤:使用CCNet的fastText语言试别模型进行语言试别并过滤,目标语言是英语,语言过滤永远不会完美,总会有一些其他语言过滤不掉。
(2)质量过滤:结合处理Gopher数据和 C4数据时的规则来实现质量过滤。
(3)内容过滤:过滤掉"有毒信息"(zz不正确、种族歧视、色情等),同时使用规则(关键词、域名黑名单等)和文本分类器。个人隐私信息使用一系类正则表达式以及用 Jigsaw Toxic Comments训练过的fastText模型进行试别和剔除。
(4)数据去重:结合使用了 URL、文档和段落级重复数据删除,具体技术上使用了布隆过滤器。
3.ziya2数据处理
(1)数据预处理:语言检测筛选英文和中文数据。随后对语料库的编码进行了标准化,并将所有繁体中文文本转换为简体中文文本。在此之后,消除了无意义的标记,例如不可见的控制字符、特殊符号、表情符号等。
(2)语言质量评分:使用中文维基百科和英文维基百科训练KenLM模型,预测语料PPL,判断语料质量好坏。
(3)基于规则过滤:在文档、段落和句子三个层级进行过滤。在文档级别,规则是围绕内容长度和格式设计的。在段落和句子层面,规则的重点转向毒性。
(4)重复文本删除:使用 Bloomfilter 和 Simhash来删除重复文本。
4.总结
(1)目标语言过滤:一些LLM只关注特定语言,可通过语言试别模型筛选。
(2)个人隐私内容:个人隐私相关信息不能让LLM学到,可通过正则表达式检测。
(3)有害内容:种族歧视、zz不正确以及色情信息等,通过域名黑名单、词黑名单,有害性检测分类器检测。
(4)格式正确性:是否包含HTML标记、符号或标点是否使用正确等,通常通过人工定义规则和正则表达式解决。
(5)重复数据:重复数据不仅会浪费计算资源,还会对模型性能产生负面影响。目前的重复数据删除方法主要分为三类:基于URL的匹配、基于字符串的匹配和模糊匹配。
(6)内容的质量:指数据集中的信息能否有效提升模型的性能。可以在小模型上进行训练和评估来判断训练数据的质量。或者,可以使用已知的高质量数据集(如wiki数据)作为正样本,然后训练语言模型或分类器进行评分和过滤。也可规定一些内容质量相关的规则。
4.2 统一格式&过滤& 数据去重
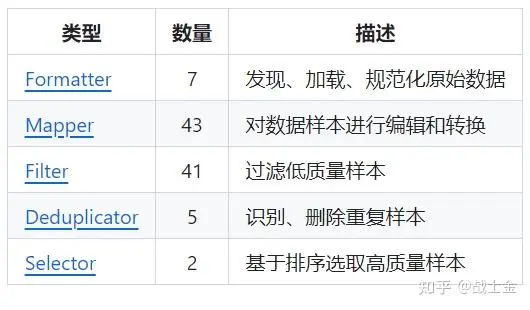
数据过滤使用的是阿里开源的data-juicer工具,是一款一站式的数据处理工具。每个数据处理步骤在data-juicer中抽象为一个算子,用户可以方便的配置yaml文件实现自定义的数据处理流程,其主要提供的算子有如下5大类,用户也可以自定义数据处理的算子。data-juicer处理数据的实现比较暴力,很多算子是用python原生的for循环遍句子中的字,效率不是很高。
那么如何去重呢?首先,你一定要有一个大数据处理集群,hadoop 也好、spark 也罢,只要是一个 map / reduce 的框架就都可以。这个属于汽车的轮子,想要靠 python 写 for 循环完成这个工作,确实是勇气可嘉。然后,就去实现一个简单的 minhash 代码,没啥难度,ChatGPT 一定会写。
数据去重工作有一个比较重要的意识:要先确定需要多少训练数据,再确定去重的粒度。去重工作是没有尽头的,任何时候你都能把数据继续洗下去,所以必须明确自己需要多少训练数据。需要 10T 训练数据,就卡相似度在 80% 的阈值进行去重;需要 5T 的训练数据,就卡相似度在 90% 的阈值进行去重;以此类推。
目前没有任工作能证明,一条数据在 pretrain 阶段训多少遍对模型是最友好的。因此,大胆的按需去重,即使去重粒度小,导致一篇文档出现多次,也可以通过让两篇相似文档之间隔尽量多的 token 来降低影响。
4.3 统一生成token_id
在github项目Steel-LLM/pretrain_modify_from_TinyLlama/scripts/prepare_steel_llm_data.py文件中详细记录
Steel-LLM使用qwen1.5的tokenizer,因此我们也选择遵循qwen的对话模式,需要将moss、BELLE等对话数据转化为qwen对话格式,如下所示。这里有个细节,在处理对话格式数据时,{回答}后边的<|im_end|>在此处是不用加的,因为在后续将文本转换为token id时,会统一在每段完整文本后边加一个<|im_end|>(qwen1.5的终止符(eos_token),为什么要这么做后文会介绍)
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{问题}<|im_end|>
<|im_start|>assistant
{回答}<|im_end|>
天工150B(600GB+)和万卷1.0(1TB+)从技术报告来看相对干净并且数据量比较大,就不再进一步数据过滤,直接转化为token id保存,给训练程序使用。
万卷1.0数据解压前有500g左右,单进程解压需要2小时,解压后大小为1T。万卷1.0数据为jsonl格式,"content"字段存储文本内容。但是有一个文件比较特殊(CN/WebText-cn/part-010669-a894b46e.jsonl)为选择题数据,如下格式所示,需要单独处理,在github项目Steel-LLM/pretrain_modify_from_TinyLlama/scripts/prepare_steel_llm_data.py文件的process_jsonl_file函数中也有所体现。
4.4 数据配比实验
前面提到,我们要在数据清洗的时候把 code 等格式化数据摘出来,怎么实现呢?训练一个数据分类器!对每一个 document 进行类别判断,不用特别精准,把数据划分成新闻、百科、代码、markdown、等类目即可,分类器模型依然可以选择使用 BERT 家族。
不同的数据源,在上文中介绍清洗和去重的时候也要有不同的阈值:
清洗的时候,“代码”和“知识类文本”当然要使用不同的阈值来决定是否是高质量;
去重的时候,“新闻”类可能 70% 的重复度就不要,“知识”类则可以 85% 的相似度才丢弃,在丢去重复文档的时候,优先保留数据打分器比较高的数据。
好了,引子环节说完了,默认大家已经都给自己的数据打好了类别,我们继续往下讲配比工作。
大部分的技术报告里,应该都提及了自己的数据是如何配比的,基本上都是“知识 + 代码 + 逻辑”三个大类目,其中知识数据分文中文知识和英文知识,逻辑数据则可以认为是 math 数据和 cot 数据的混合体。整体上,大部分中文模型的配比都在这个区间左右:中:英:code = 4:4:2(逻辑数据的比例我没有写进去,加入多少取决于你能收集多少,其他三类数据应该是要多少有多少的存在)。
我们可以根据自己的实际情况调整配比,但英文的比例一定不能太低。目前中文数据的质量不如英文数据质量基本已经成功共识,导致这个现象可能有两个原因:
中文确实比英文难学,语言空间的复杂度更高;
中文语料无论是干净程度还是数量级,都无法与英文语料相比较
根据不同的英文,中文数据比例
测试小模型上的指定几个公开指标的好坏,例如,GLEU,CMMLU等几个数据集指标变化
根据比例和自己的任务挑选合适的中英文以及code, math等比例
粗糙一点的工作:在小模型上起多个数据配比、数据顺序,训练 500B 左右的数据量,然后选择 loss 曲线最完美,或者 loss 下降最低的那个模型(这个阶段刷 benchmark 意义不大,模型小,训得少,大概率都是瞎蒙);
专业一点的工作:额外起多个 size 的小模型,跑出 loss 结果,结合 scaling_law 公式,去推算大模型最适合的数据配比、学习率、训练 token 量等参数;
创新一点的工作:像 llama 和 deepseek 技术报告里提到的一样,去绘制出 loss 到 benchmark 的 scaling_law,提前预知模型训多少 token 量能在某个 benchmark 达到什么样的能力。
4.5 数据顺序
pretrain 的本质是一个教模型学知识的过程,既然是学习,那么知识的顺序就显得很重要,总不能先学微积分,再学数字加减法吧。这也就是“课程学习”的核心思想。
课程学习的内容很宽泛,无论是先学难知识、再学脏知识,还是先学好数据、再学脏数据,都可以视为是课程学习。其本质就是在阐述一件事情:“同样 1个T的训练数据,通过调整训练顺序得到的不同模型,能力是不同的。”这个观点基本已经被很多团队论证多次了,因此课程学习目前也可以认为是 pretrain 的标配。
虽然 next_token 的训练方法,基本不存在模型学不会某条数据的情况。但从另外一个角度来分析,灾难性遗忘可能始终在发生,A + B 的学习顺序可能导致 A 知识遗忘了 30%,B + A 的学习顺序可能导致 B 知识遗忘了 20%,那后者忘得少自然能力更强啊。而且,如果 B 是一个简单的知识,那就代表 B 在训练语料中会出现非常多的次数,即使遗忘了后续也会被重新捡起来,困难知识在全部训练数据中出现的次数自然也会小很多。(全局训练语料中,蜀道难全文出现的次数一定比静夜思全文出现的次数少)。
说了这么多,只是为了强调一件事:数据顺序真的很重要,那么如何敲定呢?
这里我推荐的 llama 的 In context pretrain 工作:利用语义相似度,优先将最相似的 document 进行拼接,从而构成语义更加连贯流畅的上下文,详见论文 https://arxiv.org/pdf/2310.10638。
需要强调的一个地方是,llama 坚定的认为:在同一条 pretrain 语料中,无关文档之间不能相互看见。具体来说,sentenceA + “” + sentenceB 这样一条训练语料,llama 认为 sentenceB 看不见 sentenceA 非常重要且效果很好,它在这篇论文和 llama3.1 技术报告中均有提及。
但在实操中,除了 llama,我没听说过还有哪个团队在 pretrain 阶段做 attention_mask,大家的实验结论基本都是做不做 mask 没什么区别。而且,我个人认为,pretrain 阶段应该要培养模型切换 topic 的能力,在 llm 的实际应用场景中,我们也不会每切换一个新话题,就起一个新的聊天窗口,模型需要有判断上文信息和当前信息是否相关的能力。因此,如果使用了 In context pretrain 这篇工作的论文,要不要做 attention_mask 还是要做实验去斟酌的。
4.6 Tokenizer, 模型结构,模型参数
详细见:LLM训练全细节 | 如何从零到一进行 pretrain 工作
训练 loss 分析
pretrain 训练环节中,最最最最最重要的中间产出,就是 tensorboard 的那条 loss 曲线。记住几条:
- 一定要有 channel_loss,至少,中文知识,英文知识,代码这三类数据的 loss 得分开观察;
- loss_spike 不可忽视,虽然目前还没有工作去证明说 loss_spike 会对模型造成不可逆的效果伤害,但不出现 losst_spike 总是好的啊。无论是 loss 突然激增还是激减,都要重点留意,大概率是数据问题(脏数据不仅 loss 高,也会 loss 低,全是乱码的数据 loss 很高,全是换行符的数据 loss 很低)。如果数据过脏,就回退到上个 checkpoint 进行训练;
- 即使数据没有问题,也是有可能出现 loss_spike 的,这时候要留意下数据的 grad 有没有异常,大概率和优化器有关,参考 llama 等的技术报告,好好调整 adamw 优化器的 这两个参数,基本上能解决大部分训练初期的 loss_spkie 问题。一旦熬过了训练初期,loss 平稳下降到了 2 ~3 左右,后续的训练也基本不会再有幺蛾子了。
训练流程
pretrain 训练流程目前基本是固定的,当训练数据和训练代码都准备就绪后,按照以下四个流程来设置学习率和超参数就可以啦:
- 开局 warmup,学习率缓慢上升到最大;
- 中间 cos / cos_decay / constant / constant_decay ,学习率比较大,是否 decay 自己决定,多翻翻别人的技术报告,或者在小模型上做实验决定;
- 后期改变 rope base + seq_len,开始让模型适应长文本;
- 收尾 anneal,用高精数据、IFT数据等来给强化模型的考试能力,做完退火就该上考场刷 benchmark 了。
- 一般 pretrain 只要启动了,大家就可以去做别的工作了,只要模型训练没停,一般都不需要再有人为干预。烧卡了, loss 爆炸了,loss陡然下降了(数据大概率重复了),就回退到上一个 checkpoint 重启。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









