







http://blog.csdn.net/jasonzzj/article/details/52017438
1、逻辑回归的概念阐述
首先,逻辑回归是一种分类(Classification)算法。应用场景有:
1.给定一封邮件,判断是不是垃圾邮件
2.给出一个交易明细数据,判断这个交易是否是欺诈交易
3.给出一个肿瘤检查的结果数据,判断这个肿瘤是否为恶性肿瘤
逻辑回归是互联网上最流行也是最有影响力的分类算法,也是深度学习(Deep Learning)的基本组成单元。
2、逻辑回归模型介绍
逻辑回归又称为对数几率函数(logistic function,对数几率函数是一种“Sigmoid函数”,它将z值转化为一个接近0或1的y值,
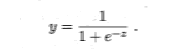
将Z=w^T*x+b带入方差,得到下面结果:
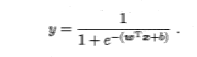
进一步变化,可得如下式,其中ln(y/1-y),“对数几率”(log odds,亦称logit)
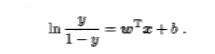
y视为类后验概率估计p(y=1|x)可重写为
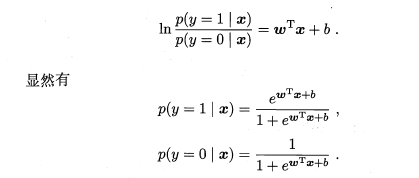
当真实样本标签 y = 0 或者为1时,概率等式转化为:
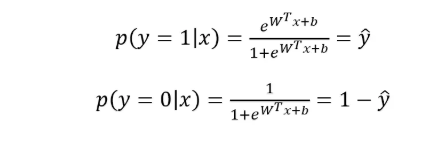
从极大似然性的角度出发,把上面两种情况整合到一起:
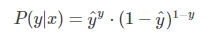
希望概率 P(y|x) 越大越好。我们对 P(y|x) 引入 log 函数,因为 log 运算并不会影响函数本身的单调性
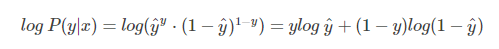
概率 P(y|x) 越大越好,等价于 -log P(y|x) 越小就越好。因此引入损失函数,且令 Loss = -log P(y|x)即可。则得到损失函数为:
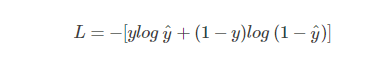
3.交叉熵损失函数
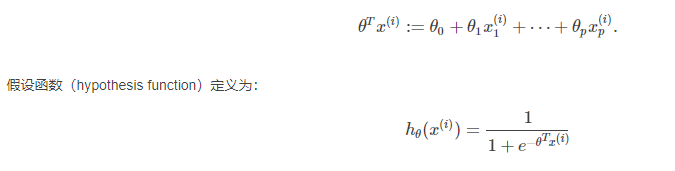


4、逻辑回归模型案例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris #导入数据集iris
from sklearn.utils import shuffle
class logistic_regression():
def __init__(self):
pass
#先定义一个 sigmoid 函数:
def sigmoid(self,x):
z = 1 / (1 + np.exp(-x))
return z
#定义模型参数初始化函数,w为dims行一列的array:
def initialize_params(self,dims):
W = np.zeros((dims, 1))
b = 0
return W, b
#定义逻辑回归模型主体部分,包括模型计算公式、损失函数和参数的梯度公式:
def logistic(self,X, y, W, b):
num_train = X.shape[0]
#sigmoid 函数
a = self.sigmoid(np.dot(X, W) + b)
#逻辑函数的交叉熵损失函数
cost = -1/num_train * np.sum(y*np.log(a) + (1-y)*np.log(1-a))
#w的偏导
dW = np.dot(X.T, (a-y))/num_train
db = np.sum(a-y)/num_train
# 从数组的形状中删除单维条目,即把shape中为1的维度去掉
cost = np.squeeze(cost)
return a, cost, dW, db
# 定义基于梯度下降的参数更新训练过程:
def logistic_train(self,X, y, learning_rate, loop_max,epsilon=0.001):
w, b = self.initialize_params(X.shape[1])
error = np.zeros(X.shape[1]+1)
loss_list = []
flag = 0
i=0
while flag == 0 and i< loop_max:
# 计算当前预测值、损失和参数偏导
y_hat, loss, dw, db = self.logistic(X, y, w, b)
loss_list.append(loss)
# 基于梯度下降的参数更新过程.
w += -learning_rate * dw
b += -learning_rate * db
# 打印迭代次数和损失
if i % 10000 == 0:
print('loop_max %d loss %f' % (i, loss))
# 保存参数
params = {
'w': w,
'b': b
}
# 保存梯度
grads = {
'dw': dw,
'db': db
}
# 判断是否已收敛
w_new=np.insert(w,X.shape[1], values=b, axis=0)
if np.linalg.norm(w_new- error) < epsilon:
flag = 1
else:
error = w_new
i += 1
print ('loop count = %d' % i, '\tw:',w)
return loss_list, params, grads
#定义对测试数据的预测函数:
def predict(self,X, params):
y_prediction = self.sigmoid(np.dot(X, params['w']) + params['b'])
for i in range(len(y_prediction)):
if y_prediction[i] > 0.5:
y_prediction[i] = 1
else:
y_prediction[i] = 0
return y_prediction
#使用 sklearn 生成模拟的二分类数据集进行模型训练和测试:
def accuracy(self, y_test, y_pred):
correct_count = (y_test==y_pred).sum()
accuracy_score = correct_count / len(y_test)
return accuracy_score
def create_data(self):
iris = load_iris() #载入数据集
datas = iris.data
#数据集前面50个类标位0,中间50个类标位1,后面为2
X = [x[0] for x in datas]
Y = [x[1] for x in datas]
plt.scatter(X[:50], Y[:50], color='red', marker='o', label='setosa') #前50个样本
plt.scatter(X[50:100], Y[50:100], color='blue', marker='x', label='versicolor') #中间50个
plt.scatter(X[100:], Y[100:],color='green', marker='+', label='Virginica') #后50个样本
plt.legend(loc=2) #左上角
plt.show()
X = iris.data[:100, :2] #获取花卉两列数据集
labels = iris.target[:100]
X, labels = shuffle(X, labels, random_state=13)
X = X.astype(np.float32)
offset = int(X.shape[0] * 0.8)
X_train, y_train = X[:offset], labels[:offset]
X_test, y_test = X[offset:], labels[offset:]
y_train = y_train.reshape((-1,1))
y_test = y_test.reshape((-1,1))
print('X_train=', X_train.shape)
print('X_test=', X_test.shape)
print('y_train=', y_train.shape)
print('y_test=', y_test.shape)
return X_train, y_train, X_test, y_test
#最后我们定义个绘制模型决策边界的图形函数对训练结果进行可视化展示:
def plot_logistic(self,X_train, y_train, params):
n = X_train.shape[0]
xcord1 = []
ycord1 = []
xcord2 = []
ycord2 = []
for i in range(n):
if y_train[i] == 1:
xcord1.append(X_train[i][0])
ycord1.append(X_train[i][1])
else:
xcord2.append(X_train[i][0])
ycord2.append(X_train[i][1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1,s=32, c='red')
ax.scatter(xcord2, ycord2, s=32, c='green')
x = np.arange(4, 7, 0.1)
y = (-params['b'] - params['w'][0] * x) / params['w'][1]
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
if __name__ == "__main__":
model = logistic_regression()
X_train, y_train, X_test, y_test =model.create_data()
#对训练集进行训练:
cost_list, params, grads = model.logistic_train(X_train, y_train, learning_rate=0.005, loop_max=5000)
#对测试集数据进行预测:
y_prediction = model.predict(X_test, params)
print(y_prediction)
#定义一个分类准确率函数对训练集和测试集的准确率进行评估:
# 打印训练准确率
y_train_pred = model.predict(X_train, params)
accuracy_score_train = model.accuracy(y_train, y_train_pred)
print(accuracy_score_train)
#查看测试集准确率:
y_prediction = model.predict(X_test, params)
accuracy_score_test = model.accuracy(y_test, y_prediction)
print(accuracy_score_test)
model.plot_logistic(X_train, y_train, params)
训练准确率:0.9875
测试集准确率:1.0

















 9524
9524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









