







本文为机器学习的学习笔记,讲解逻辑回归模型。
分类
分类问题是一种典型的无监督学习,其典型案例在【什么是机器学习】中已经介绍。
对于预测值 y,0 和 1 的设置是任意的。我们通常用 0 表示没有某个东西,用 1 表示有。如果 y 有多个取值: y ∈ { 0 , 1 , 2 , 3 } y\in\{0,1,2,3\} y∈{ 0,1,2,3},则称为多分类问题。
这是一个肿瘤预测的例子,我们【线性回归】的方法运用其中,用直线拟合。如果想要分类,可以将分类器的阈值设置为 0.5,即纵坐标值为 0.5:
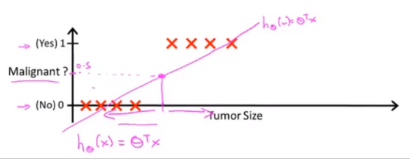
这貌似是可行的。但是当我们加入另一个预测点时,直线变为蓝色直线:
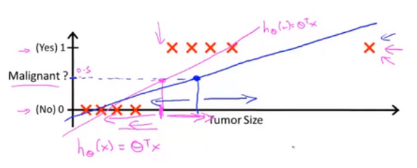
在蓝色竖线左边的值都会被判断为良性肿瘤,但这并不符合恶性肿瘤的前两个样本点。并且当使用线性回归模型时,计算出的预测值会远大于 1 或远小于 0,这是不符合常理的。因此我们通常不用线性回归来解决分类问题。我们将会讲到 logisitic 回归算法,其输出值在 0 到 1 之间,是一种分类算法。
假设陈述
对于 logistics 回归模型,假设函数与线性回归模型相似:
h θ ( x ) = g ( θ T x ) h_\theta(x)=g(\theta^Tx) hθ(x)=g(θTx)
我们想让 h θ ( x ) h_\theta(x) hθ(x) 的输出值在 0 和 1 之间,定义 g g g 如下:
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1
称为 Sigmoid 函数或 Logistic 函数,这两个术语可以互换。则此时:
h θ ( x ) = 1 1 + e − θ T x h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}} hθ(x)=1+e−θTx1
函数图像为:
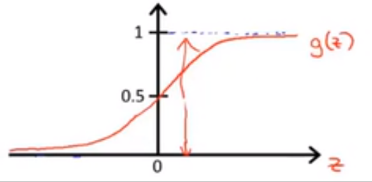
当假设函数输出一个值时,其含义是:对于一个输入 x x x, y = 1 y=1 y=1 的概率估计。例如一个病人用 logistics 回归模型预测出的值为 0.7,意味着:给定参数 θ \theta θ,对于特征为 x x x 的病人,有 70% 的可能是恶性肿瘤。写成数学表达式为:
h θ ( x ) = P ( y = 1 ∣ x ; θ ) h_\theta(x)=P(y=1|x;\theta) hθ(x)=P(y=1∣x;θ)
我们用 1 减去这个值就是 y = 0 y=0 y=0 的概率了。条件概率相关内容参考《概率论与数理统计》
决策边界
当假设函数的值大于等于 0.5 时,预测为 1,反之为 0。根据 Sigmoid 函数的图像有,当 θ T x ≥ 0 \theta^Tx\ge0 θTx≥0 时, h θ ( x ) = 1 h_\theta(x)=1 hθ(x)=1;否则为 0。
我们有一个数据集:
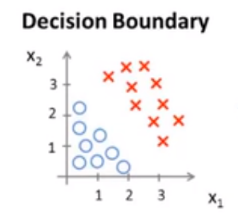
其假设函数为 h θ ( x ) = g ( θ 0 + θ 1 x 1 + θ 2 x 2 ) h_\theta(x)=g(\theta_0+\theta_1x_1+\theta_2x_2) hθ(x)=g(θ0+θ1x1+θ2x2),我们取 θ = [ − 3 1 1 ] \theta=\left[ \begin{matrix}-3\\1\\1 \end{matrix} \right] θ=⎣⎡−311⎦⎤。当 − 3 + x 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6292
6292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









