









论文由三部分构成,也是韩松在博士期间的工作,相关论文与解析见下面:
- Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman coding: https://blog.csdn.net/weixin_36474809/article/details/80643784
- DSD:Dense-sparse-dense training for deep neural networks, https://blog.csdn.net/weixin_36474809/article/details/85322584
- EIE:Efficient Inference Engine on Compressed Deep Neural Network https://blog.csdn.net/weixin_36474809/article/details/85326634
目录
三、DSD:Dense-sparse-dense training for deep neural networks
四、EIE:Efficient Inference Engine
Activation Queue and Load Balancing
Distributed Leading Non-Zero Detection
一、概览
1.1 作者介绍

这是一篇博士毕业论文,作者是斯坦福大学的韩松,现在在麻省理工,韩松的老师是NVIDIA的首席科学家,韩松现在是深鉴科技的首席科学家。这篇文章讲的是基于硬件的深度学习实现方法。系统的总结了韩松在博士期间的工作。从软件端的压缩到硬件端的压缩网络实现都有,对我们非常具有参考意义。
1.2 论文组成

论文由三部分组成,后面会具体讲这三种方法:
- Deep compression,从软件端极大的压缩了网络的权重。
- DSD,密集,稀疏,密集的训练方法,一种新的网络训练方法,能从训练层面一定的提升网络准确率
- EIE: 在Deep compression 的基础上,EIE是基于硬件的稀疏网络加速实现,硬件上达到很好的效果。
1.3 Abstract

动机:硬件上实现神经网络能带来极大的实际效益,但是由于神经网络的运算密集性和存储密集性很难硬件部署。
做法:从软件端和硬件端共同的实现相应的神经网络。
结果:比传统的CPU,GPU,和mobile GPU取得了10-100倍的速度提升和近千倍的功耗减少。
1.4 贡献点

- Deep compression 是模型压缩领域最经典的文章,它的方法现在被广泛应用,通过剪枝,权值量化,权值共享等将模型的存储压缩了35倍。
- DSD是作者提出的一种全新的训练方法,先密集,后稀疏,后密集的训练方法将模型的准确率提升了1%-4%
- EIE是具体的硬件实现,取得了很好的运算吞吐量和速率。
二、Deep compression
https://blog.csdn.net/weixin_36474809/article/details/80643784
2.1 方法

首先,网络通过正常的训练,训练出相应的权重,然后把低于某个阈值的权重删除掉,然后再训练模型,一次次去掉冗余的链接。
然后网络把保留的权重进行聚类和权值共享,然后通过训练不断调整聚类的中心点和聚类的数量,然后将最后的权值和权值索引进行哈夫曼编码。达到模型压缩的效果。下面详细讲解这些步骤。
2.2 剪枝
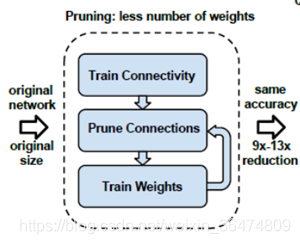
1. Learning the connectivity via normal network training.
通过正常方法训练网络
2. We prune the small-weight connections: all connections with weights below a threshold are removed from the network.
将小于某个阈值的权重扔掉,设为0不再训练
3. We retrain the network to learn the final weights for the remaining sparse connections.
重新训练相应的网络剩下的权重
2.3 稀疏权值矩阵的存储

剪枝之前的矩阵是非稀疏的矩阵,例如一个n*n的矩阵,经过剪枝的过程之后,这个n*n的矩阵就变为一个n*n的稀疏矩阵,其中很多零值。可以采用CSR或者CSC的方法对这个矩阵进行存储从而减少相应的存储量。
例如CSC的存储稀疏矩阵的方法
第一行AA存储所有的非零元素,
第二行JA存储所有系数矩阵中每行第一个非零元素在AA的位置,例如第一个元素是4.0,在AA中位置是第一个,第二行第一个元素是4.0,在AA中位置是第四个。通过JA可以将AA中所有元素对应的行恢复出来。
第三行JC是所有元素对应的列标。
这样,一个稀疏的矩阵通过三行就能存下来,达到了很好的存储压缩。由N*N变为了2a+N+1个元素
2.4 系数的差分存储
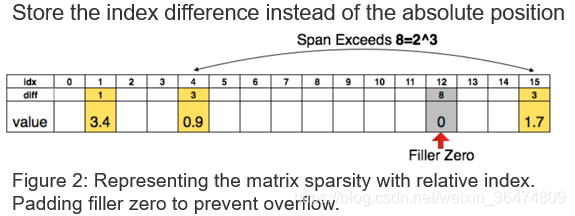
通过CSC得到了压缩的矩阵,可以通过差分存储进一步压缩存储数量。例如我们想用三比特的值来存储相应的Index。
3bit可以容忍的间距为8
- 当间距小于8时:用3比特的值就可以恢复出相应的位置
- 当间距大于8时:在第8个位置插入0值,然后用3bit的与插入的0值的差分位置恢复出相应的位置
- 间距大于8的倍数时:每隔8个位置插入0值,与最后一个0值的3bit的差分位置恢复出位置
2.5 权值共享

聚类方法
运用K-means的聚类方法,将权值接近的共享。运用聚类中心点的值作为所有权值的值。例如上面相同颜色的就是同一个聚类的。

权值更新方法Fine-tune
将所有聚类的点的梯度相加作为权值中心的梯度用于更新权值。
意义
1.Reducing the number of bits required to represent each weight.
减少每一个权重的表示需要的比特数
2.Limit the number of effective weights we need to store by having multiple connections share the same weight.
减少需要存储的权重个数(权值共享)
3.Fine-tune those shared weights.
可以共同对共享的权值进行微调与训练
压缩率
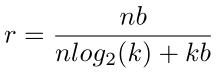
- 压缩前分子:原始权值的个数n,原始权重的比特数b,相乘得到原始总权值需要的比特数
- 压缩后分母:n为权重的个数,log2(k)表示聚类后的每一类的比特数。用这个可以恢复出共享的每一个权值属于哪一类,k为聚类书,b为之前的需要存储的精度,用这个可以恢复出每一个聚类的中心点的位置。
2.6 哈夫曼编码

通过前面的剪枝,量化,权值量化与共享,我们得到了相应的权值表与权值位置表。
可压缩性
但是这个表具有进一步压缩的潜能,因为其分布不是均匀分布。上面直方图体现了权值与location Idx的分布不是均匀分布。
哈夫曼编码
所以采用哈夫曼编码的方法,用短码代表出现频率高的权重,用长码替代出现频率低的权重,进一步对网络进行压缩。
2.7 实验
压缩方法对比

首先第一个实验,不同压缩方法在不同压缩率下精度的损失。横轴是压缩率,越靠左压缩率越大,纵轴是精度的损失,就是压缩之前和压缩之后的准确率的减少的量。这条曲线越靠左上越好,表明更大压缩率下精度损失更少,我们看到最好的方法就是剪枝和权值共享和权值量化的方法。
量化比特数

下面这三个图表示不同的压缩率对不同层的影响,第一个是压缩的比特数对全连接层的影响,第二个是压缩的比特数对卷积层的影响,第三个是两个层的压缩比特数对实验结果的影响,我们发现卷积层比全连接层对压缩的比特数更加敏感。
压缩效果与同类对比

在主流模型上均达到了很好的压缩率。

与其他模型压缩方法对比效果也是最优。
三、DSD:Dense-sparse-dense training for deep neural networks
https://blog.csdn.net/weixin_36474809/article/details/85322584
3.1 摘要
贡献点:
全新模型
提出了一个全新的DSD的训练流程,来使网络得到更好的训练。先Dense训练,获得一个网络权重;然后spars将网络剪枝,然后继续dense训练。从而获得更好的性能。
提升模型准确率
实验显示DSD在CNN,RNN,LSTM等图像分类、图像识别,语音识别等模型上都取得了很好的效果。
- 将GoogleNet的Top1 accuracy提升了 1.1%
- VGG-16提升了4.3%
- ResNet-18提升了1.2%
- ResNet-50提升了1.1%
易于实施
DSD易于实施,只在S阶段引入一个超参数,其他阶段也更易实现。
3.2 方法
区别
与dropout的区别
虽然都是在训练过程中有prune(剪枝)操作,但是DSD是有一定依据来选择去掉哪些connection,而dropout是随机去掉
与模型压缩的区别
DSD的目的是提升准确率,不能带来模型的精简。
3.3 算法流程


D:将网络正常训练,获得相应的权重
S:将网络剪枝,将小于某值的权重去掉,然后继续训练。
D:将剪枝的权重恢复为0,重新训练网络。
3.4 相应权重的变化

(a)上图为权重的直方图。我们看到第一次Dense训练之后,权重分布都有,且在各处分布
(b)将绝对值小于某值的权重删除掉,我们看到某绝对值一下的权重都没有了
(c)进行sparse训练,我们看到边缘变得平滑。
(d)恢复剪枝的权重,全部置为0。则0值有一个高峰。
(e)再次进行训练,权重各处都有分布。
3.5 具体流程及解释
Initial Dense Training
即普通神经网络的训练方法,但此步的目的是1.学出权重的值 2.学出哪些权重更重要(绝对值越大则权重越重要)。
Sparse Training
按比例将小于某绝对值权重值的值置为0。
进行剪枝的数学推导:
![]()
假定我们有一个loss,loss受到权重值的影响,是权重值的函数。
权重值变化会带来Loss值的变化:
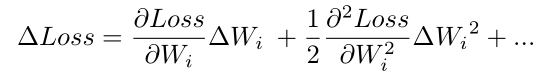
所以权重值越小,则置为0带来的权重的变化越小,Loss值的变化也越小。
Final Dense Training
恢复被剪枝的权重置为0,重新训练。
3.6 实验

各个数据集上均带来了性能的提升。
- Abs .Imp.为绝对提升,即与baseline的对比,
- Rel .Imp.是相对的提升,与剪枝之后的神经网络进行对比得到的提升。(此处存疑,但是基本认为是与刚刚剪枝之后,没有进行sparse训练的对比)

- LLR 为降低学习率,网络收敛更慢但是得到的局部极小值更好。






3.7 讨论与原理
DSD带来了准确率的提升,作者进行了下面这些讨论:
跳过了鞍点(Saddle Point)

鞍点:鞍点(Saddle point)在微分方程中,沿着某一方向是稳定的,另一条方向是不稳定的奇点,叫做鞍点。在矩阵中,一个数在所在行中是最大值,在所在列中是最小值,则被称为鞍点。在物理上要广泛一些,指在一个方向是极大值,另一个方向是极小值的点。
鞍点梯度接近于0,模型接近于收敛。但是剪枝的过程跳过了这些点。
更好的局部极小值(Better Minima)
低权重置为0就获得了更好的局部极小值。(对此作者没有具体解释)
正则化与稀疏训练
稀疏的正则化将模型拉到了更低的维度,因此可以对于噪声更加鲁棒。
鲁棒的再次初始化
普通的模型只初始化一次,但是DSD进行了两次(或更多)的权值初始化。这里作者给出了一个猜想,作者采用的是0值初始化的方法,其他的初始化方法值得尝试。
打破了对称性(Symmetry)
剪枝能破坏权值的对称性,所以获得更好的训练。(此处不明意义,作者未给出详尽解释,我对于symmetry的理解不够好。贴出原文)
Break Symmetry: The permutation symmetry of the hidden units makes the weights symmetrical,thus prone to co-adaptation in training. In DSD, pruning the weights breaks the symmetry of the hidden units associated with the weights, and the weights are asymmetrical in the final dense phase.
四、EIE:Efficient Inference Engine
4.1 概览
Motivation
最新的DNN模型都是运算密集型和存储密集型,难以硬件部署。
前期工作
Deep compression 通过剪枝,量化,权值共享等方法极大的压缩了模型。Deep compression解析见下链接
https://blog.csdn.net/weixin_36474809/article/details/80643784
贡献点
- 提出了EIE (Efficient Inference Engine)的方法,将压缩模型应用与硬件。
- 对于压缩网络来说,EIE可以带来120 GOPS/s 的处理效率,相当于同等未压缩的网络 3TGOP/s的处理效率。(AlexNet需要1.4GOPS,ResNet-152需要22.6GOPS)
- 比CPU和GPU带来24000x和3400x的功率提升。
- 比CPU,GPU和Mobile GPU速度快189x, 13x,307x
4.2 方法
公式描述
神经网络的基本运算
对于神经网络中的一个Fc层,相应的运算公式是下面的:
![]()
其中,a为输入,v为偏置,W为权重,f为非线性的映射。b为输出。此公式即神经网络中的最基本操作。
对于神经元的运算
针对每一个具体的神经元,上面的公式可以简化为下面这样:

输入a与权重矩阵W相乘,然后进行激活,输出为b
Deep compression后的公式
Deep compression将相应的权重矩阵压缩为一个稀疏的矩阵,将权值矩阵Wij压缩为一个稀疏的4比特的Index Iij,然后共享权值存入一个表S之中,表S有16种可能的权值。所以相应的公式可以写为:

即位置信息为i,j,非零值可以通过Iij找到表S中的位置恢复出相应的权值。
查表与值
权值的表示过程经过了压缩。即CSC与CRC的方法找到相应的权值,即![]()
具体可以参考Deep compression或者网上有详细的讲解。
https://blog.csdn.net/weixin_36474809/article/details/80643784

例如上面的稀疏矩阵A。我们将每一个非零值存下来在AA中。
JA表示换行时候的第一个元素在AA中的位置。例如A中第二列第一个元素在A中为第四个,第3行元素在A中为第6个。
IC为对应AA每一个元素的列。这样通过这样一个矩阵可以很快的恢复AA表中的行和列。
4.3 矩阵表示(重要)

这是一个稀疏矩阵相乘的过程,输入向量a,乘以矩阵W,输出矩阵为b,然后经过了ReLU。
用于实现相乘累加的单元称为PE,相同颜色的相乘累加在同一个PE中实现。例如上面绿色的都是PE0的责任。则PE0只需要存下来权值的位置和权值的值。所以上面绿色的权值在PE0中的存储为下面这样:

通过CSC存储,我们可以很快看出virtual weight的值。(CSC不懂见上一节推导)。行标与元素的行一致,列标可以恢复出元素在列中的位置。
向量a可以并行的传入每个PE之中,0元素则不并行入PE,非零元素则同时进入每一个PE。若PE之中对应的权重为0,则不更新b的值,若PE之中对应的权重非零,则更新b的值。
4.4 硬件实现
CCU与PE

CCU(Central control unit中央控制器)用于查找非零值,广播给PE(Processing Element处理单元,可以并行的单元,也是上文中的PE)。上图a为CCU,b为单个PE

PE即上面算法中的PE单元, 实现将CCU广播过来的数据进行卷积的相乘累加和ReLU激活。下面为每个具体单元的作用。
Activation Queue and Load Balancing
数据序列与负载平衡
上图之中的连接PE与CCU之间的序列。如果CCU直接将数据广播入PE,则根据木桶短板效应,最慢的PE是所有PE的时间的时长。

所以我们在每个PE之前设置一个队列,用于存储,这样PE之间不同同步,只用处理各自队列上的值。
- 只要队列未满,CCU就向PE的队列广播数据
- 只要队列之中有值,PE就处理队列之中的值
这样,PE之间就能最大限度的处理数据。
Pointer Read Unit

根据当前需要运算的行与列生成相应的指针传入稀疏矩阵读取单元。运用当前的列j(CCU传来的数据是数据和数据的列j)来生成相应的指针pj(此指针用于给Sparse Matrix Read Unit来读取对应的权值)
Sparse Matrix Read Unit

根据前面传入的指针值,从稀疏矩阵的存储之中读取出权重。即用前面传来的指针pj读取权重v,并将数据x一并传给ArithMetic Unit。即传给Arithmetic Unit的值为(v,x)
Arithmetic Unit

进行卷积之中的权重与feature相乘,然后累加的操作。从前面Sparse Matrix Read Unit中读出相乘得两个值,从后面的 Act R/W中读出偏移和加上后结果写入。
![]()
Activation Read/Write

取出偏置给Arithmetic Unit并且将Arithmetic Unit运算之后的结果传给激活ReLU层。即实现+bx的过程和传给最终结果给ReLU
Distributed Leading Non-Zero Detection

LNZD node,用于写入每层计算feature,下一层计算的时候直接传给CCU到下一层。在写入过程直接写入,运算过程可以探测非零值然后传给CCU。

这个因为神经网络计算方式,本层计算结果作为下一层的计算输入,激活神经元要被分发到多个PE里乘以不同的权值(神经网络计算中,上一层的某个神经元乘以不同的权值并累加,作为下一层神经元),Leading非零值检测是说检测东南西北四个方向里第一个不为0(激活)的神经元,就是每个PE都接受东南西北4个方向来的输入,这4个输入又分别是其他PE的输出,是需要计算的,那我这个PE计算时取哪个方向来的数据呢?用LNZD判断,谁先算完就先发射谁,尽量占满流水线。
PE之间用H-tree结构,可以保证PE数量增加时布线长度以log函数增长(增长最缓慢的形式)
Central Control Unit(CCU)
用于将LZND模块之中的值取出来然后传入PE的队列之中。
IO模式:当所有PE空闲的时候, the activations and weights in every PE can be accessed by a DMA connected with the Central Unit
运算模式:从LZND模块之中,取出相应的非零值传入PE的队列之中。
布局情况

作者运用台积电TSMC的45nm的处理器。上图为单个PE的布局情况。

表II为各个模块的功率消耗与区域占用情况。(其实我们看出,主要的功率消耗和区域占用在于稀疏矩阵读取单元SpmatRead,而不是直观上的运算单元ArithmUnit)
4.5 实验情况
实现平台
作者运用Verilog将EIE实现为RTL,synthesized EIE using the Synopsys Design Compiler (DC) under the TSMC 45nm GP standard VT library with worst case PVT corner. 运用台积电45nm和最差的PVT corner。作者用较差的平台来体现压缩及设计带来的数据提升。
We placed and routed the PE using the Synopsys IC compiler (ICC).We annotated the toggle rate from the RTL simulation to the gate-level netlist, which was dumped to switching activity interchange format (SAIF), and estimated the power using Prime-Time PX.
速度与功耗

运算平台:不同颜色是不同架构的运算平台,如CPU为Intel core i7 5930k,GPU为NVIDIA GeForce GTX Titan X,mobilt GPU为NVIDIA的cuBLAS GEMV。我们看到EIE起到了最快的效果。
运行的神经网络:如下:

运行时间见下表

负载平衡中FIFO队列的长度
负载平衡见3.2 ,FIFO为先进先出队列,用于存储CCU发来的数据给PE进行处理。FIFO越长越利于负载平衡

因为每个PE分得的是否为稀疏的数量为独立同分布的,所以FIFO越长,其总和的方差越小。所以增大FIFO会有利于PE之间的负载平衡。

SRAM的位宽度
SRAM的位宽度接口,位宽越宽则获取数据越快,读取数据次数越少(下图绿线),但是会增大功耗(蓝色条)。如下图:

总体的能量消耗需要两者相乘,如下:

运算精度
作者运用的是16bit定点运算。会比32bit浮点减少6.2x的功率消耗,但是会降低精度。

并行PE数对速度的提升

与同类工作的对比
内容较多,感兴趣自行查看原文。
















 822
822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











