







参考 计算机视觉中的细节问题(四) - 云+社区 - 腾讯云
目录
(1)、神经元死亡原因?
随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。这种神经元的死亡是不可逆转的死亡。训练神经网络的时候,一旦学习率没有设置好,第一次更新权重的时候,输入是负值,那么这个含有ReLU的神经节点就会死亡,再也不会被激活。因为:ReLU的导数在x>0的时候是1,在x<=0的时候是0。如果x<=0,那么ReLU的输出是0,那么反向传播中梯度也是0,权重就不会被更新,导致神经元不再学习。也就是说,这个ReLU激活函数在训练中将不可逆转的死亡,导致了训练数据多样化的丢失。在实际训练中,如果学习率设置的太高,可能会发现网络中40%的神经元都会死掉,且在整个训练集中这些神经元都不会被激活。所以,设置一个合适的较小的学习率,会降低这种情况的发生。为了解决神经元节点死亡的情况,有人提出了Leaky ReLU、P-ReLu、R-ReLU、ELU等激活函数。
(2)、立体匹配和语义分割出现的两个metric
- pixel error:
预测错误的像素点的个数除以总像素个数。对于二进制的labels,欧式距离和汉明距离结果相同。
优点:简单
缺点:过分敏感,可能已经到达了较好的分割效果,却有很大的pixel error。
- warping error:
是一种segmention metric,基于数字拓扑领域概念,比较边界标签的另一种指标。当pixel error很大当分割效果更好可以引入warping error,主要用来衡量分割目标的拓扑形状效果。
(3)、目标检测中end points的含义?
end_points用来记录每一层的特征图,各层的特征图大小是不一样的。
(4)、F-score的含义?
F1值为算数平均数除以几何平均数,且越大越好,将Precision和Recall的上述公式带入会发现,当F1值小时,True Positive相对增加,而false相对减少,即Precision和Recall都相对增加,即F1对Precision和Recall都进行了加权。
![]()
公式转化之后:
![]()
(5)、RoI池化层
Fast R-CNN提出的新技术,提取区域建议,然后经过卷积层和普通池化之后,用RoI 池化取代ALexNet第五个池化层,下面的篮框为RoI池化
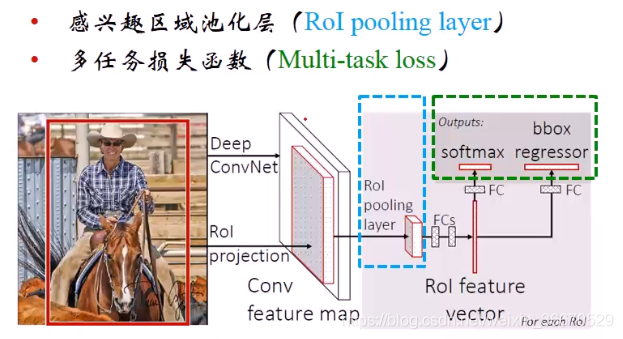
下图为RoI池化的原理
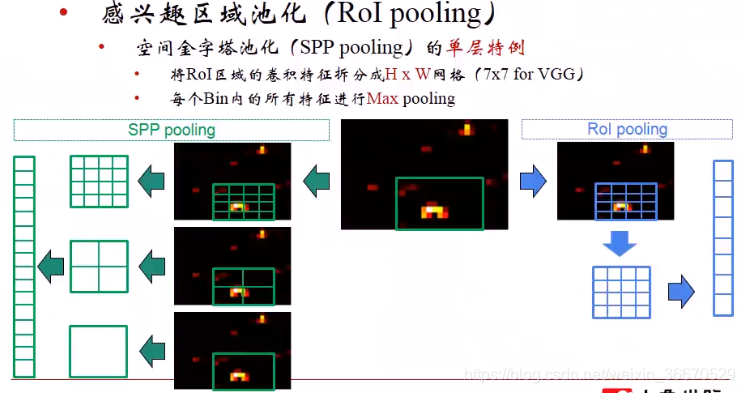
绿框为区域建议算法给出的区域建议,左边为SPP 池化分别对区域建议做4x4,2x2,1x1的最大池化,形成一个21个bin,而RoI池化只使用最上面的4x4进行最大池化,最终形成一个16个bin
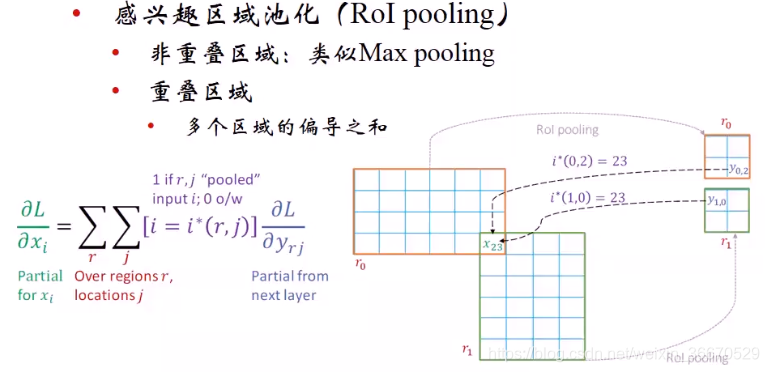
因为区域建议有重叠,非重叠区域和普通最大池化一样,重叠区域为多个区域的偏导数之和。
(6)、预训练与微调
什么是预训练和微调
- 你需要搭建一个网络模型来完成一个特定的图像分类的任务。首先,你需要随机初始化参数,然后开始训练网络,不断调整直到网络的损失越来越小。在训练的过程中,一开始初始化的参数会不断变化。当你觉得结果很满意的时候,你就可以将训练模型的参数保存下来,以便训练好的模型可以在下次执行类似任务时获得较好的结果。这个过程就是 pre-training。
- 之后,你又接收到一个类似的图像分类的任务。这时候,你可以直接使用之前保存下来的模型的参数来作为这一任务的初始化参数,然后在训练的过程中,依据结果不断进行一些修改。这时候,你使用的就是一个 pre-trained 模型,而过程就是 fine tuning。
所以,预训练 就是指预先训练的一个模型或者指预先训练模型的过程;微调 就是指将预训练过的模型作用于自己的数据集,并使参数适应自己数据集的过程。
预训练和微调的作用
在 CNN 领域中,实际上,很少人自己从头训练一个 CNN 网络。主要原因是自己很小的概率会拥有足够大的数据集,基本是几百或者几千张,不像 ImageNet 有 120 万张图片这样的规模。拥有的数据集不够大,而又想使用很好的模型的话,很容易会造成过拟合。
所以,一般的操作都是在一个大型的数据集上(ImageNet)训练一个模型,然后使用该模型作为类似任务的初始化或者特征提取器。比如 VGG,Inception 等模型都提供了自己的训练参数,以便人们可以拿来微调。这样既节省了时间和计算资源,又能很快的达到较好的效果。
(7)、权重衰减
可以加入权重衰减(weight decay)来修改线性回归的训练标准。带权重衰减的线性回归最小化训练集上的均方误差和正则化项的和 ,其偏好于平方
,其偏好于平方 范数较小的权重。具体如下
范数较小的权重。具体如下

其中 是提前挑选的值,控制我们偏好小范数权重的程度。当
是提前挑选的值,控制我们偏好小范数权重的程度。当 时,我们没有任何偏好。越大的偏好范数越小的权重。最小化可以看做拟合训练数据和偏好小权重范数之间的权衡。这会使得解决方案的斜率较小,或是将权重放在较少的特征上,我们可以训练具有不同值的高次多项式回归模型。
时,我们没有任何偏好。越大的偏好范数越小的权重。最小化可以看做拟合训练数据和偏好小权重范数之间的权衡。这会使得解决方案的斜率较小,或是将权重放在较少的特征上,我们可以训练具有不同值的高次多项式回归模型。
(8)、局部响应正态化(LRN)
LRN全称为Local Response Normalization,即局部响应归一化层,LRN函数类似DROPOUT和数据增强作为relu激励之后防止数据过拟合而提出的一种处理方法。这个函数很少使用,基本上被类似DROPOUT这样的方法取代,见最早的出处AlexNet论文对它的定义, 《ImageNet Classification with Deep ConvolutionalNeural Networks》

- i:代表下标,你要计算像素值的下标,从0计算起
- j:平方累加索引,代表从j~i的像素值平方求和
- x,y:像素的位置,公式中用不到
- a:代表feature map里面的 i 对应像素的具体值
- N:每个feature map里面最内层向量的列数
- k:超参数,由原型中的bias指定
- α:超参数,由原型中的alpha指定
- n/2:超参数,由原型中的deepth_radius指定
- β:超参数,由原型中的belta指定
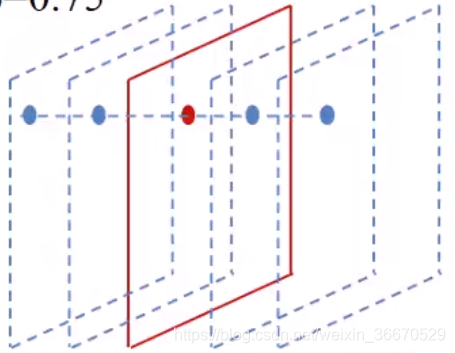
局部响应归一化是跨通道的归一化,基于模拟神经元侧抑制机制,某个(x,y)位置上跨通道方向上的归一化,N为卷积通道数,n为归一化邻域值。以上面的5个通道为例,在中间通道上做像素的归一化,在这个图中n=4,意思是朝两边各找两个邻域的值,找出来做平方和相加,平方和相加之后乘以超参 ,再加上k,对值的尺度和位置变一下,再进行
,再加上k,对值的尺度和位置变一下,再进行 次幂作为最终的分母得到归一化值,
次幂作为最终的分母得到归一化值,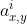 代表中心值,最后用中心值除以归一化值。
代表中心值,最后用中心值除以归一化值。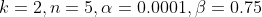 为超参数,需要用实验确定
为超参数,需要用实验确定
(9)、TPR、FPR、TNR、FNR的理解
TPR(True Positive Rate)可以理解为所有正类中,有多少被预测成正类(正类预测正确),即召回率,给出定义如下:

FPR(False Positive Rate)可以理解为所有反类中,有多少被预测成正类(正类预测错误),给出定义如下:

TNR(True Negative Rate)可以理解为所有反类中,有多少被预测成反类(反类预测正确),给出定义如下:
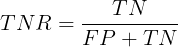
FNR(False Negative Rate)可以理解为所有正类中,有多少被预测成反类(反类预测错误),给出定义如下:

(10)、动量的作用
虽然梯度下降仍然是非常受欢迎的优化方法,但其学习过程有时会很慢。动量方法旨在加速学习,特别是处理高曲率、小但一致的梯度,或者是带噪声的梯度。动量算法积累了之前梯度指数级衰减的平均移动,并且继续沿该方向移动。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











