







在科技领域,总有一些技术能给人带来眼前一亮的惊喜。DeepSeek R1 模型横空出世以来,以其卓越的推理与推断能力吸引了众多工程师和研究者的关注。原生的 FP8 权重虽然在突破计算瓶颈上大放异彩,但其对 GPU 芯片的严格要求,也在不经意间设下了一道硬件屏障。为了打破这一限制,美团技术团队以求变革为动力,结合 SGLang 开源推理框架,对该模型进行了 INT8 量化探索,最终实现了在 A100 等众多 GPU 上无损部署,并带来了吞吐量上 50% 的惊人提升。下面,我们将通过一篇生动有趣且深入浅出的科普文章,带你走进 DeepSeek R1 INT8 量化工程的神秘世界。
🌟 背景:打破硬件桎梏的技术追求
随着大规模预训练语言模型(LLM)的快速迭代,DeepSeek R1 的发布无疑是在人工智能界激起了千层浪。最初的 FP8 权重设计,正如一把锋利的宝剑,虽锋芒毕露,却只能在特定的英伟达新型 GPU(例如 Ada、Hopper 架构)上大展身手。对于广大用户来说,这无疑是个“独角戏”,因为其他常见的 GPU(比如 A100)无法直接部署这种高精度模型。这不仅大大限制了模型的应用范围,同时也让推理过程中的显存需求和资源消耗成倍增加。
为此,美团搜索和推荐平台部后发制人,对 DeepSeek R1 模型进行了一次革命性的尝试——将 FP8 权重转换为 INT8 权重。经过大量实验和反复验证,他们发现,利用 INT8 量化技术不仅没有造成精度损失,反而在推理吞吐量上获得惊人的提升:与 BF16 模型相比,吞吐量高达 50%!从此,芯片的限制被逐步解锁,更多的 GPU 类型都能受益于 DeepSeek R1 的强大能力。
在本文中,我们将详细介绍这一变革的来龙去脉,以及在 SGLang 开源框架下,INT8 量化如何帮助模型降低成本、提升效率,并为未来更多优化指明方向。
🔍 INT8 量化推理实践:理论与实践的碰撞
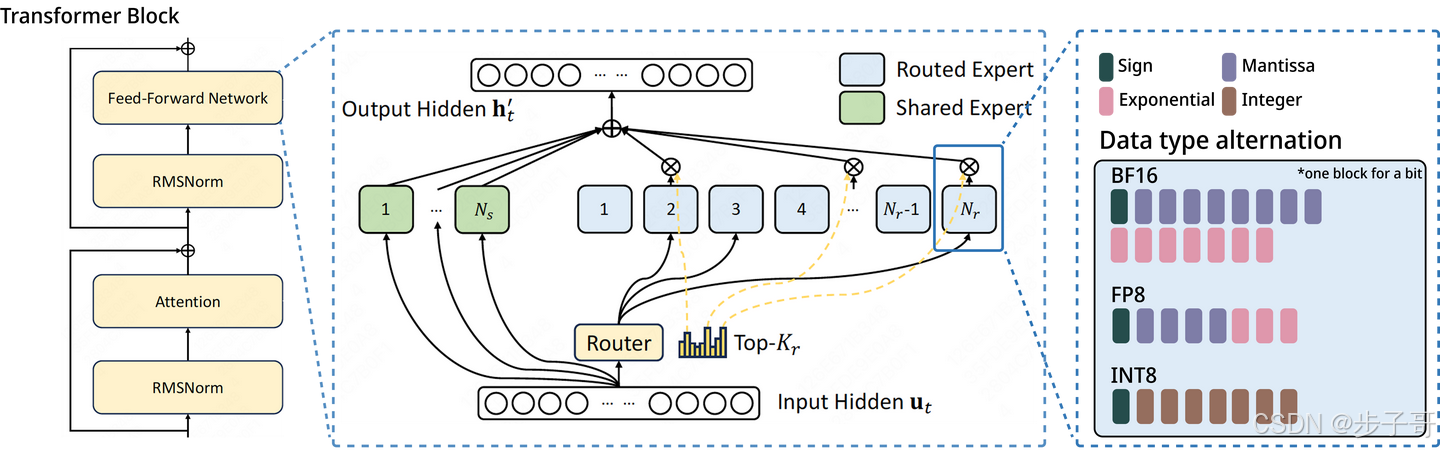
🎯 量化基本原理
模型量化其实是一种将模型高精度权重和激活值(例如 BF16、FP16)转换为低精度(如 INT8)的过程。说得通俗点,就像是把一副高清图片压缩成 JPEG 格式,文件体积减小的同时,还要尽可能保持画质不变。在 INT8 量化中,我们主要操作的是一个缩放因子(scale factor)的计算,以及在适当位置将浮点数进行量化(Quant)和反量化(Dequant)的过程。
以常见的 INT8 对称量化为例,整个过程可以概括为三步:
-
计算缩放因子
如果一个浮点数 tensor 中的元素为 x F P 16 x_{FP16} xFP16,那么我们首先计算其绝对值的最大值,然后将其除以 127,获得量化的缩放因子 x s c a l e x_{scale} xscale:x s c a l e
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1309
1309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











