







首先长这样:
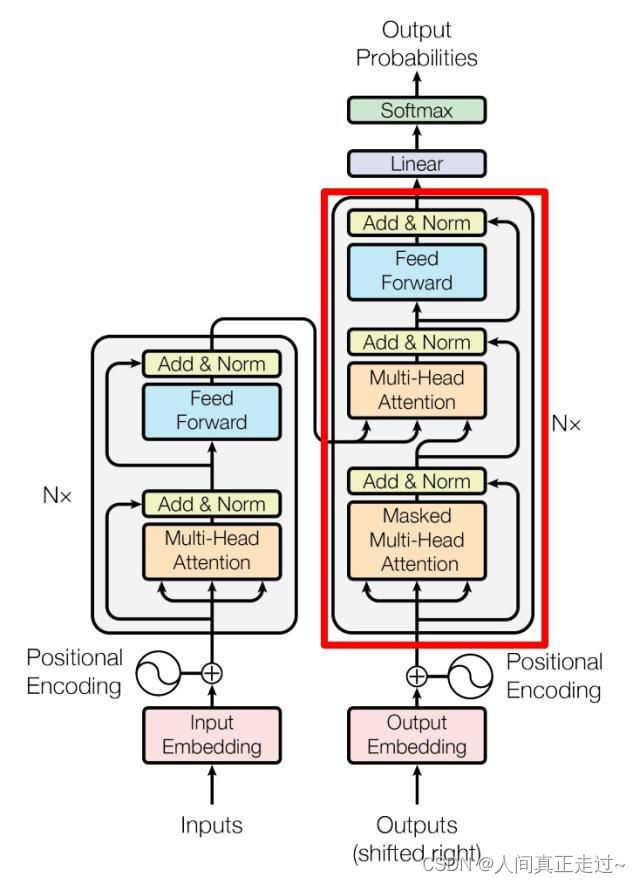
1.关于两种mask
参考Transformer 中的mask_Caleb_L的博客-CSDN博客_transformer中的mask
1)padding mask
在encoder和decoder两个模块里都有padding mask,位置是在softmax之前
为什么要使用padding mask,是因为由于encoder和decoder两个模块都会有各自相应的输入,但是输入的句子长度是不一样的,计算attention score会出现偏差,为了保证句子的长度一样所以需要进行填充
但是用0填充的位置的信息是完全没有意义的(多余的),经过softmax操作也会有对应的输出,会影响全局概率值,因此我们希望这个位置不参与后期的反向传播过程。以此避免最后影响模型自身的效果,既在训练时将补全的位置给Mask掉,也就是在这些位置上补一些无穷小(负无穷)的值,经过softmax操作,这些值就成了0,就不在影响全局概率的预测。
2)Sequence MASK
只存在decoder的第一个mutil_head_self_attention里
因为在测试验证阶段,模型并不知道当前时刻的输入和未来时刻的单词信息。也就是对于一个序列中的第i个token解码的时候只能够依靠i时刻之前(包括i)的的输出,而不能依赖于i时刻之后的输出。因此我们要采取一个遮盖的方法(Mask)使得其在计算self-attention的时候只用i个时刻之前的token进行计算。
因此在encoder中,只有padding mask
decoder中,既有padding也有seqeunce,后者是一个下三角,总的是两个矩阵的叠加
2.feed forward
第一层的激活函数为 Relu,第二层不使用激活函数
3.softmax是按行进行
4.decoder的输入
1)第二个 Multi-Head Attention
变化不大, 主要的区别在于:
A. 其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
B. 第二个attention无需 Mask
2)是否传入真值:
训练时,outputs?测试时,?【待补充】
5.训练时loss、optimizer怎么操作?
对如下代码
for epoch_idx in tqdm(range(100)):
for batch_idx,batch in enumerate(train_generator):
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
注意以上三者的顺序。作用分别是:清空梯度、计算梯度、反向传播。
源代码中optimizer.zero_grad()、optimizer.step()是在第二个for循环之外,这不对,因为相当于你只根据最后一个batch来更新梯度















 1271
1271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









