






我们都知道在postCTS阶段做optDesign时序优化时需要进行hold violation的fixing。所以这个过程势必要通过插hold buffer来解决hold violation。这类hold buffer的名字带有"PHC"的关键词。
select_obj [dbGet top.insts.name PHC]
llength [dbGet top.insts.name PHC]
在后续的postRoute阶段做时序优化阶段,工具默认也有一个area reclaim的步骤。这个步骤主要的目的是在设计critical path上进一步把path上的cell面积做小。
工具会把setup critical path上冗余的hold buffer删掉,来进一步优化setup。
但是工具默认不会删除non-critical path上冗余的hold buffer。
这就会出现很多timing path的hold timing margin偏大的情况。一个设计要做出一个合理的结果,必须确保IC实现各个环节各个步骤的结果都是合理的。
下面分享解决这个问题的几个方法。
方法一: 报告timing并做基于hold的面积优化
Legacy UI:
timeDesign -postRoute
reclaimArea -maintainHold
Common UI:
time_design -post_route
opt_area -hold_aware
方法二: 设置opt优化mode
Legacy UI:
setOptMode -postRouteAreaReclaim {none | setupAware | holdAndSetupAware}
optDesign -postRoute
Common UI:
set_db opt_post_route_area_reclaim {none | setup_aware | hold_and_setup_aware}
opt_design -post_route
使用这个方法工具删除多余的hold buffer后不会引起setup和drv violation。
听说Latch可以高效修hold违例(Timing borrowing及其应用)
所以,当PT signoff需要插入很多hold buffer,返回PR工具插不进去时,我们可以使用今天的这个方法来删掉部分冗余的hold buffer来释放更多的空间。
当然,这个提前是PT和PR之间的timing correlation比较好的情况。
另外,我们还可以自己针对绕线或空间比较紧张的区域,人工删掉部分带PHC的hold buffer来释放点空间。
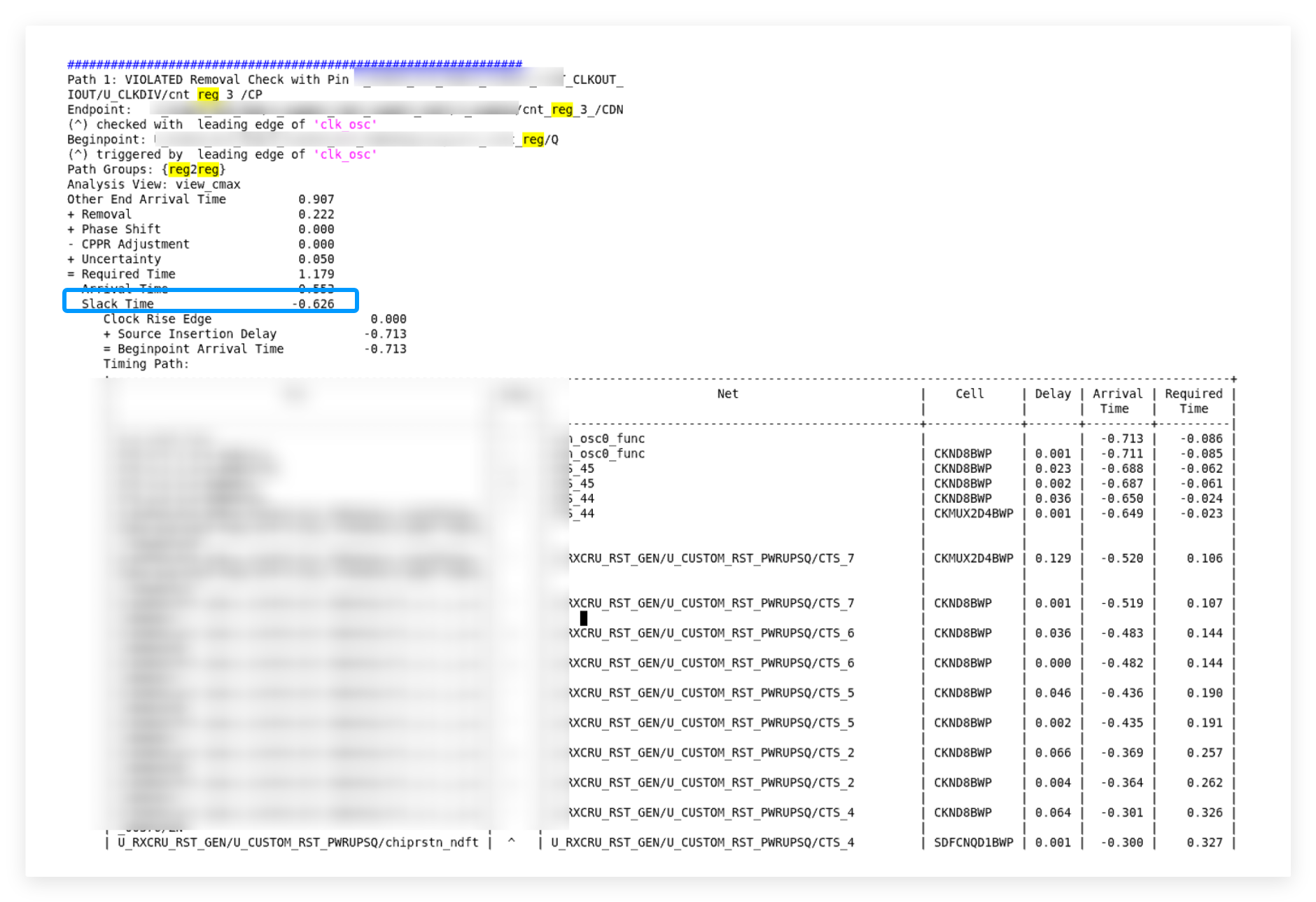
【思考题】如下所示timing path的removal存在600ps+的violation。请问这个hold violation存在的主要原因是什么?这么大的hold violation应该如何修复呢?

















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









