







概述
近年来,由于深度卷积神经网络可以为图像获取强大的特征,显著目标检测(Salient Object Detection,SOD)得到了极大的改善。特别是基于全卷积网络(FCN)的框架,通过端到端训练,预测像素级别的label,使得SOD方法具有较高的精度和效率。
然而,这种框架对对抗攻击(Adversarial Attack)很敏感。它在输入图像中添加准不可察觉的噪声,却不改变人类标注的ground truth,从而混淆了神经网络。
发表在TCYB2019的这篇文章是第一个对SOD模型进行成功的对抗性攻击,并验证对抗性样本在现有的多种方法上的有效性的工作,提出了可以增强任何基于全卷积神经网络(FCN)的显著目标检测模型对对抗攻击的鲁棒性的框架,ROSA。
综合全文,本文最重要的内容是对现有模型进行白盒攻击,并通过引入新的更容易分辨的噪声,来打破难以分辨的对抗扰动的结构,而不是试图直接去除对抗扰动;同时没有颠覆目前主流的基于FCN的模型,而是增加两个组件,对现有模型进行增强,从而保证了框架的泛化性能。
背景知识
首次接触这个领域,所以收集了一些对抗攻击和SOD方面的术语解释,结合自己的理解整理如下[1][2][3]。有基础的朋友就可以跳过这部分啦~
显著目标检测(Salient Object Detection,SOD)
在一篇介绍深度学习下的显著目标检测的综述Salient Object Detection in the Deep Learning Era: An In-Depth Survey中提到,显著目标检测的目的是突出图像中的显著目标区域。
综述中将显著目标检测的任务定义如下:将 input image(通常为三通道图像),经过SOD算法 F 后,获得二值显著目标,即binary salient object mask。也就是说,将图片分为前景和背景部分,并用黑白像素表示。前景部分包括了图片场景中最主要的一些目标。

显著性图(Saliency Map)
卷积神经网络的一种可解释性方法。图像的每个像素有两种标签/类型:显著或非显著,可视化效果即为黑白像素。
对抗攻击(Adversarial Attack)
由于机器学习算法的输入形式是一种数值型向量(numeric vectors),所以攻击者就会通过设计一种有针对性的数值型向量从而让机器学习模型做出误判,这便被称为对抗性攻击。
和其他攻击不同,对抗性攻击主要发生在构造对抗性数据的时候,之后该对抗性数据就如正常数据一样输入机器学习模型并得到欺骗的识别结果。对抗攻击产生的对抗样本无法用肉眼被分辨出来,不会改变人类标注的真值,但这些视觉上难以察觉的变化增大了神经模型的预测误差。
如下图所示,加入对抗性噪声之后,神经网络对图像的识别出现了极大的偏差。

对抗样本/图像(Adversarial Example/Image)
干净图像的一个修改版本,通过添加噪声等方式来混淆/愚弄深层神经网络等机器学习技术
对抗性扰动(Adversarial perturbation)
对抗性扰动是指加到干净的图像中,使其成为一个对抗样本的噪声。
1.攻击模式分类
下面介绍的两种分类方式,是在实际运用中测试防御模型效果较为常用的攻击模式。其中,黑盒攻击和白盒攻击的概念将会在防御算法的论文中被反复提及。一般提出的新算法,都需经受黑盒攻击和白盒攻击两种攻击模式的测定。
黑盒攻击与白盒攻击
-
白盒攻击:攻击者能够获知机器学习所使用的算法,以及算法所使用的参数。攻击者在产生对抗性攻击数据的过程中能够与机器学习的系统有所交互。
-
黑盒攻击:攻击者并不知道机器学习所使用的算法和参数,但攻击者仍能与机器学习的系统有所交互,比如可以通过传入任意输入观察输出,判断输出。
在实际应用中,这两者的区别体现为:通过模型A来生成对抗样本,进而攻击模型B。当模型A与模型B是一个模型时,为白盒攻击;当模型A与模型B不为一个模型时,则为黑盒攻击。
有目标攻击与无目标攻击
- 无目标攻击(untargeted attack):对于一张图片,生成一个对抗样本,使得标注系统在其上的标注与原标注无关,即只要攻击成功就好,对抗样本的最终属于哪一类不做限制。
- 有目标攻击(targeted attack):对于一张图片和一个目标标注句子,生成一个对抗样本,使得标注系统在其上的标注与目标标注完全一致,即不仅要求攻击成功,还要求生成的对抗样本属于特定的类。
常见对抗样本生成方式
- FGSD(Fast gradient sign method)
一种基于梯度生成对抗样本的算法,其训练目标是最大化损失函数 J ( x ∗ , y ) J(x^{*},y) J(x∗,y)以获取对抗样本 x ∗ x^{*} x∗,其中 [公式] 是分类算法中衡量分类误差的损失函数,通常取交叉熵损失。最大化 J J J即使添加噪声后的样本不再属于 y y y类,由此则达到了上图所示的目的。在整个优化过程中,需满足 L ∞ L_{\infty} L∞约束 ∣ ∣ x − x ∗ ∣ ∣ ≤ ϵ ||x-x^*||\leq\epsilon ∣∣x−x∗∣∣≤ϵ,即原始样本与对抗样本的误差要在一定范围之内。

s i n g ( ) sing() sing()是符号函数,括号里面是损失函数对 [公式] 的偏导 - FGM(fast gradient method)
对FGSD做了推广,使其能够满足 L ∞ L_{\infty} L∞约束 ∣ ∣ x − x ∗ ∣ ∣ 2 ≤ ϵ ||x-x^*||_{2}\leq\epsilon ∣∣x−x∗∣∣2≤ϵ 。

- IFGSD(Iterative gradient sign Method)
对FGSD的一种推广,是对上述算法的多次应用,以一个小的步进值 α \alpha α多次应用快速迭代法
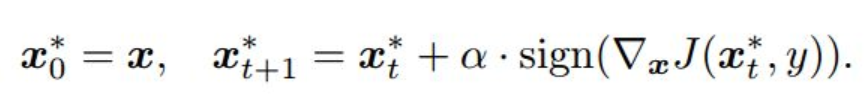
为了使得到的对抗样本满足 L ∞ L_{\infty} L∞ ( 或 L 2 L_{2} L2)约束,通常将迭代步长设置为 α = ϵ / T \alpha=\epsilon/T α=ϵ/T ,其中 T T T为迭代次数。
常见防御方法
-
对抗训练:对抗训练旨在从随机初始化的权重中训练一个鲁棒的模型,其训练集由真实数据集和加入了对抗扰动的数据集组成,因此叫做对抗训练。
-
梯度掩码:由于当前的许多对抗样本生成方法都是基于梯度去生成的,所以如果将模型的原始梯度隐藏起来,就可以达到抵御对抗样本攻击的效果。
-
随机化:向原始模型引入随机层或者随机变量。使模型具有一定随机性,全面提高模型的鲁棒性,使其对噪声的容忍度变高。
-
去噪:在输入模型进行判定之前,先对当前对抗样本进行去噪,剔除其中造成扰动的信息,使其不能对模型造成攻击。
动机
显著性目标检测(SOD)的目的是对图像或者视频帧中,在视觉上与众不同的目标进行定位和分割,通常在系统初始化或预处理阶段使用,因此效率和鲁棒性非常重要。
基于深度学习的SOD模型大致可分为两类:
- 分段标注(segment-wise labeling)
- 直接预测像素级的saliency map作为结果
基于像素的方法通常采用全卷积网络(FCN)结构。它将整幅图像作为输入,直接生成显著性图,是一种dense labeling method。这种方法不仅具有较高的效率,而且达到了state-of-the-art。
但基于FCN的方法有一些缺点,在实际中性能可能会降低。
- 端到端的可训练性使得梯度可以很容易地从有监督的样本传播到输入图像,因此显著目标检测模型面临着对抗攻击的风险
- dense labeling method不对图像不同部分之间的对比度进行建模,而是在一个FCN中估计该像素的显著性。一旦输入图像被对抗噪声污染,不能自我更正的低层特征和高层特征会受到影响
- 显著目标检测的数据集图片数量较少,包含的显著目标的类别也很有限。因此,现有的模型实际上是在拟合数据中的偏差,比如说只是检测出了训练集中经常出现的对象,而不是学会定位最显著、最不同的对象。这些方法过度依赖于捕获数据集图片中的高级语义,可能对低级别的干扰(如对抗噪声)比较敏感
分段标注的方法是一种sparse labeling method。首先将图像分区,在同一个区域内的像素很可能具有相似的显著性值,这个值可通过提取区域的CNN特征来估计。与基于像素的方法相比,分段标注的方法由于显式地对底层的对比度(contrast)特征进行建模,并根据多区域得到显著值,从而有更高的鲁棒性。然而,在实际应用中,由于要对数百个片段进行评估,采用稀疏标记方法是低效的。
为了让已有的基于像素的方法在增强鲁棒性的同时维持高效性,本文提出了可以将任何FCN作为backbone的Robust Saliency框架(ROSA)。
模型
为了消除对抗噪声,作者在backbone前设计了分段屏蔽元件Segment-wise shielding component, 简称SWS。它根据低层次的相似度将图像分成很多小部分,在每个部分随机打乱其中的像素,通过引入另一种通用噪声,来破坏对抗性样本的结构,减轻了攻击效果。
为了refine受新引入的噪声影响的结果,作者在backbone之后放置情景感知恢复组件Context-aware restoration component,简称CAR。该组件根据位置及其周围的原始像素值之间的相似性调整某个位置的显著性值。

这个框架的主要流程如图所示,大体上可分为两步
-
利用SWS引入新噪声
首先,将对抗样本作为input,SWS引入一些新的通用噪声来消除input中的对抗扰动,然后学习用引入的噪声来预测图像的显著性图。 -
利用CAR、双边滤波器和backbone组成的模型进行训练
接下来,对基于FCN的backbone和CAR进行端到端训练,以适应引入噪声的输入图像。基于FCN的backbone将噪声图像作为输入,生成粗糙的显著性图后,对输入图像进行双边滤波(bilateral filter),得到平滑图像。CAR根据这张平滑图像和粗糙的显著性图之间像素级别的相似度对显著性图进行refine。最后,计算refine过的图像与ground truth之间的像素级别的交叉熵。
双边滤波器bilateral filter
图像去噪的方法很多,如中值滤波,高斯滤波,维纳滤波等等。但这些降噪方法容易模糊图片的边缘细节,对于高频细节的保护效果并不明显。相比较而言,bilateral filter双边滤波器可以很好的边缘保护,即可以在去噪的同时,保护图像的边缘特性。
流程中每个部分的详细介绍如下:
如何生成显著目标检测的对抗样本?
利用一个迭代的基于梯度的流水线(iterative gradient-based pipeline)来合成对抗样本。本文采用的是无目标攻击。需要一个预先训练好的SOD神经网络,一些图片及其在像素级别上标注的显著性图。
f ( ⋅ , θ ) f(·, θ) f(⋅,θ): 预先训练好的网络
x x x: 原始图像
x ∗ x^{*} x∗: 对抗样本
y y y: 0代表不显著,1代表显著
ϵ \epsilon ϵ: 误差范围上限。为了保证扰动是难以察觉的,样本相对于原图的变动需满足 L ∞ L_{\infty} L∞约束 ∣ ∣ x − x ∗ ∣ ∣ ≤ ϵ ||x-x^*||\leq\epsilon ∣∣x−x∗∣∣≤ϵ
T T T: 迭代次数
S t S_{t} St: 模型仍能分辨出来的像素集合
α \alpha α: 步长
对抗样本的目标就是令神经网络对所有像素出错,无法给出原有的标签。在每个时间步上,希望能通过更新让图像 x x x能使 f f f最大化,使得预测出的分类不再是 y i y_{i} yi。
在每个时间步t,对抗样本更新方式如下。
p
t
p_{t}
pt就是这一步增加的对抗扰动。

梯度计算如下:
求和的每一项表示了一个符号函数,对神经网络尚能正确标注的像素,使扰动向使
f
f
f增大的方向(正号)增加。

那么t步的对抗扰动
p
t
p_{t}
pt通过正则化计算如下:

当达到迭代次数或达到
L
∞
L_{\infty}
L∞约束的边界时停止流程,生成该时间步的样本。
鲁棒的 SOD 框架
ROSA框架由以下三个部分组成:
- SWS
- 基于FCN的backbone
- CAR
其中,任何一个基于FCN的视觉显著性模型,以一张图片为输入,密集标记的显著性图(densely labeled salient map)为输出。
分段屏蔽组件(segment-based shielding component,SWS)
在将输入图像发送到主干之前,引入一些更容易抵抗的“shuffling”噪声,消除了输入图像中潜在的对抗性噪声。
step1 region decomposition
首先采用区域分解方法将图片划分为一些超像素。
划分的方法具体来说类似于KNN,是在颜色和像素位置的联合空间中,采样k个聚类中心,然后将每个像素分配给离它最近的聚类中心,接着利用属于这个聚类中心的像素点的平均值更新聚类中心。将这个过程进行迭代直到新聚类中心与上一个聚类中心的位置之间的 L 2 L2 L2误差收敛。
超像素
超像素就是把一幅像素级(pixel-level)的图,划分成区域级(district-level)的图,是对基本信息元素进行的抽象。由一系列位置相邻且颜色、亮度、纹理等特征相似的像素点组成一些小区域,这些小区域大多保留了进一步进行图像分割的有效信息,且一般不会破坏图像中物体的边界信息。
step2 随机重排一个超像素区域内的像素
这个操作将引入的噪声限制在单个超像素内的同时,极大地消除了对抗扰动。这样,这些超像素所遵循的对象边界不会被破坏,骨干网络输出的噪声显著性映射有机会得到恢复。
之前说到,现有的FCN模型在可视化显著性数据中学习了过多的高级语义。随机排列使得获取高级语义变得更加困难,并强制神经网络去获取区域之间低级的对比度信息。
情景感知的恢复组件(context-aware restoration component,CAR)
挖掘每个像素和它周围像素之间的相似度来细化主干网络提供的显著性评分。由于之前的高级别的卷积特征已经被污染,我们需要测量像素之间在低级的颜色空间和空间位置上的相似性。
通过最小化一些能量函数来调整显著性图
y y y:原本较为粗糙的显著性图
y ∗ y^* y∗:作为结果的显著性图

公式第一项衡量更新显著性图前后的cost,第二项衡量了同时更新第i个和第j个像素的显著性图得到的cost,将对给i和j不同的标签的行为给予惩罚,因此它鼓励给位置相近的像素打上相同的标签。
训练过程
step1
用预先训练好的视觉显著性模型初始化基于FCN的backbone。
step2
对以上两个部分的参数一起进行fine-tune(分段屏蔽组件没有可学习的参数,反向传播时梯度不会传到该组件上)。
为了保持对不同对抗扰动的泛化性能,训练集不包括对抗样本,只包含原始图片。
step3
计算显著性图的ground-truth和情境感知恢复组件的输出之间的像素级别的交叉熵损失。梯度计算采用SGD。训练过程中采用提前停止策略,如果连续2个周期后,验证集的性能没有提高,则终止训练。
实验
数据集&评价指标
| 数据集 | 训练集大小 | 验证机大小 | 测试集大小 |
|---|---|---|---|
| MSRA-B | 2500 | 500 | 2000 |
| HKU-IS | 2500 | 500 | 1447 |
| DUT-OMRON | 2500 | 500 | 2168 |
| ECSSD | 1000 |
使用MAE, Fβ, PR曲线作为评价指标。
MAE 平均绝对误差
测量显著性图S和ground truth G之间的像素上的差异。该指标越小越好。
Fβ
实验中的精确率(precision)指,在显著性图上预测标签为“显著”的像素中有多少在ground truth上也是“显著”值(被正确预测);召回率(recall)是指,在ground truth上表现为“显著”的像素被显著性图正确描述的比例。将像素判定为显著或非显著的阈值为经过图像大小W和H进行平均的显著性图上像素值的和。

Fβ将准确率和召回率这两个分值合并为一个分值,且在合并的过程中,召回率的权重是准确率的β倍。该指标越大越好

PR曲线[6]
将图片S进行二值化时,进行等距采样获得阈值列表。每取一个阈值,即可对所有图S算得一组相对应的Precision值与Recall值。最后将所有图像在该阈值下的Precision值与Recall值分别求平均,最后将会得到多对P,R值,以Recall为横坐标,Precision为纵坐标绘制曲线图,即可得到precision-recall (PR)曲线。
三组实验
- 对抗攻击的有效性
对已有模型进行对抗攻击,研究对抗攻击对各种模型的影响程度 - 本文提出的框架的鲁棒性
将提出的框架加到已有模型上,研究其对已有模型的鲁棒性的增强效果 - 消融实验
验证ROSA框架中每个组件的有效性
对抗攻击的有效性
论证了框架在8种state-of-the-art视觉显著性模型上的性能。
采用白盒攻击+黑盒攻击,对抗样本在预先训练的DSS模型上生成,用于攻击包括DSS在内的模型。这些模型都在MSRA-B训练集上训练,HKU-IS测试集上测试。
- DSS
- DCL
- RFCN
- Amulet
- UCF
- MC
- LEGS
- MDF
(每个模型的特点有待后续补充)

Table I显示DSS受攻击最严重,因为是采用DSS模型合成的对抗性样本。DCL、RFCN、Amulet和UCF受到不同程度的影响,这可能取决于它们的体系结构与用于发起攻击的预训练模型之间的相似性。

蓝色实线:对抗性样本测试结果
橙色虚线:原始图像测试结果
DCL, RFCN, Amulet, UCF在对抗样本上的PR曲线下降了,说明在一些基于FCN的模型上生成的对抗样本对其他不同基于FCN的模型也会产生影响;MC, LEGS和MDF的自然图像与对抗性样本的PR曲线比较接近,说明基于稀疏标记的方法(sparse labeling-based methods)对对抗性噪声不敏感。

条形图同样反映了上述结果。
本文提出的框架的鲁棒性
鲁棒性实验中,利用DSS, DCL和RFCN模型作为baseline,在包含HKU-IS, DUT-OMRON和MSRAB训练集的集合上训练。对抗样本同样是在DSS上合成。
与本文提出的框架以及现有的几种应用于鲁棒图像分类、同时能迁移到其他问题的防御算法进行了比较。
以DSS作为baseline为例。表格每一行对应了不同的数据集,D-adv表示对数据集的对抗样本进行的实验;表格每一列对应不同的模型,N+M表示神经网络N+防御方法M。这里采用了两种评价指标进行评估。
DSS ∗ * ∗ 的Fβ退化严重到低于1.0%,这是由于对抗样本在该模型上合成。然而,对于加上了本文提出的框架的DSS模型,即DSS+ours ∗ * ∗,同样用它自己的DSS backbone产生的样本攻击它,Fβ结果仍然明显超过DSS。同时,本文的框架大多数情况下在干净图像上的达到最佳Fβ和MAE,这表明本文的方法能让backbone在对抗样本数据集和干净图像数据集上都得到很好的提升。
文中进行对比的其他防御算法有:
Smooth[7]
空间平滑滤波器(spatial smooth filter),分为线性和非线性的,可用于模糊处理和降低噪声。
平滑线性空间滤波器的输出(响应)是包含在滤波器模板邻域内的像素的简单平均值。这种处理的结果降低了图像灰度的尖锐变化。由于典型的随机噪声由灰度级的急剧变化组成,因此常见的平滑处理的应用就是降噪。
统计排序滤波器是一种非线性空间滤波器,这种滤波器的响应以滤波器包围的图像的像素的排序为基础,然后使用统计排序结果决定的值代替中心像素的值。比如中值滤波器,将像素邻域内的灰度值的中值代替该像素的值,使拥有不同灰度的点看起来更接近于他们的相邻点。。它对于一定类型的随机噪声提供了一种优秀的去噪能力。而且比同尺寸的线性平滑滤波器的模糊程度明显要低。不足之处就是中值滤波花费的时间是均值滤波的5倍以上。
JPEG
将输入图像输入目标网络之前对其进行JPEG压缩,减少对抗扰动对准确率的影响,但压缩图像的同时也会降低正常分类的准确率。
Quant
进行比特压缩。将RGB图片的8bit像素压缩得更小。
TVM
最小化总差异(total variation minimization),减小相邻像素之间的差异。


上图描述了对各模型鲁棒性的定性比较。最左列为原图,左二列为相应的对抗样本,最右列为ground truth。通过中间三种backbone与各自加上了本文的框架的结果的对比可以看到,本文的框架增强了backbone模型预测的准确度。
消融实验(Ablation Study)
ablation study主要目的是研究整个流程中每个部分到底起了多大的作用,就像控制变量法一样,每次移除框架中的一些模块,看对性能有多大影响。
分别将DSS、DCL和RFCN模型用于实验。上述模型均在MSRA-B训练集上进行训练,并在HKU-IS测试集上进行测试。
用SWS表示分段屏蔽组件,CAR表示情景感知恢复组件,ROSA表示本文整个框架,*代表不同的backbone,分别将
∗
*
∗+SWS/
∗
*
∗+CAR与
∗
*
∗+ROSA进行对比。
从表格中可以看出:
- 在对抗样本数据集上, ∗ * ∗+ROSA的Fβ指标比 ∗ * ∗+CAR高出很多,MAE指标显著降低,这表明了SWS的有效性;
- 在对抗样本数据集上,与 ∗ * ∗+SWS相比, ∗ * ∗+ROSA在两个指标上的表现可以得到与(1)相同的结论,这验证了CAR的有效性。
实际上,SWS与CAR是两个互补的组件。有了SWS,CAR的有效性更加显著。

关于attack strength
表示
L
∞
L_{\infty}
L∞的上界的超参数
ϵ
\epsilon
ϵ会影响的对抗攻击的强度。
实验从MSRA-B的测试集中随机选取500幅图像命名为MSRA-B500。 ϵ \epsilon ϵ列表的采样范围为[0,30],用不同的 ϵ \epsilon ϵ值为整个MSRA-B500合成一组生成对抗样本,以预先训练的DSS模型作为目标网络发起攻击。
采用另一种训练好的DSS模型和加上了本文框架的DSS模型分别对每一组对抗性样本进行了检验,效果如下图所示。横轴为对抗攻击的强度
ϵ
\epsilon
ϵ,纵轴为两种评价指标;蓝色的线代表DSS模型,红色的线代表加上了ROSA的DSS模型。

可以看到,随着攻击强度的增加,DSS呈现非常剧烈的Fβ的下降和MAE的上升,而有ROSA加持的DSS的曲线非常平稳,几乎没有什么变化,说明这个防御框架对于不同强度的攻击具有鲁棒性。
结论
本文的工作首次成功地攻击了state-of-the-art的视觉显著性模型,通过实验证明现有的基于FCN的模型对对抗扰动非常敏感,并提出了新的SOD框架。该框架通过引入新的噪声来打破难以分辨的对抗扰动的结构,而不是试图直接去除对抗扰动,让模型自己学会在有噪声的条件下分辨出显著性目标。框架包含了SMS,CAR和backbone部分,能很好地提升基于FCN的那些backbone的鲁棒性。
参考资料
[1]综述阅读:Salient Object Detection in the Deep Learning Era: An In-Depth Survey
https://www.cnblogs.com/imzgmc/p/11072100.html
[2]<EYD与机器学习>:对抗攻击基础知识(一)
https://zhuanlan.zhihu.com/p/37260275
[3]对抗攻击常用术语
https://blog.csdn.net/C_chuxin/article/details/85216846
[4]bilateral filter双边滤波器的通俗理解
https://blog.csdn.net/guyuealian/article/details/82660826
[5]什么是对抗攻击?
http://www.myzaker.com/article/5a0126911bc8e0d32a00000b/
[6]显著性目标检测模型评价指标(二)——PR曲线
https://blog.csdn.net/StupidAutofan/article/details/79583531
[7]平滑空间滤波器
https://zhuanlan.zhihu.com/p/57659199














 1597
1597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









