







代码实现
需要声明几个变量:
sentence代表输入的raw数据,n代表的是最终获取到的每一条训练数据的维度,k代表的是中心词左右的滑动子窗口的大小,即整体滑动窗口的大小是2k+1,
下面代码实现能比较清楚地展现计算过程。
from nltk.util import ngrams
from itertools import combination
def skipgrams(sentence, n, k):
SENTINEL = object()
ngrams_list = list(ngrams(sentence, n + k, \
pad_right=True, right_pad_symbol=SENTINEL))
for ngram in ngrams_list:
head = ngram[:1]
tail = ngram[1:]
for skip_tail in combinations(tail, n - 1):
if skip_tail[-1] is SENTINEL:
continue
yield head + skip_tail
示意图解释
为了能够更加清晰地了解这段代码背后的思想,以sentence="1 2 3 4 5 6 7 8 9 10 11 12 13 14, n = 3, k = 5"为例,来介绍算法的流程。首先,通过调用ngrams函数来构建sentence的n+k gram,这样操作的意义在于第一个中心词向左获取训练样本能够正常进行,下图是对这里描述的进一步解释。
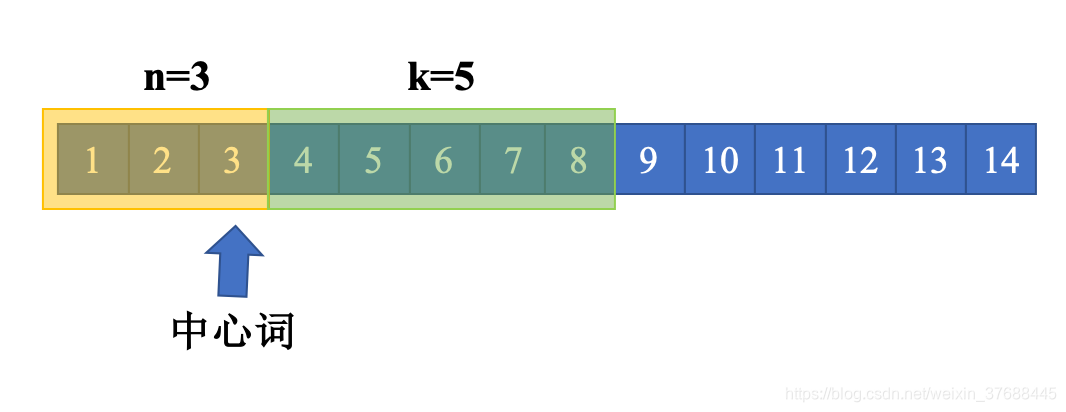
针对每一个gram,固定首元素
g
r
a
m
0
m
gram_{0}^m
gram0m,针对剩下的n+k-1个元素,随机选择两个元素
g
r
a
m
i
m
,
g
r
a
m
j
m
gram_{i}^m, gram_{j}^m
gramim,gramjm(其中
m
m
m代表的是grams中的第
m
m
m个gram),将
g
r
a
m
0
m
gram_{0}^m
gram0m与这两个元素拼接在一起作为一条训练数据
{
g
r
a
m
0
m
,
g
r
a
m
i
m
,
g
r
a
m
j
m
}
\{gram_{0}^m,gram_{i}^m, gram_{j}^m\}
{gram0m,gramim,gramjm},这样对于每一个gram,都有
A
n
+
k
−
1
2
A_{n+k-1}^2
An+k−12种组合,这样就能够不重不漏地将所有的训练数据构建完成。
外传
最近在看CS224N NLP相关课程,对老师讲的Word2Vec目标函数计算时印象颇深,因而在这里备注一下自己的笔记:

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









