









1、提升树的思想
提升树是以分类树或者回归树为基本分类器的提升方法,实际采用的是加法模型(基函数的线性组合),以决策树为基函数的提升方法称为提升树。提升树的核心思想就是在不断的拟合残差,比如一个人的年龄是25岁,第一次猜到16,那么9就是我们接下来要拟合的残差,不断的迭代更新这个树,最终使得误差或者迭代次数满足我们的要求即可。
2、前向分布算法

初始化一个基分类器,存在一个数据集T,通过进行M轮的迭代更新不断更新β和γ,再更新![]() ,最终得到加法模型。
,最终得到加法模型。
3、回归问题的提升树算法

(3)得到回归提升树fMx=m=1MT(x:θm)![]()

回归问题提升树算法的实例:https://zhuanlan.zhihu.com/p/84139957
4、XGBD算法

- 初始化,估计使损失函数极小化的常数值,它是只有一个根节点的树,即γ是一个常数值。
- 计算损失函数的负梯度在当前模型的值,将它作为残差的估计
- 估计回归树叶节点区域,以拟合残差的近似值
- 利用线性搜索估计叶节点区域的值,使损失函数极小化
- 更新回归树
- 得到输出的最终模型 f(x)

当损失函数是平方损失函数的时候,我们就可以这个负梯度恰好就是我们提升树中的残差。
当提升树的损失函数是指数函数和平方损失函数的时候,每一步的优化是比较简单的,但是当换成别的函数的时候就比较复杂了,因此提出来用负梯度做为回归问题残差的近似值然后取拟合一个回归树。利用最速下降法的近似方法,关键是利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值,拟合一个回归树。
为啥用负梯度可以拟合残差值呢?
这个问题本身就是错误的,是GBDT拟合的是负梯度,不过恰好损失函数是平方损失函数的时候这个拟合的负梯度是残差。具体的原理是这样的:
对于一个函数进行一节泰勒展开

二元函数的泰勒展开
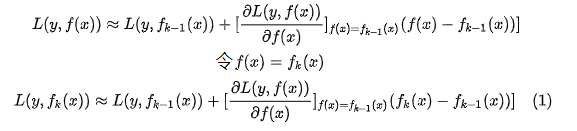

5、各路”豪杰”与GBDT的对比
- AdaBoost vs GBDT
AdaBoost主要是改变数据的权重来有重点的进行学习,然后进行线性组合得到一个较好的分类器。GBDT主要是根据拟合当前的负梯度减小分类误差,改进模型。
- LR vs GBDT
从决策边界来说,线性回归的决策边界是一条直线,逻辑回归的决策边界根据是否使用核函数可以是一条直线或者曲线,而GBDT的决策边界可能是很多条线。
6、优缺点
优点
① 可以灵活处理各种类型的数据,包括连续值和离散值。
②在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的。
③使用一些健壮的损失函数,对异常值的鲁棒性非常强
缺点
①由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行
7、代码
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
from sklearn.ensemble import GradientBoostingClassifier
iris_data = datasets.load_iris()
x = iris_data['data']
y = iris_data['target']
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.2,random_state=6)
ss = StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.transform(x_test)
clf = GradientBoostingClassifier(random_state=6)
clf.fit(x_train, y_train)
predict = clf.predict(x_test)
acc = metrics.accuracy_score(y_true=y_test,y_pred=predict)
recall = metrics.recall_score(y_true=y_test,y_pred=predict,average='micro')
precision = metrics.precision_score(y_true=y_test,y_pred=predict,average='micro')
print('acc',acc)
print('recall',recall)
print('precision',precision)














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









