







对于高分辨率的图像分割问题,基于编解码结构的分割网络虽然有效,但因为卷积和池化下采样的存在,特征图在变小的过程会逐渐损失一些细粒度的信息,非常不利于高分辨率图像的像素稠密预测。针对这个问题,此前的各项研究归纳而言提出了如下三点处理方法:
(1)类似于FCN和UNet,直接使用转置卷积上采样来恢复图像像素,但转置卷积对于下采样过程中丢失的低层信息的恢复能力有限。
(2)使用空洞卷积,通过给常规卷积中插入空洞的方式来增大卷积感受野,并且没有缩小图像尺寸,但这种方式计算开销增大,模型运行效率降低,并且空洞卷积作为一种较为粗糙的子采样(sub-sampling),也会存在图像重要信息损失的问题。
(3)使用跳跃连接。类似于UNet中编解码器间的跳跃连接,直接将编码器每一层的特征图连接到解码器上采样结果上,能够对解码图像进行信息补充。
相关研究认为,对于编解码结构而言,所有层次的特征对语义分割都是有帮助的。高层次的特征用于识别图像中的语义信息,低层次的特征则有助于恢复高分辨率图像的边界细节。但如何有效利用中间层次的信息值得进一步探索,前述充分使用跳跃连接的方法或许会更加有效。基于此,研究人员提出了一种针对高分辨率图像语义分割的多层次特征精细化网络:RefineNet。提出RefineNet的论文为RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation,该网络基于ResNet结构和跳跃连接,使用多路径的精细化网络结构来获取最佳的分割结果,是高分辨率图像分割的经典网络。
RefineNet简要结构如图5-9所示。RefineNet总体上仍然是编解码结构,编码器部分根据预训练的ResNet网络划分了4个卷积块,与之对应的是级联了4个RefineNet单元到解码器部分。每个编码器ResNet卷积块的输出特征图都会被连接到对应的RefineNet单元,如图中的ResNet-4连接到RefineNet-4单元,到了RefineNet-3单元,除了接收来自ResNet-3的输出外,还需要接收RefineNet-4单元的输出,对于RefineNet-3单元而言就构成了两路径的输入。这样层层向上级联,就构成了多路径的RefineNet。其中编码器中每个特征图到解码器RefineNet单元的连接也叫长程残差连接(long-range residual connections)。
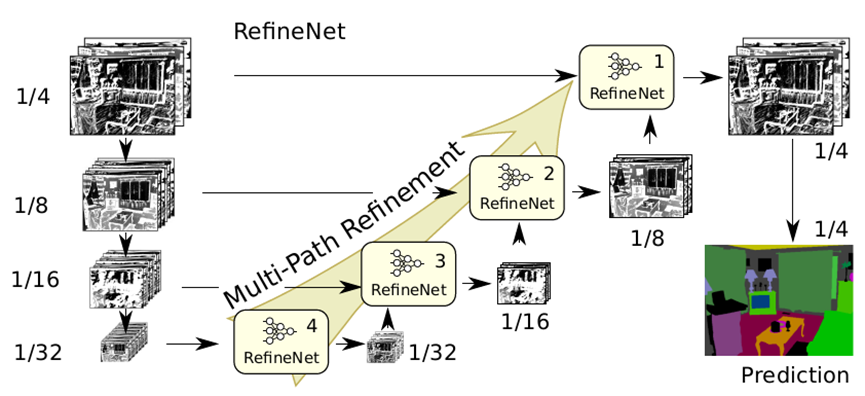
上图仅给出了包含了编码器在内的RefineNet简要结构,而RefineNet单元的具体结构如下图所示。一个RefineNet单元由残差卷积单元(Residual convolution unit,RCU)、多分辨率融合(Multi-resolution Fusion)和链式残差池化(Chained Residual Pooling,CRP)组成。RCU较为简单,就是常规的ResNet结构,每一个输入路径都会经过两次RCU操作后再输出到下一个单元。RCU的跳跃连接在RefineNet中也被称为短程残差连接(short-range residual connections)。紧接着是一个多分辨率特征图融合层,将上一层RCU输出的多路径特征图经过一个33的卷积和上采样操作后进行加总,得到合并后的特征图。最后是一个CRP单元,这也是RefineNet的特色结构,通过3个链式的池化和卷积残差组合来捕捉大图像区域的背景上下文信息。将CRP之后得到特征图再经过一次RCU即可到最终的分割输出。
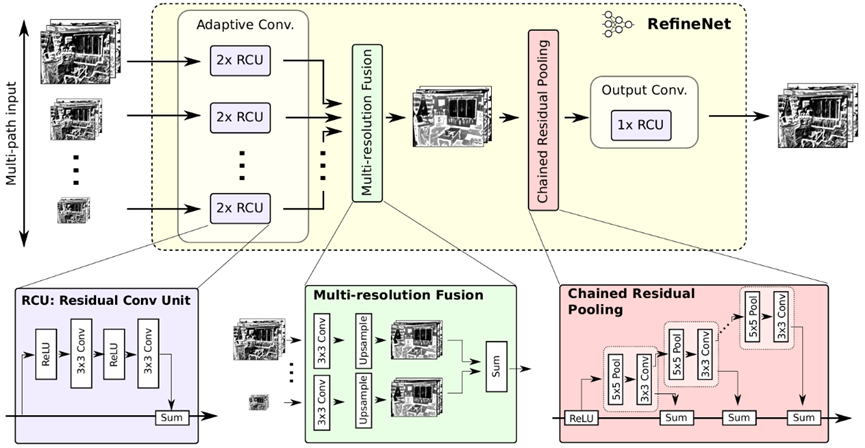
作为一种针对高分辨率图像的精细化分割网络,RefineNet的结构设计无疑是成功的,当时在多个公开数据集上均取得了SOTA性能表现。这种多路径的精细化网络能够通过迭代精炼的方式将粗糙的语义特征精炼为细粒度的语义特征。其次,基于长短程的残差连接能够使得模型进行端到端的训练,推理时也非常高效。最后,链式残差池化也使得网络能够更好的捕捉大图像的上下文信息。
RefineNet代码完整实现可参考:
https://github.com/DrSleep/refinenet-pytorch
其中关于RCU和CRP模块的实现如下代码所示。
class RCUBlock(nn.Module):
def __init__(self, in_planes, out_planes, n_blocks, n_stages):
super(RCUBlock, self).__init__()
for i in range(n_blocks):
for j in range(n_stages):
setattr(self, '{}{}'.format(i + 1, stages_suffixes[j]),
conv3x3(in_planes if (i == 0) and (j == 0) else out_planes,
out_planes, stride=1,
bias=(j == 0)))
self.stride = 1
self.n_blocks = n_blocks
self.n_stages = n_stages
def forward(self, x):
for i in range(self.n_blocks):
residual = x
for j in range(self.n_stages):
x = F.relu(x)
x = getattr(self, '{}{}'.format(i + 1, stages_suffixes[j]))(x)
x += residual
return
class CRPBlock(nn.Module):
def __init__(self, in_planes, out_planes, n_stages):
super(CRPBlock, self).__init__()
for i in range(n_stages):
setattr(self, '{}_{}'.format(i + 1, 'outvar_dimred'),
conv3x3(in_planes if (i == 0) else out_planes,
out_planes, stride=1,
bias=False))
self.stride = 1
self.n_stages = n_stages
self.maxpool = nn.MaxPool2d(kernel_size=5, stride=1, padding=2)
def forward(self, x):
top = x
for i in range(self.n_stages):
top = self.maxpool(top)
top = getattr(self, '{}_{}'.format(i + 1, 'outvar_dimred'))(top)
x = top + x
return x下图是RefineNet在Cityscape数据集上的预测效果。

往期精彩:














 6789
6789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









