





RefineNet: Multi-Path Refinement Networks forHigh-Resolution Semantic Segmentation (2017) 论文笔记
文章的创新点在于decoder的方式,不同于U-Net在上采样后直接和encoder的feature map进行级联,本文通过RefineNet进行上采样,把encoder产生的feature和上一阶段decoder的输出同时作为输入,在RefineNet中进行一系列卷积,融合,池化,使得多尺度特征的融合更加深入。 另一创新点就是RefineNet模块中的链式残余池化,为了验证这个模块的效果,作者做了对比实验,证明在加入该模块后,分割效果确实变好了。
1. Abstract
-
- 为了解决下采样过程中导致的信息损失,论文提出了RefineNet,通过利用下采样过程中能够获取到的所有信息。
- 网络组建使用了恒等映射的残余连接。
- 另外,论文还介绍了链式残余池化(chained residual pooling ),可以高效的获取背景信息。
- 在公共数据集(VOC 2012)中做了实验,实现了最佳效果
2. Introduction
反卷积不能恢复low-level的feature,deeplab使用空洞卷积来解决这一问题。
但是空洞卷积有两个问题:
-
-
- 对高像素feature map的卷积会消耗算力,同时也需要大的GPU内存,通常对于高像素的图都会resize
- 空洞卷积的特性决定了它会损失一些细节信息。
-
FCN等方法提出的特征融合虽然能够保留低维和高维信息,但缺少了空间信息?
本文的贡献:
-
-
- 提出了RefineNet,它是一种多路径的提炼网络,利用多级抽象特征进行高分辨率的语义分割,通过递归方式提炼低分辨率的特征,生成高分辨率的特征
- 级联的refineNet可以end-to-end训练,使用了恒等映射的残余连接
- 提出了链式残余池化。使用不同尺寸的窗口池化,并且使用残余连接和可学习的权重把他们融合起来
-
3. Related work
-
- 提到了FCN,segnet,deconvnet, unet, deeplab v2等
- 能够利用低维的feature来精炼高维的semantic feature.
- 使用了短范围和长范围的残余连接,实验表明,我们的网络十分有效。
4. Background
分析resnetnet
-
-
- 降采样增加了感受野
- 提高了训练效率
- 一般的最终会降采样到1/32,会损失信息,可选的解决方法是使用空洞卷积
-
deeplab v2
-
-
- 降采样操作全部被取消,在第1个block之后的卷积层全部使用空洞卷积。优点是在不增加参数的情况下增加了感受野。
- 文章说,空洞卷积很消耗内存,原因在于空洞卷积在较高分辨率上保留大量的feature map,在网络的后层通道数很多。
- 我的理解是因为少了下采样,feature map自然就会很大,但对于文章所说的后层通道数增多不太理解。
-
5. 网络结构
-
- 网络整体结构

-
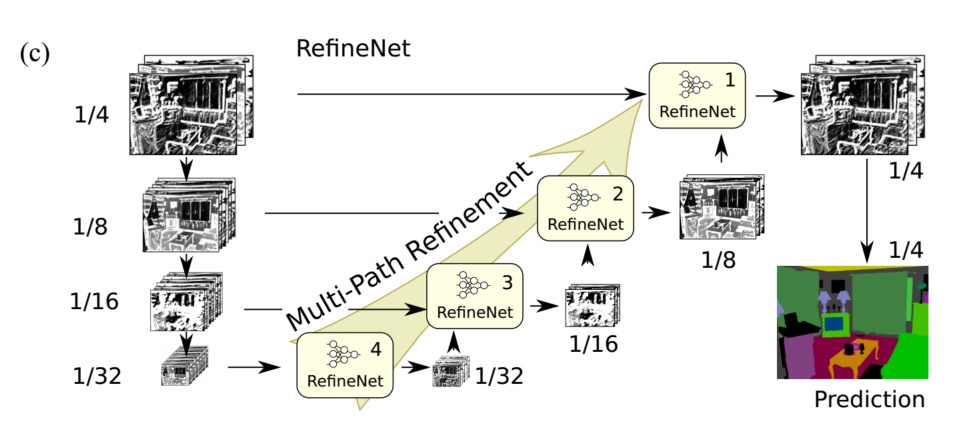
- 下图是单独一个refineNet的结构,上面的图中包含了4个refineNet。
-
- 也就是说,一个RefineNet相当于一个上采样模块,接受多个(一个)输入,输出一个。下采样是ResNet,然后经过4个RefineNet上采样,得到原来大小图。作者的创新点一方面在于提出了整个网络结构,另一方面是RefineNet模块中的链式残余池化。
- 根据整体结构图可以看到,RefineNet-4只接受一个输入,后面的3个每个都接受两个输入。
- RefineNet
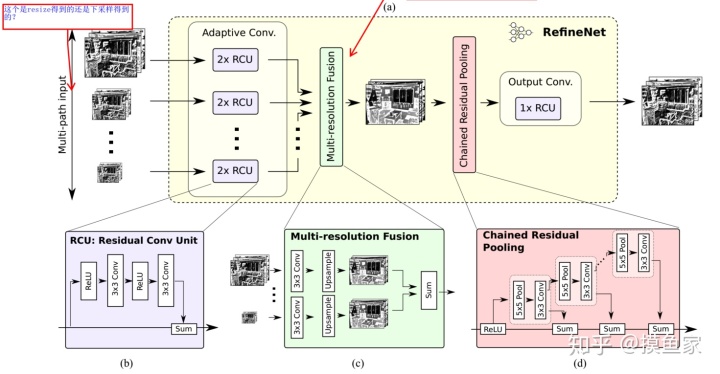
- 根据图片可以看到,每个RefineNet包含4个部分
- Residual convolution unit :对ResNet block进行2层的卷积操作。注意这里有多个ResNet block作为输入。
- Multi-resolution fusion:将1中得到的feature map进行加和融合。
- Chained residual pooling :该模块用于从一个大图像区域中捕捉背景上下文。注意:pooling的stride为1。
- Output convolutions:由三个RCUs构成。
- 根据图片可以看到,每个RefineNet包含4个部分
Reference
https://zhuanlan.zhihu.com/p/37805109 RefineNet: Multi-Path Refinement Networks forHigh-Resolution Semantic Segmentation














 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









