







以CNN为基础的编解码结构在图像分割上展现出了卓越的效果,尤其是医学图像的自动分割上。但一些研究认为以往的FCN和UNet等分割网络存在计算资源和模型参数的过度和重复使用,例如相似的低层次特征被级联内的所有网络重复提取。针对这类普遍性的问题,相关研究提出了给UNet添加注意力门控(Attention Gates, AGs)的方法,形成一个新的图像分割网络结构:Attention UNet。提出Attention UNet的论文为Attention U-Net: Learning Where to Look for the Pancreas,发表在2018年CVPR上。注意力机制原先是在自然语言处理领域被提出并逐渐得到广泛应用的一种新型结构,旨在模仿人的注意力机制,有针对性的聚焦数据中的突出特征,能够使得模型更加高效。
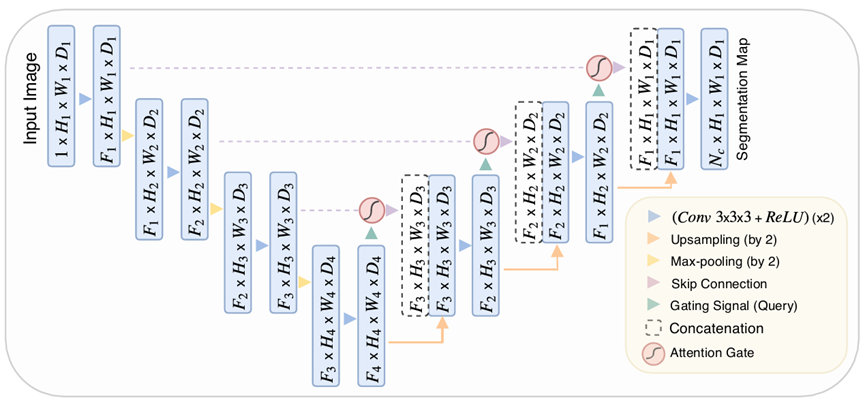
Attention UNet的网络结构如下图所示,需要注意的是,论文中给出的3D版本的卷积网络。其中编码器部分跟UNet编码器基本一致,主要的变化在于解码器部分。其结构简要描述如下:编码器部分,输入图像经过两组3*3*3的3D卷积和ReLU激活,然后再进行最大池化下采样,经过3组这样的卷积-池化块之后,网络进入到解码器部分。编码器最后一层的特征图除了直接进行上采样外,还与来自编码器的特征图进行注意力门控计算,然后再与上采样的特征图进行合并,经过三次这样的上采样块之后即可得到最终的分割输出图。相比于普通UNet的解码器,Attention UNet会将解码器中的特征与编码器连接过来的特征进行注意力门控处理,然后再与上采样进行拼接。经过注意力门控处理后得到的特征图会包含不同空间位置的重要性信息,使得模型能够重点关注某些目标区域。
我们将Attention UNet的注意力门控单独拿出来进行分析,看AGs是如何让模型能够聚焦到目标区域的。如图中上图所示,将Attention UNet网络中的一个上采样块单独拿出来,其中x_l为来自同层编码器的输出特征图,g表示由解码器部分用于上采样的特征图,这里同时也作为注意力门控的门控信号参数与x_l的注意力计算,而x^hat_l即为经过注意力门控计算后的特征图,此时x^hat_l是包含了空间位置重要性信息的特征图,再将其与下一层上采样后的特征图进行合并才得到该上采样块最终的输出。
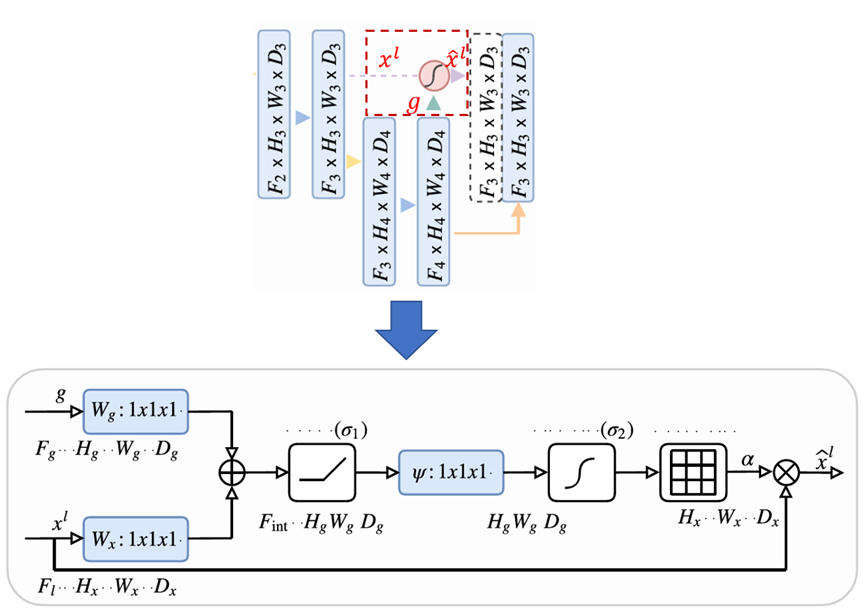

将x_l和g_i计算得到的注意力系数再次与x_l相乘即可得到x^hat_l,这种经过与注意力系数相乘后的特征图会让图像中不相关的区域值变小,目标区域的值相对会变大,提升网络预测速度同时,也会提高图像的分割精度。论文中的各项实验结果也表明,经过注意力门控加成后后UNet,效果均要优于原始的UNet。下述代码给出了Attention UNet的一个2D参考实现,并且下采样次数由论文中的3次改为了4次。
### 定义Attention UNet类
class Att_UNet(nn.Module):
def __init__(self,img_ch=3,output_ch=1):
super(Att_UNet, self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv1 = conv_block(ch_in=img_ch, ch_out=64)
self.Conv2 = conv_block(ch_in=64, ch_out=128)
self.Conv3 = conv_block(ch_in=128, ch_out=256)
self.Conv4 = conv_block(ch_in=256, ch_out=512)
self.Conv5 = conv_block(ch_in=512, ch_out=1024)
self.Up5 = up_conv(ch_in=1024, ch_out=512)
self.Att5 = Attention_block(F_g=512, F_l=512, F_int=256)
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512, ch_out=256)
self.Att4 = Attention_block(F_g=256, F_l=256, F_int=128)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256, ch_out=128)
self.Att3 = Attention_block(F_g=128, F_l=128, F_int=64)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128, ch_out=64)
self.Att2 = Attention_block(F_g=64, F_l=64, F_int=32)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 =
nn.Conv2d(64, output_ch, kernel_size=1, stride=1, padding=0)
### 定义前向传播流程
def forward(self,x):
# 编码器部分
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# 解码器+连接部分
d5 = self.Up5(x5)
x4 = self.Att5(g=d5,x=x4)
d5 = torch.cat((x4,d5),dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4,x=x3)
d4 = torch.cat((x3,d4),dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3,x=x2)
d3 = torch.cat((x2,d3),dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2,x=x1)
d2 = torch.cat((x1,d2),dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
return d1
### 定义Attention门控块
class Attention_block(nn.Module):
def __init__(self, F_g, F_l, F_int):
super(Attention_block, self).__init__()
# 注意力门控向量
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int,
kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
# 同层编码器特征图向量
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int,
kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(F_int)
)
# ReLU激活函数
self.relu = nn.ReLU(inplace=True)
# 卷积+BN+sigmoid激活函数
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1,
kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
### Attention门控的前向计算流程
def forward(self,g,x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1+x1)
psi = self.psi(psi)
return x*psi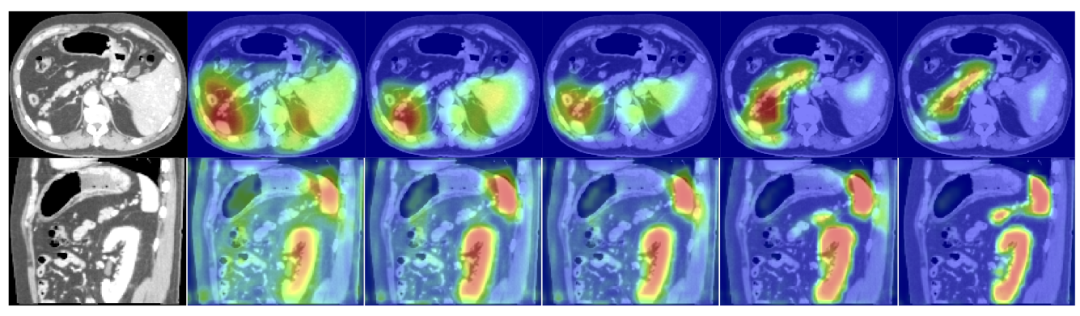
总结来说,Attention UNet提出了在原始UNet基础添加注意力门控单元,注意力得分能够使得图像分割时聚焦到目标区域,该结构作为一个通用结构可以添加到任何任务类型的神经网络结构中,在语义分割网络中对前景目标区域的像素更具有敏感度。Attention UNet壮大了UNet家族网络,此后基于其的改进版本也层出不穷。
往期精彩:














 2050
2050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









