







在数位设计的世界中,我们迎来了一场技术革命! Luma AI 的最新神器Genie 正式登场,这不仅是一个机器人,更是你的3D 设计助手。你曾经想像过,在简单的文字命令下,秒变为3D 设计师的可能性吗? Genie 不仅实现了这一梦想,更让整个设计领域为之震撼。
ADVERTISEMENT
目前,Genie 以研究预览版本的形式免费提供,这就意味着你可以即刻体验它的强大功能。可用于文本和图像的生成,为各行各业带来了极大的便利,对游戏开发、虚拟制作领域的影响正在逐渐浮现,也意味着设计师和创作者将拥有更多探索和实现创意的可能性。
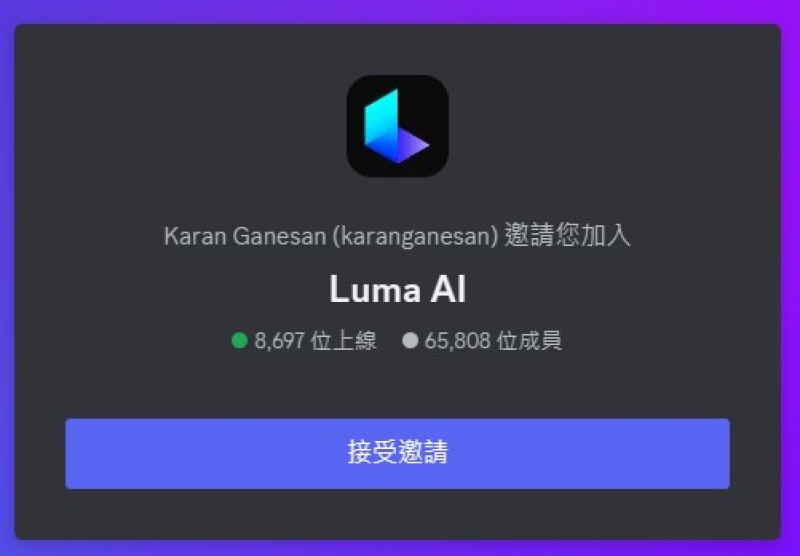
首先,登入Discord,并接受邀请
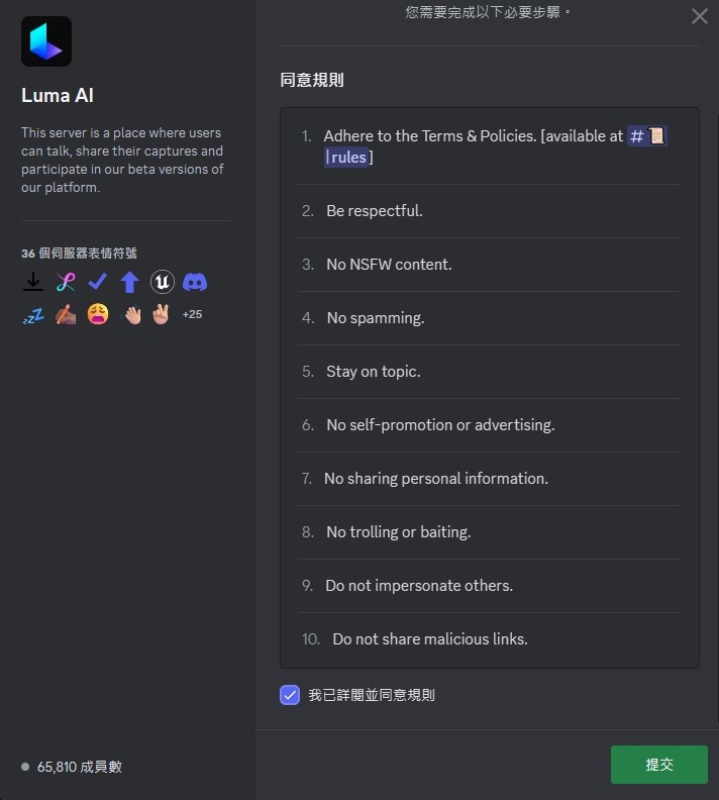
同意使用规则
2.点选左侧房间
点选左侧的任何一个聊天室
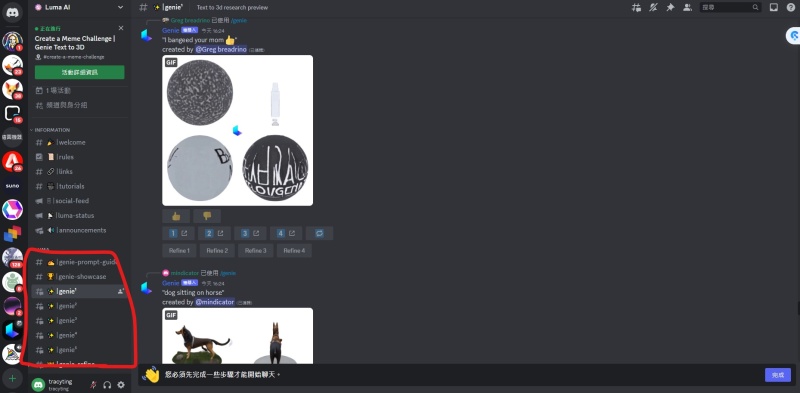
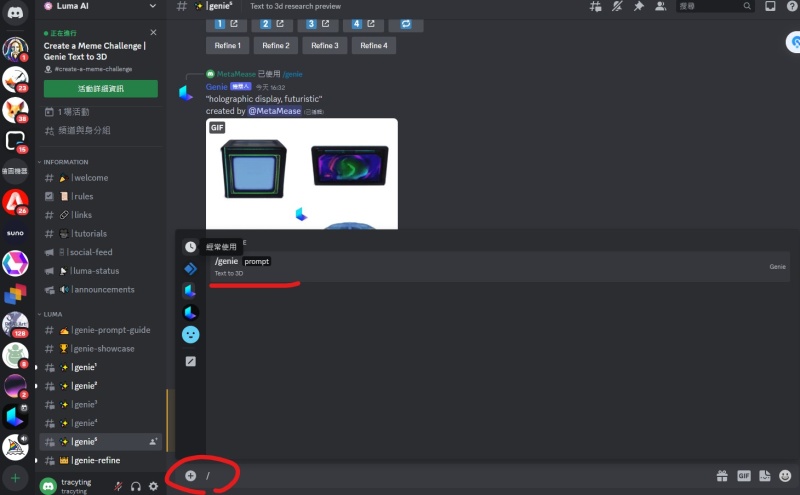
在对话框输入「/」,出现genie,后面输入英文的提示词。
Luma AI
支持格式:luma/ply
使用:开启lumaAI插件后直接导入即可
导入后会渲染生成两种不同效果的模型(粒子):Baked、Dynamic
Baked:根据实拍场景模拟烘焙出的光照效果,不受UE光照影响
Dynamic:受光照影响
在上述两种情况下还会根据导入格式不同再生成两种类型的模型(粒子)Specific to Luma Fields、Specific to Interactive Scenes
Specific to Luma Fields(luma格式才会生成)
蓝图会包含一个自动裁剪版本的中心对象的捕获,并且会渲染出一个合适的天空环境
Specific to Interactive Scenes(导入ply会生成)
不计算运动矢量 以牺牲质量换取性能
导入后会有偏移
调整到下图参数基本处于正向
![]()
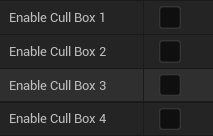
可通过勾选下列四个裁剪方块对模型进行裁剪,裁剪方块的大小和位置可控
LMG_5 粒子瓦片的坐标
LMG_6 贴图的像素
NumGaussians 粒子数量 适当提高粒子数量会在一定程度上提高清晰度 粒子数量一定程度后无论如何添加都不会有效果 反而会加大性能消耗
最大值200W 接近或者大于200W 会看不到粒子效果
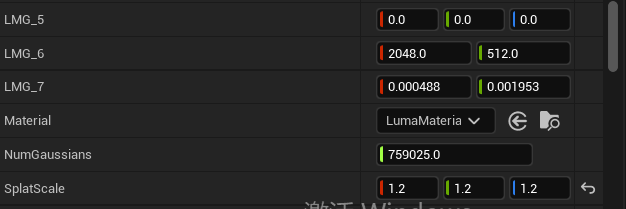
Splat Scale 渲染的粒子大小比率
0.8 - 1.2有适当效果变化 过大过小 展现效果都会变差
3.输入提示词
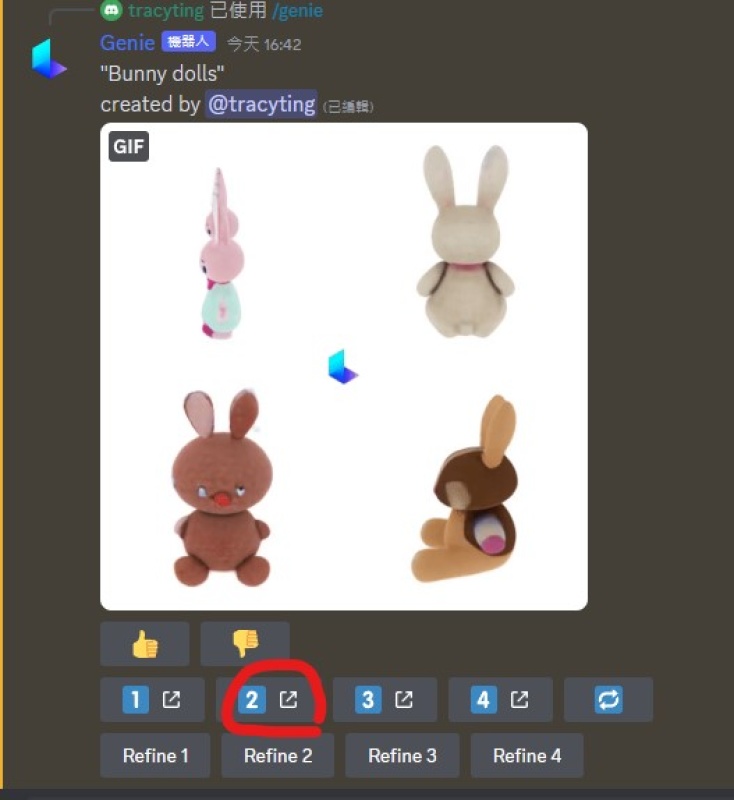
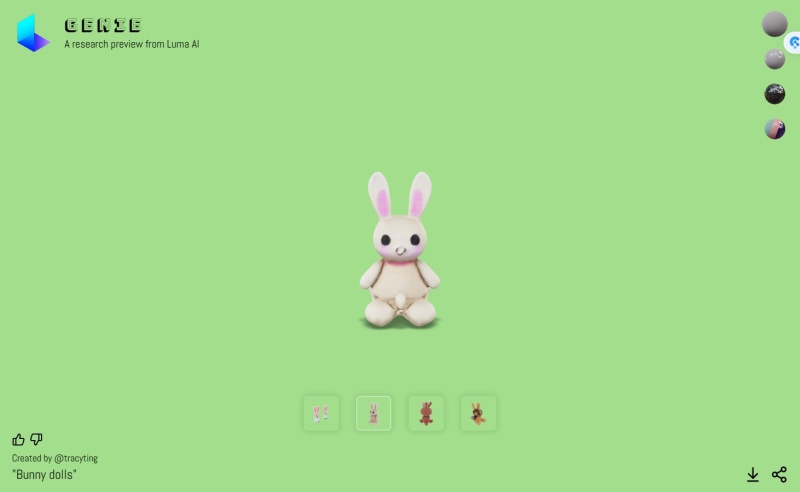
我输入了兔娃娃,就会立刻生成毛茸茸的4张兔子图像,滑鼠移动到上方,即可看3D模型。
生成速度很快,不用1秒,机器人就做好3D模型了
4.开启3D模型介面
点选下方任意数字,开启3D模型介面,右边有4个圈圈,可以更改模型的材质跟纹理。
可以变换成金属材质

塑胶材质

用滑鼠拖曳可以转动模型。

5.可直接下载
右下角可以直接点选下载,档案类型为:3D Object (.glb)
输入简单的钢铁人Iron Man,就能完成3D模型

而且机器人创作的速度非常快。
结语
Genie 的出现让我们看到了3D 设计的全新未来,一个由文字即可创造复杂模型的世界。 3D模型技术具有潜在的创新性和广泛应用,可能会在未来的虚拟制作、游戏开发等领域发挥重要作用。
这技术的进步,将可能会推动相关行业的应用发展。
专业人工智能技术社区

















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









