






本地使用 Llama 2 进行 Langchain 代理和函数调用
代码可以在这里找到 - https://github.com/SandyShah/langchain_agents/tree/main
好吧,这很艰难,而且已经是深夜了。我不会深入讨论实现的许多细节。您可以在 GitHub 上找到参考代码,然后从那里继续。我将分享一些我的经验和片段。
在这篇文章中,我将讲述我第一次开发代理和朋友的经历。这并不像我想象的那么容易。也可以称之为函数调用。众所周知,OpenAI 的 ChatGPT 的知识受限于其所拥有的训练数据集。因此,我们有了 RAG(检索增强生成),我们可以使用预先训练的模型并为它们提供我们的文档或上下文,以生成相关和最新的结果。同样,我们有代理 - 在此,我们使用 LLM 使用函数和 API 将自然语言查询转换为某些操作。例如,可以有一个 wiki 搜索器功能,并且根据用户的查询,LLM 将生成参数并将其传递给 wiki 搜索,获取结果,然后,LLM 将再次使用 wiki 结果和我们的查询来提供相关答案。您可以让代理进行航班预订/跟踪、分析邮件和新闻以及任何事情。新设备 Rabbit R1 具有其中一些功能。它使用后端的各种代理根据我们的自然语言查询采取行动。
在我的上一篇文章中,我演示了如何使用 codeLlama 以自然语言与 pandas 数据框中的数据进行交互。代理更进一步,为了开始探索,我承担了以下任务:
- 我有一个功能,可以转到我的博客文章https://sandeeprshah.blogspot.com/,使用用户提供的关键字(使用博客文章搜索选项),并获取相关文章的标题。
- 我想将其与另一个代理连接起来,但事情并不顺利。在第二个代理中,我为其提供了一个链接,代理只会在新窗口中打开该帖子。
现在,最好的部分是 LLM 或我们的聊天机器人可以随时访问这两个函数,并且根据我们的查询,它将决定运行哪个函数。等等,事情会变得更有趣;它将根据查询提取相关的关键字或链接,并将它们作为参数传递给这些函数。我使用过 llama 2–7B。第一次调用函数时还不错,但 Langchain 中开发工具和代理的方式,它可以进行多次调用,我确实遇到了困难。
例如,一旦我找到相关的博客文章,我就想停止搜索,但有时它会从文章标题中生成一个随机链接并尝试打开它。所以还有很大的改进空间。
我要回顾的另一件事是传递多个参数。当前实现只能传递一个参数,而且当前实现已经过时。我可能需要几周时间才能真正了解这个函数调用和代理,并回来提供更多用途广泛且强大的使用演示。
以下是一些代码片段——
定义函数并将其转换为工具——
class BlogPosts ( BaseModel ):
"""根据用户查询输入提供所有相关博客文章和链接的列表。"""
query: str = Field(description= "要在博客文章中搜索的关键词列表。" )
def get_post_names ( query ):
"""根据用户查询输入提供所有相关博客文章和链接的列表。
输出可以有多个帖子标题。"""
# 删除不需要的文本(如果有)
query = query.replace( 'search term' , '' )
query = query.replace( 'keywords' , '' )
query = query.replace( ':' , '' )
query = query.replace( "'" , '' )
posts=[]
driver = webdriver.Chrome() # 使用您的 chromedriver 路径更新此文件
blog_url = "https://sandeeprshah.blogspot.com/"
blog_url = blog_url+ "search?q=" +query
# 打开博客网站在浏览器中
driver.get(blog_url)
time.sleep( 5 ) # 等待 5 秒钟让页面加载
# 查找所有搜索结果(假设搜索结果以链接形式表示)
search_results = driver.find_elements(By.CSS_SELECTOR, 'h3' )
# 提取并打印搜索结果的标题
print ( "博客文章的标题和链接:" )
for result in search_results:
post_title = result.text
post_link = result.find_element(By.CSS_SELECTOR, 'a' ).get_attribute( 'href' )
post_title_link = post_title+ ":" +post_link
posts.append(post_title)
# 关闭浏览器
driver.quit()
return { "response" : posts}
get_post_names_tool = Tool(
name= "get_posts" ,
func=get_post_names,
description= "提供所有相关博客文章和基于用户查询输入的链接。" ,
args_schema = BlogPosts
)
----------------------------------------------
class SinglePost ( BaseModel ):
"""给定博客标题 - 在新浏览器窗口中查找并打开博客。"""
link: str = Field(description= "要在新窗口中打开的博客文章链接" )
def open_blog_post_new_window ( link ):
"""给定博客文章链接 - 在新窗口中打开"""
# 删除不需要的文本(如果有
) link = link.replace( '搜索词' , '' )
link = link.replace( "'" , '' )
posts=[]
driver = webdriver.Chrome() # 使用您的 chromedriver 路径更新此项
driver.get(link)
time.sleep( 5 ) # 等待 5 秒钟让页面加载
return { "response" : "帖子已打开" }
open_blog_post_tool = Tool(
name= "open_blog_post_new_window" ,
func=open_blog_post_new_window,
description= "给定博客文章链接 - 在新窗口中打开" ,
args_schema = SinglePost
)
-----------------------------------------------------
tools = [
get_post_names_tool,
open_blog_post_tool
]
首先,定义函数及其参数,然后将其全部打包到“工具”中。描述在理解将调用哪个函数以及该函数采用哪些参数方面起着至关重要的作用。您需要对描述进行大量研究。然后,定义代理,如下所示。
PREFIX = "<<SYS>> 您很聪明,可以根据用户查询从函数列表中选择一个函数。\“<<SYS>> 您很聪明,可以根据用户查询从函数列表中选择一个函数。\
一次或在一个查询中只运行一个函数工具。<</SYS>>\n”
agent = initialise_agent(
tools,
llm,
agent= "zero-shot-react-description" ,
verbose=True,
max_iterations = 4,
agent_kwargs={
'prefix': PREFIX,
# 'format_instructions': FORMAT_INSTRUCTIONS,
# 'suffix': SUFFIX
}
)
A = agent.run( "获取与关键词‘马拉松训练’相关的博客文章标题。\
我只想要标题列表。\
请勿打开任何链接。" )
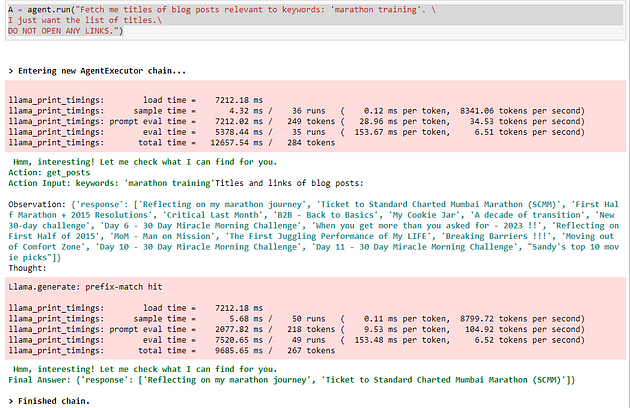
其中一个查询的输出
在上图中,您可以看到我获得了两次输出。一次它获取了一长串标题,然后它在它上面运行了一些东西并只给出了两个标题。这是我仍然难以理解和微调的东西。使用开源——我总是说我必须像婴儿一样看管并手把手地使用提示,但在这里我必须在函数描述、参数传递等方面进行大量尝试。下面,您可以看到,一旦帖子打开,LLM 就不会执行任何进一步的操作。
顺便说一句 — 已经有大量新的开源模型发布,我正尽力坚持使用 Llama 7B 和该系列。新模型并不总是能与当前设置无缝协作,需要花费大量时间弄清楚依赖关系等 — 所以我暂时坚持使用 llama 系列。
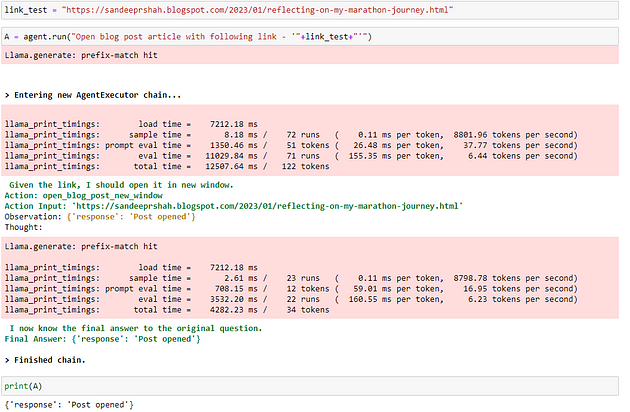
在新窗口中打开链接
有大量新的开源模型发布,我正尽力坚持使用 Llama 7B 和该系列。新模型并不总是能与当前设置无缝协作,需要花费大量时间弄清楚依赖关系等 — 所以我暂时坚持使用 llama 系列。
[外链图片转存中…(img-0Po3oRSV-1721985907399)]
在新窗口中打开链接
很高兴看到经纪人未来的可能性?深入研究 GenAI 和 LLM 领域,让我们一起探索无限潜力!分享您的旅程和成功项目;您的经验可以以我们从未想象过的方式激励和推动创新。与我们联系,让我们一起踏上这段令人振奋的旅程。
博客原文:专业人工智能社区















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









