






上下文敏感性:使用 Flash Ranking 提高语言模型的性能

来源:作者
探索语言模型在处理长篇文档时面临的挑战,导致性能下降,并探索解决这些问题的策略。
在快速发展的人工智能世界中,语言模型的性能是一个热门话题。这些模型的应用范围从聊天机器人到内容创建,正在改变我们与技术的互动方式。其效率的一个关键方面是它们能够快速准确地对信息进行排序和检索。以下是构建 RAG 系统的标准表示,我们加载文档,从中提取文本,将其存储在矢量数据库中,并根据查询检索信息。
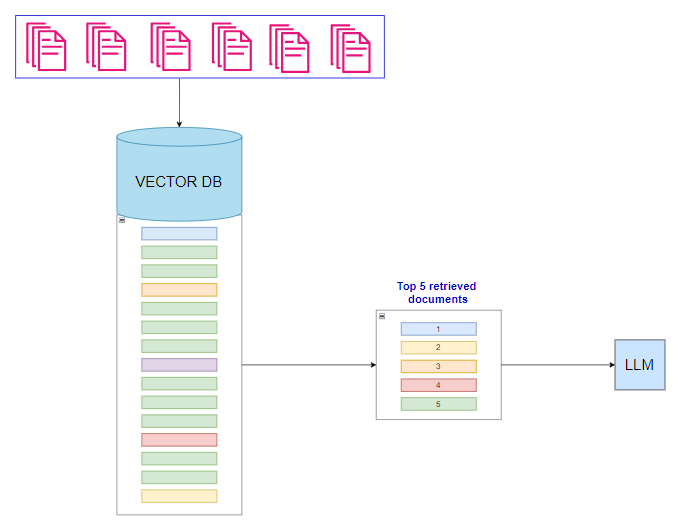
来源:作者 | 标准的 RAG 系统和检索流程
RAG 效率的关键要素在于它能够快速准确地检索信息。这就是 Flash Ranking 变得必不可少的地方。Flash Ranking 是一种新方法,可提高语言模型中信息检索的速度和精度,克服传统排名系统经常面临资源消耗和速度缓慢的局限性。与此讨论密切相关的一个概念是“迷失在中间”问题,其中嵌入在长段落中的重要信息经常被传统检索系统忽视。在下图中,我们观察到模型在开头和结尾处更好地捕捉上下文,但在中间,性能有所下降。以下是论文的快照 —迷失在中间:语言模型如何使用长上下文
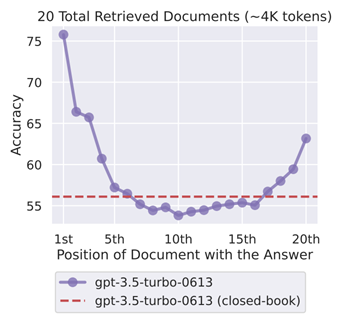
来源:https://arxiv.org/pdf/2307.03172
这个问题凸显了对更有效的排名机制的需求,这种机制可以精确定位和提升关键数据,而不管其在文本中的位置如何。Flash Ranking 通过确保即使是最深层嵌入的信息也能被有效检索和利用来解决此问题。本博客将深入探讨 Flash Ranking 的机制,探索其优势及其对语言模型性能的影响。以下是使用 FalshRank 开发 RAG 系统的更高级技术。
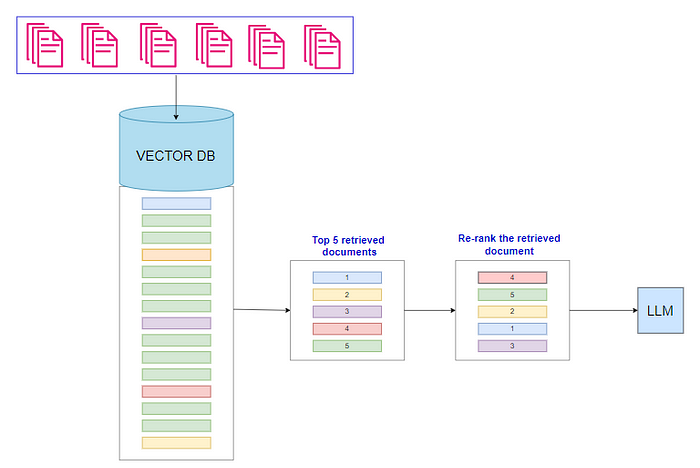
来源:作者 | A Re-ranking / FlashRank RAG 系统和检索流程
我们旨在测试两种方法:传统方法和重新排名FlashRank 方法。使用相同的源文档和查询,我们将比较结果以了解每种方法在内部如何发挥不同的作用。
导入必要的库
导入pandas作为pd
导入pickle
导入json
导入faiss从langchain_huggingface
导入o s从langchain导入HuggingFaceEndpoint。text_splitter从langchain导入RecursiveCharacterTextSplitter。llms从langchain导入OpenAI。chains从langchain导入RetrievalQA。document_loaders从langchain导入PyPDFLoader。document_loaders从langchain导入DirectoryLoader、TextLoader。vectorstores从InstructorEmbedding导入FAISS从langchain导入INSTRUCTOR。embeddings从langchain导入HuggingFaceInstructEmbeddings。prompts从langchain_core导入ChatPromptTemplate、PromptTemplate。output_parsers从flashrank导入StrOutputParser。Ranker导入Ranker 、RerankRequest
数据加载
我们将使用为本博客创建的简短内容文档来讨论[G20 及其目的](https://github.com/amitvkulkarni/Blogs/blob/main/Generative AI/RAG with MultiQueryRetriever/Politics.txt)。
loader = DirectoryLoader(f"/content/data", glob="*.txt",“/content/data”,glob = “*.txt”,
loader_cls = TextLoader)
文档 = loader.load()
文档

来源:作者 | Loaded document
文档处理和嵌入
**我们将使用RecursiveCharacterTextSplitter*将文档分成块,然后使用Huggingface 的“hkunlp/instructor-xl”***嵌入块。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100,
chunk_overlap=10)
文本 = text_splitter.split_documents(文档)
文本

来源:作者 | 文件拆分后
我们将使用 HuggingFace 模型对每个块进行嵌入。
从 langchain.embeddings 导入 HuggingFaceInstructEmbeddings导入 HuggingFaceInstructEmbeddings
讲师嵌入 = HuggingFaceInstructEmbeddings(
模型名称 = “hkunlp/instructor-xl”)
使用 FAISS 作为向量数据库
我们将利用 Faiss 来存储和检索文档。或者,Chroma DB 是另一个选择。我们的计划包括创建一个检索器对象,根据问题获取前 10 个相关块。
db_instructEmbedd = FAISS.from_documents(texts, tutor_embeddings)
检索器 = db_instructEmbedd.as_retriever(search_kwargs={"k": 10})"k" : 10})
猎犬
让我们先用一个示例问题来测试设置。结果被转换成数据框以便于阅读。我们注意到有 10 行,每行显示一组检索到的文档。
question = “为什么所有国家都要开会,会议的主题是什么?”“为什么所有国家都要开会,会议的主题是什么?”
doc = trieser.get_relevant_documents(question)
doc

使用 FlashRank 构建 RAG 系统
该过程遵循熟悉的步骤:加载数据、处理数据、生成嵌入、将其存储在向量数据库中以及检索信息。但是,我们在这里通过重新排序检索到的块来增强该过程,以捕获最相关的信息并保持上下文完整性。
从 flashrank 导入 Ranker、RerankRequest
ranker = Ranker()
rerankrequest = RerankRequest(query=question, passages=formatted_data)
flashrank_results = ranker.rerank(rerankrequest)
flashrank_results
df_re_rank = pd.DataFrame(flashrank_results)[['id', 'text']][['id', 'text']]
df_re_rank.rename ( columns = { 'id' : 'Re-rank-id' , 'text' : 'Re-rank-text' },
inplace = True)
df_re_rank

来源:作者 | FlashRank 中的文档块排名
通过传统方法生成 LLM 输出
之前,我们从文档中提取了 10 个相关部分。现在,让我们使用这些部分通过 HuggingFace 的 Mistral 模型生成结果。
从 langchain_core.runnables 导入 RunnablePassthrough
repo_id="mistralai/Mistral-7B-Instruct-v0.2"“mistralai/Mistral-7B-Instruct-v0.2”
llm=HuggingFaceEndpoint(repo_id=repo_id,max_length=128,
temperature=0.7,token='HF_TOKEN')
template = "" "仅根据以下上下文回答问题:
{context}
问题:{question}
" ""
# 从模板创建提示
prompt = ChatPromptTemplate.from_template(template)
chain = (
{ "context" : trieser, "question" : RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
response = chain.invoke(question)
print(response)
#---------------------------------------------------------------------
输出:
回答:各国在二十国集团论坛背景下举行会议,
以促进多极化,扩大发展中国家在全球治理中的作用
,并解决全球问题。在印度担任 G20 主席国期间,
各方努力在国际关系中引入更多平等
,并在国际体系中推行改革。G20 议程需要
更广泛的国际伙伴关系,而且需要由全球南方国家领导
。G20 峰会级别从财政部长
级别提升,以更有效地解决这些问题。此外,
非洲联盟被纳入 G20 常任观察员。金砖国家是一群
非西方国家,正在 G20 内部不断扩大,以抵制其他
建立共识的平台。
从 FlashRank 生成 LLM 输出
让我们使用 FlashRank 执行相同的步骤,但略有不同:10 个块的优先级会有所不同,从而导致排名与传统方法不同。
从langchain.retrievers 导入 ContextualCompressionRetriever
从langchain.retrievers.document_compressors 导入 FlashrankRerank
从langchain.chains 导入 RetrievalQA
compression = FlashrankRerank (top_n = 10 )
compression_retriever = ContextualCompressionRetriever (
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke ( question ) compressed_docs chain_reranked = RetrievalQA.from_chain_type ( llm =llm, triester=compression_retriever) chain_reranked.invoke (question) #---------------------------------------------------------------输出:{ 'query': '为什么所有国家都要开会,会议内容是什么?','result':'包括全球南方国家在内的国家正在 G20 和金砖国家论坛的背景下举行会议。二十国集团正在扩大其范围,以抵制西方国家的主导地位并促进多极化。二十国集团的议程现在包括国际关系中更加公平以及发展中国家在全球治理中发挥更大作用。作为两个论坛的成员,印度正在举办全球南方之声峰会,并将二十国集团论坛提升到峰会级别来解决这些问题。' }
检索到的块的等级比较
研究这两种方法的排名总是很有趣的。以下是一些观察结果。
- 传统方法生成了 109 个字的回复,回答了我们的问题。最重要的是,上下文没有丢失,回复也很有意义。
- FashRank 方法产生的回答较短,只有 83 个字,且上下文完整,而且回答更为尖锐。

来源:作者 | 两种方法的排名比较
归根结底,这一切都是为了尝试各种模型、提示和技术。采用哪种方法取决于项目目标、预算、资源和其他因素。同时,让我们欣赏技术的进步并继续尝试。
完整的笔记本***RAG_FlashRank.ipynb可以从***[GitHub](https://github.com/amitvkulkarni/Blogs/tree/main/Generative AI)访问
结论
综上所述,FlashRank 是一种通过对数据检索进行优先级排序和细化来提高语言模型性能的技术,可以增强语言模型的最终输出。这种方法解决了信息检索速度慢和文本块中间部分被忽略等挑战,确保关键信息的有效利用。
AG_FlashRank.ipynb可以从***[GitHub](https://github.com/amitvkulkarni/Blogs/tree/main/Generative AI)访问
结论
综上所述,FlashRank 是一种通过对数据检索进行优先级排序和细化来提高语言模型性能的技术,可以增强语言模型的最终输出。这种方法解决了信息检索速度慢和文本块中间部分被忽略等挑战,确保关键信息的有效利用。
我希望你喜欢这篇文章并发现它很有用。
博客原文:专业人工智能社区















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









