









有监督学习:建立映射关系 f:x->y
无监督学习:从无标签的数据中学习有用的模式
一、聚类
将样本中相似的样本分配给相同的类/簇
样本间距/相似性:L1、L2距离;余弦距离;相关系数;汉明距离
常见的聚类任务:图像分割;文本聚类;社交网络分析
①类/簇:可以理解为一组相似的样本,但是并无严格定义
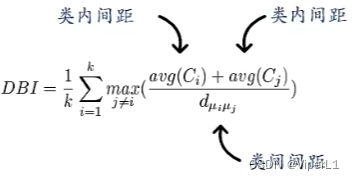
②类内间距:样本间最大距离:
样本间最大距离:
③样本距离:样本间最短距离:
样本均值间距离:
④聚类效果评价:外部指标

JC系数= (TP除以总数)
内部指标
1.K均值聚类
①确定K值,随后随机生成K个类中心
②根据点到类中心的距离,将空间划分为K个区域,同一个区域内划分为一个类
③根据划分重新计算每个类的类中心
④由新的类中心重新划分区域,随后重复③、④。直至收敛(类中心不再变化)
K均值聚类的目标函数
其中
为第 i 个簇
的均值向量
K的选择:K为超参数。

K↑,平均半径↓。一般选择平缓段的K
类中心的初始化:
①大于最小间距的随机点\样本点
②K个相互距离最远的样本点
③K个等距网格点
优点:实现简单、时间复杂度低
缺点:K值的选择、主要适合凸集、初始值影响较大
2.层次聚类
通过计算不同数据点的相似度来创建有层次的嵌套聚类树
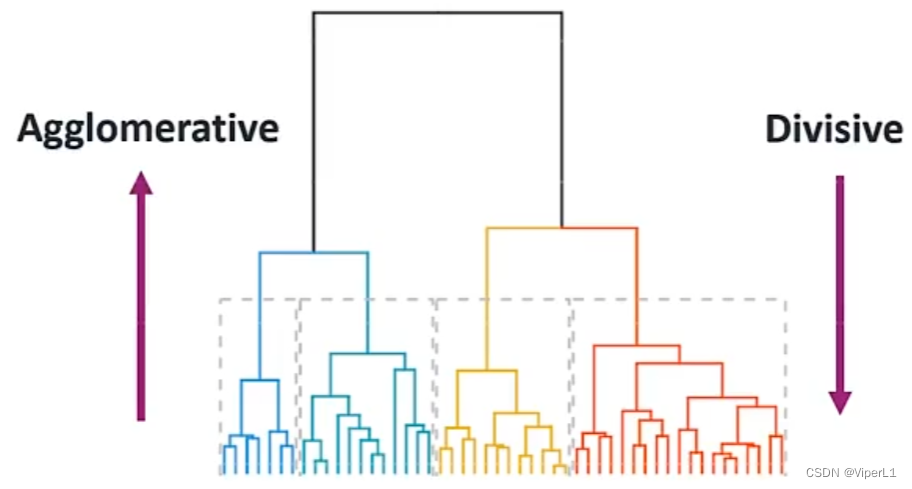
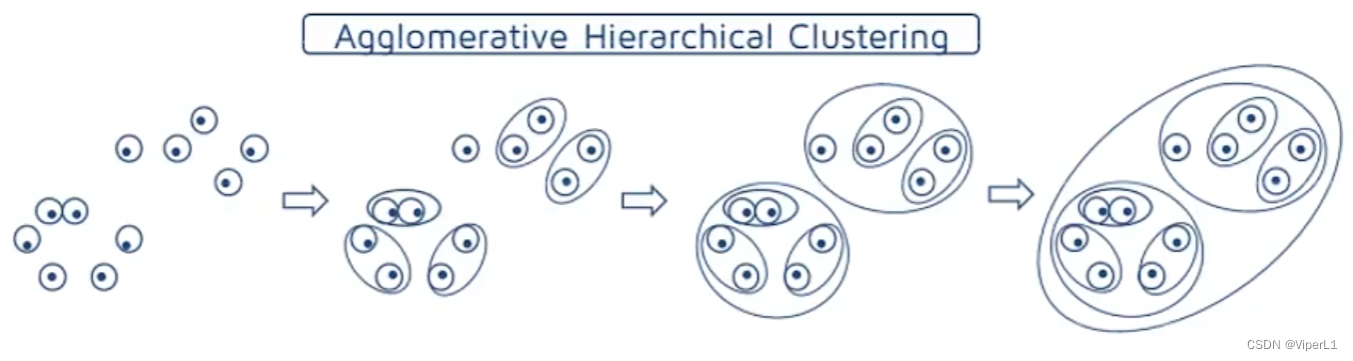
聚合过程:属于自底向上
①将每个样本分到单独的类
②通过迭代将其相似的不断聚合(计算两两类的距离,将距离最小的两个合并)
分裂过程:属于自顶向下
①将所有样本划分为同一个类
②通过迭代使其不断分裂(计算两两类的距离,找出两个距离最远的样本a,b,计算其他点到a,b的距离,将其划分到较近<比如dis(a)<dis(b)>的簇中)

优点:简单且便于理解
缺点:合并点/分裂点难以选择;不能撤销操作;不适合大数据;执行效率低
二、特征学习
目的:特征提取、去噪、降维、数据可视化
1.主成分分析
原始数据可能存在的问题:维度过高、冗余性过高(难以学习);可以通过降维的方法解决
①线性投影:
②并满足:
③优化准则->最大投影方差:转换后数据的方差最大(尽可能保存原数据信息)
投影后的方差:
目标函数: 对目标函数求导=0可得
最小重构误差
2.编码与稀疏编码

过完备:基向量个数远大于其支撑空间维度,这种基向量一般不具备独立、正交等性质
稀疏编码:原始向量中的特征由少数基向量加权构成
为稀疏性衡量函数,
是一个超参数,用以控制稀疏性强度

交替优化:

优点:降低后续计算量、可解释行强、便于特征选择
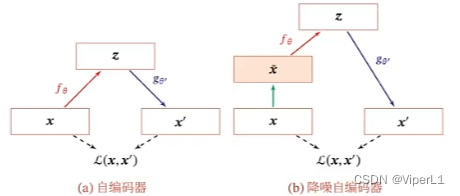
3.自编码器
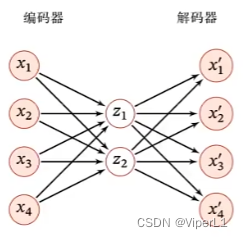
目标函数:重构错误
稀疏自编码器:给自编码器的隐藏层单元加上稀疏限制
降噪自编码器:通过引入噪声来增加编码鲁棒性的自编码器
4.自监督学习
自监督学习依旧是X->Y的映射学习(而非类聚)
通过人为对X的扰动,进行学习(比如旋转图像)
三、密度估计
1.参数密度估计
先假设随机变量服从某种分布,再通过训练样本来估计分布的参数
最大似然估计:
存在的问题
①模型选择问题:如何选择密度函数
②不可观测变量问题:难以准确估计数据的真实分布
③维度灾难问题:样本随维度增加而指数增加;样本不足时会出现过拟合
2.非参数密度估计
不假设随机变量服从某种分布,通过样本空间的划分来估计近似数据的概率密度
原型公式:
其中:K为落入R中的样本数量;N为训练样本;实质上是由推导而来
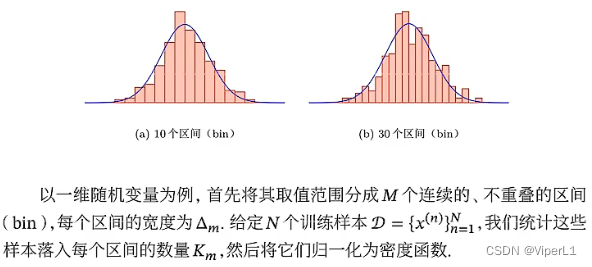
①直方图法
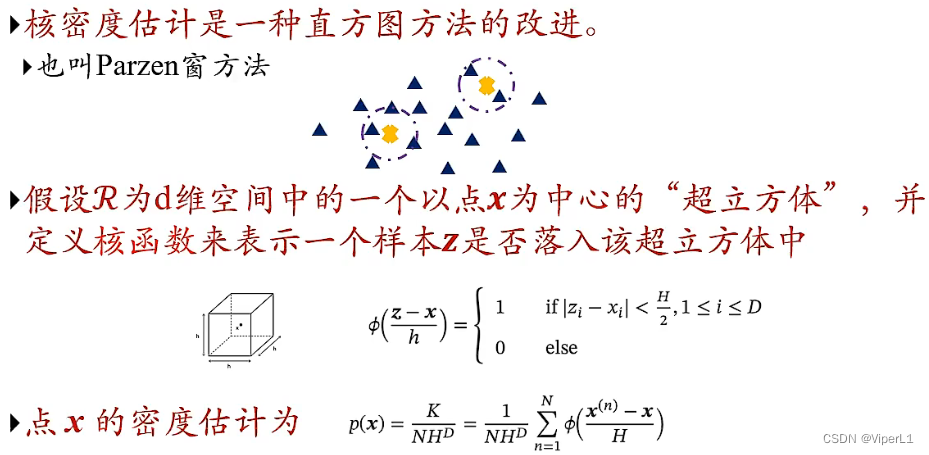
②核密度估计
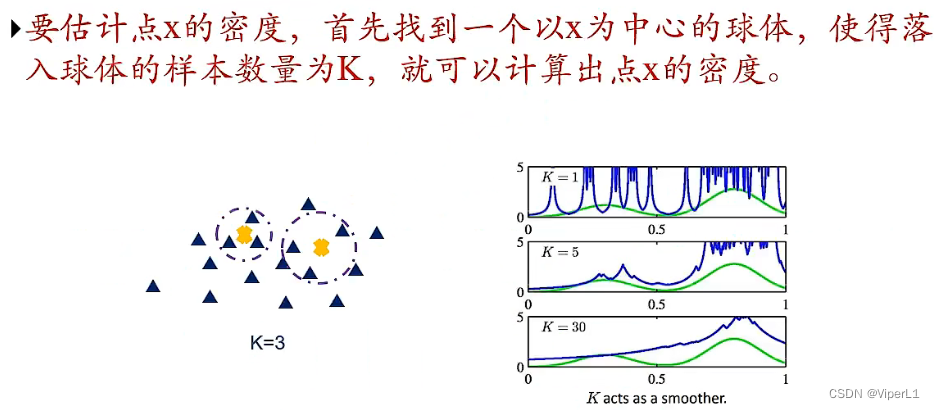
③K近邻方法
优势:非参数密度估计不需要保留整个训练集,便于计算和存储
四、半监督学习
1.区别
监督学习:提供任务相关的标签(打标签费时费力且数量有限)
无监督学习:不用打标签,数量充足(但仅限于特殊任务)
2.模式
自训练
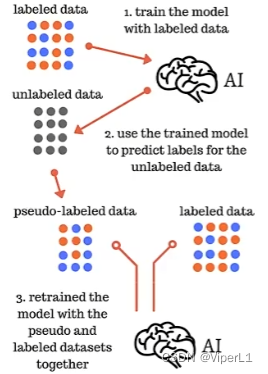
先使用监督学习训练模型
再使用模型进行分类
最后将这个簇标注后混合原来的数据集再次用于模型训练
协同训练
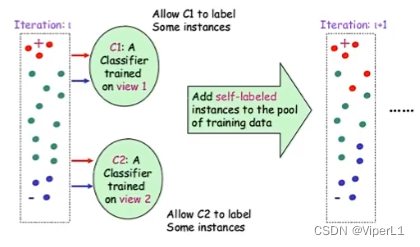
采用n种不同的方式训练分类器,让这些分类器互相分对方的数据















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









