









一、概述
一般的有监督迁移学习分为以下三种:
①将训练好的模型作为特征抽取模块(例如以resnet进行特征提取)
②在一个相关的任务中训练后直接后直接使用(例如gpt)
③在训练好的模型基础上进行微调
此外还有无监督学习的方式
zero-shot:没有任何标签信息
few-shot:仅能获取少量标签信息
二、微调
一般来说,神经网络可以分为两个部分:编码器(Encoder)和解码器(Decoder)。编码器的作用是将原始的像素转换为语义空间中线性可分的语义特征(特征嵌入);解码器的作用是将编码器的语义特征映射为标号(线性分类器)。

预训练模型(Pre-trained model):在一个较大的数据集上训练的模型(如ImageNet),该模型一般拥有较好的泛化能力。作为对比,一般从零开始训练神经网络,网络中的参数都是随机初始化,很难调优。
具体做法如下:
①构建一个新的模型,该模型的架构应该与预训练模型一致
②新模型初始化时,编码器(Encoder)直接加载预训练模型中的权重,解码器(Decoder)使用随机初始化。
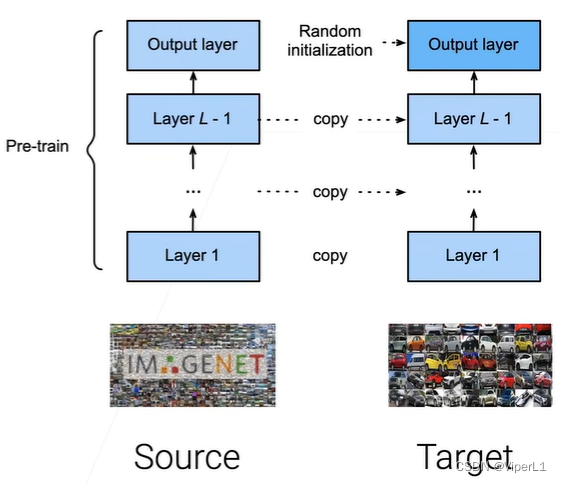
③-1限制搜索空间:控制训练轮次和学习率(因为预训练模型本身就在最优解附近,需要避免偏移过多)
③-2冻结底层:底层网络一般学习到一些局部特征,而越往上层学习到的东西越是全面。具体做法是将下面几层进行冻结(学习率置0)
三、预训练模型的获取
以Pytorch为例,可以在访问此网站:Pytorch预训练模型,同时模型转换可以参考之前的文章
[PyTorch]预训练权重的转换![]() https://blog.csdn.net/weixin_37878740/article/details/130259766 或者直接调用timm包
https://blog.csdn.net/weixin_37878740/article/details/130259766 或者直接调用timm包
import timm
from torch import nn
model = timm,create_model('resnet50',pretrained=True)
model.fc = nn.Linear(model.fc.in_features,n_classes)














 3146
3146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









