






Efficient Neural Architecture Search via Parameter Sharing
提出了一种高效的神经结构搜索(ENAS)方法,它是一种快速、廉价的模型自动设计方法。在ENAS中,控制器通过在大型计算图中搜索最优子图来发现神经网络结构。利用策略梯度训练控制器,选择一个子图,使验证集上的期望报酬最大化。同时对所选子图对应的模型进行训练,以最小化典型交叉熵损失。在子模型之间共享参数允许ENAS提供强大的经验性能,同时比现有的自动模型设计方法使用更少的GPU时间,尤其是比标准神经架构搜索少1000倍。
1. Introduction
NAS在计算上是昂贵和耗时的,例如Zoph等人。(2018)使用450 GPU 3-4天(即32400-43200 GPU小时)。同时,使用更少的资源往往会产生不那么引人注目的结果(Negrinho&Gordon,2017; 贝克等人,2017a)。我们观察到,NAS的计算瓶颈是训练每个子模型收敛,只测量其精度,而丢弃所有训练过的权重。
这项工作的主要贡献是通过强制所有子模型共享权重来提高NAS的效率,从而避免从头训练每个子模型到收敛。这个想法有明显的复杂性,因为不同的子模型对权重的利用不同,但是之前关于转移学习和多任务学习的工作鼓励了这个想法,这些工作建立了一个特定模型在特定任务上学习到的参数可以用于其他任务上的模型,几乎没有修改。
重要的是,在我们所有的实验中,我们都使用了单一的Nvidia GTX 1080Ti GPU,架构搜索不到16小时。与NAS相比,这减少了1000倍以上的gpu小时。由于其高效,我们将我们的方法命名为高效神经结构搜索(ENAS)。
2. Methods
ENAS的核心思想是观察到NAS最终迭代的所有图都可以看作是一个更大的图的子图。换句话说,我们可以用一个有向无环图(DAG)来表示NAS的搜索空间。图2展示了一个通用的示例DAG,其中可以通过获取DAG的子图来实现体系结构。直观地说,ENAS的DAG是NAS搜索空间中所有可能的子模型的叠加,节点表示局部计算,边缘表示信息流。每个节点的本地计算都有自己的参数,这些参数仅在激活特定计算时使用。因此,ENAS的设计允许在搜索空间中的所有子模型(即体系结构)之间共享参数。

图2。图形表示整个搜索空间,而红色箭头定义搜索空间中的模型,该模型由控制器决定。这里,节点1是模型的输入,而节点3和6是模型的输出。
在下面,我们用一个例子来帮助讨论ENAS,这个例子说明了如何从指定的DAG和控制器设计递归神经网络的单元(第2.1节)。然后,我们将解释如何训练ENAS以及如何从ENAS的控制器派生体系结构(第2.2节)。最后,我们将解释设计卷积架构的搜索空间(第2.3和2.4节)。
2.1. Designing Recurrent Cells
为了设计递归单元,我们使用了一个具有N个节点的DAG,其中节点表示本地计算(local computations),边缘表示N个节点之间的信息流。ENAS的控制器是一个RNN,它决定:1)哪些边被激活,2)在DAG的每个节点上执行哪些计算。我们的RNN单元搜索空间设计不同于Zoph&Le(2017)中的RNN单元搜索空间,作者将其架构的拓扑结构固定为二叉树,只学习树中每个节点的操作。相比之下,我们的搜索空间允许ENAS在RNN单元中设计拓扑和操作,因此更加灵活。

图1。在我们的搜索空间中有4个计算节点的递归单元的一个例子。左:对应于循环细胞的计算DAG。红边表示图中的信息流。中间:循环细胞。右:控制器RNN的输出,结果是中间的单元格和左边的DAG,节点3和节点4从来没有被RNN采样过,因此它们的结果是平均的,并被当作单元的输出。
为了创建一个递归单元,控制器RNN对N个决策块进行采样。在这里,我们通过一个简单的示例递归单元(N=4个计算节点)来说明ENAS机制(如图1所示)。设xt为递归细胞的输入信号(如word embedding),ht−1为前一时间步长的输出。我们抽样如下。
一。在节点1:控制器首先采样激活函数。在我们的例子中,控制器选择tanh激活函数,这意味着递归细胞的节点1应该计算
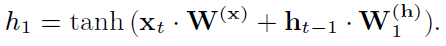
2。在节点2:然后,控制器对先前的索引和激活函数进行采样。在我们的示例中,它选择前面的索引1和激活函数ReLU。因此,单元的节点2计算

三。在节点3:控制器再次采样先前的索引和激活函数。在我们的示例中,它选择前面的索引2和激活函数ReLU。因此,

四。在节点4:控制器再次对以前的索引和激活函数进行采样。在我们的示例中,它选择前面的索引1和激活函数tanh,从而

5。对于输出,我们简单地平均所有松散端,即未被选作任何其他节点输入的节点。在我们的示例中,由于索引3和4从未被采样为任何节点的输入,因此递归细胞使用其平均值(h3+h4)/2作为其输出。换句话说,ht = (h3 + h4)/2.
在上面的例子中,我们注意到,对于每对节点j < ℓ, 都有一个独立的参数矩阵 W ℓ , j ( h ) W_{ℓ,j}^{(h)} Wℓ,j(h) 如示例所示,通过选择前面的索引,控制器还决定使用哪些参数矩阵。因此,在ENAS中,搜索空间中的所有递归单元格共享同一组参数。
我们的搜索空间包含指数数量的配置。具体来说,如果递归细胞有N个节点,并且我们允许4个激活函数(即tanh、ReLU、identity和sigmoid),那么搜索空间有4N×N!配置。在我们的实验中,N=12,这意味着在我们的搜索空间中大约有1015个模型
2.2. Training ENAS and Deriving Architectures
我们的控制器网络是一个有100个隐藏单元的LSTM。该LSTM通过softmax分类器以自回归的方式对决策进行采样:前一步中的决策作为嵌入到下一步中的输入进行反馈。第一步,控制器网络接收空嵌入作为输入。
在ENAS中,有两组可学习参数:用θ表示的控制器LSTM参数和用ω表示的子模型的共享参数。ENAS的训练过程包括两个交织阶段。第一阶段用所有训练数据集训练子模型的共享参数ω。同时,对于CIFAR-10,在45000幅训练图像上训练ω,将其分成128个小批量,其中使用标准的反向传播计算 ∇ω。第二阶段训练θ,控制器LSTM的参数,在我们的实验中,通常设置为2000步。这两个阶段在ENAS训练期间交替进行。详情如下。
Training the shared parameters ω of the child models.
在这一步中,我们固定了控制器的策略π(m;θ)并对ω执行随机梯度下降(SGD)以最小化期望损失函数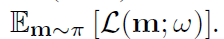 这里,L(m;ω)是标准交叉熵损失,根据小批量训练数据计算出来,模型m从π(m;θ)采样。梯度是用蒙特卡罗估计来计算的
这里,L(m;ω)是标准交叉熵损失,根据小批量训练数据计算出来,模型m从π(m;θ)采样。梯度是用蒙特卡罗估计来计算的

式中,mi从π(m;θ)采样,如上所述。方程1提供了梯度的无偏估计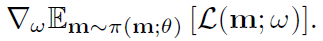 然而,这个估计比标准SGD梯度有更高的方差,其中m是固定的。然而,这也许是令人惊讶的,我们发现M=1工作得很好,也就是说,我们可以使用从π(M;θ)采样的任何单个模型M的梯度来更新ω。如前所述,我们在整个训练数据上训练ω。
然而,这个估计比标准SGD梯度有更高的方差,其中m是固定的。然而,这也许是令人惊讶的,我们发现M=1工作得很好,也就是说,我们可以使用从π(M;θ)采样的任何单个模型M的梯度来更新ω。如前所述,我们在整个训练数据上训练ω。
Training the controller parameters θ.
在这一步中,我们固定ω并更新策略参数θ,以最大化期望报酬 我们使用Adam优化器(Kingma&Ba,2015),为此 梯度是用增强法(Williams,1992)计算的,用移动平均基线来减少方差。奖励R(m,ω)是在验证集上计算的,而不是在训练集上计算的,以鼓励ENAS选择推广性好的模型,而不是过拟合训练集的模型。在我们的图像分类实验中,奖励函数是对一小批验证图像的准确性。
我们使用Adam优化器(Kingma&Ba,2015),为此 梯度是用增强法(Williams,1992)计算的,用移动平均基线来减少方差。奖励R(m,ω)是在验证集上计算的,而不是在训练集上计算的,以鼓励ENAS选择推广性好的模型,而不是过拟合训练集的模型。在我们的图像分类实验中,奖励函数是对一小批验证图像的准确性。
Deriving Architectures.
我们讨论了如何从经过训练的ENAS模型中获得新的体系结构。我们首先从训练策略π(m,θ)中抽取几个模型。对于每个抽样模型,我们计算从验证集中抽样的单个小批量的报酬。然后,我们只拿奖励最高的模特从头开始重新训练。通过从头开始训练所有抽样模型,并在单独的验证集上选择性能最高的模型,可以改进我们的实验结果,这与其他工作一样(Zoph&Le,2017;Zoph等人,2018;Liu等人,2017;2018)。然而,我们的方法在经济性更高的同时,也产生了类似的性能。
2.3. Designing Convolutional Networks

图3。我们的搜索空间中的一个卷积单元的一个例子,它有4个计算节点,表示卷积网络中的4层。顶部:控制器RNN的输出。左下角:与网络结构相对应的计算DAG。红色箭头表示活动的计算路径。右下角:完整的网络。虚线箭头表示跳过连接。
我们现在讨论卷积结构的搜索空间,回想一下,在递归单元的搜索空间中,控制器RNN在每个决策块上采样两个决策:1)连接到哪个前节点,2)使用哪个激活函数。在卷积模型的搜索空间中,控制器RNN还对每个决策块上的两组决策进行采样:1)连接到以前的哪些节点,2)使用什么计算操作。这些决策构成了卷积模型的一层。要连接的先前节点的决定允许模型形成跳跃连接(He等人,2016a;Zoph&Le,2017)。具体地说,在k层,对多达k-1个相互不同的先前索引进行采样,从而在k层导致 2 k − 1 2^{k-1} 2k−1个可能的决策。我们在图3中提供了对卷积网络进行采样的示例。在这个例子中,在k=4层,控制器对以前的索引{1,3}进行采样,因此第1层和第3层的输出沿着它们的深度维度连接起来并发送到第4层。
同时,使用哪种计算操作的决定将特定层设置为卷积或平均池化或最大池化。控制器的6个操作是:卷积核尺寸为3×3和5×5的卷积,卷积核尺寸为3×3和5×5的可分离卷积(Chollet,2017),以及3×3的最大池和平均池。正如递归细胞一样,我们的ENAS卷积网络中每一层的每个操作都有一组不同的参数。
将所描述的一组决策总共进行L次,我们可以对L层的网络进行采样。由于所有的决策都是独立的,因此在搜索空间中存在6L×2L(L-1)/2个网络。在我们的实验中,L=12,得到1.6×1029个可能的网络。
2.4. Designing Convolutional Cells
与其设计整个卷积网络,不如设计更小的模块,然后将它们连接起来形成网络(Zoph等人,2018)图4说明了这种设计,其中将设计正常卷积单元和缩减单元架构。我们现在讨论如何使用ENAS来搜索这些单元的架构。

图4。连接3个块,每个块与N个卷积单元和1个缩减单元,做出最终网络。
我们利用带有B个节点的ENAS计算DAG来表示单元中局部发生的计算。在这个DAG中,节点1和节点2被视为单元的输入,这是最终网络中前两个单元的输出(见图4)。对于剩余的B-2节点中的每一个,我们要求控制器RNN做出两组决策:1)将前两个节点用作当前节点的输入,2)将两个操作应用于两个采样节点。这5种操作分别是:identity,核大小为3×3的可分离卷积,核大小为3×3的平均池和最大池。在每个节点上,对前一个节点及其对应的操作进行采样后,将这些操作应用于前一个节点,并把他们的结果相加。


图5。卷积单元上搜索空间控制器的运行示例。顶部:控制器的输出。在我们的卷积单元搜索空间中,节点1和节点2是单元的输入,因此控制器只需设计节点3和节点4。左下:对应的DAG,其中红色边表示激活的连接。右下角:根据控制器样本的卷积单元。
和前面一样,我们用一个例子来说明搜索空间的机制,这里有B=4个节点(参见图5)。详情如下。
一。节点1、2是输入节点,因此不需要对它们进行决策。设h1,h2为这些节点的输出。
二。在节点3:控制器采样前两个节点和两个操作。在图5左上角,它对节点2、节点2、可分离conv 5x5和identity进行采样。这意味着h3=sep conv 5x5(h2)+id(h2)。
三。在节点4:控制器采样节点3、节点1、平均池3x3和sep conv 3x3。这意味着h4= avg pool 3x3(h3)+sep conv 3x3(h1)。
四。因为除了h4以外的所有节点都被用作至少另一个节点的输入节点,唯一的松散端,h4,被当作单元的输出。如果有多个松散的末端,它们将沿着深度维度连接起来,形成单元格的输出
也可以从我们讨论的搜索空间中实现一个缩减单元,方法很简单:1)从搜索空间中采样计算图,2)以2的步长应用所有操作。因此,归约单元将其输入的空间维度减少2倍。根据Zoph等人。(2018年),我们对基于卷积单元的约简单元进行采样,从而使控制器RNN总共运行2(B-2)个块。
最后,我们估计了这个搜索空间的复杂性。在节点i(3≤i≤B)处,控制器可以从i-1上一个节点中选择任意两个节点,并从5个操作中选择任意两个操作。因为所有的决定都是独立的,所以有
( 5×(B-2)!)2个可能的细胞。由于我们独立地对卷积单元和归约单元进行采样,因此搜索空间的最终大小为(5×(B-2)!)4。与我们的实验一样,在B=7的情况下,搜索空间可以实现1.3×1011最终网络,使得它明显小于整个卷积网络的搜索空间(第2.3节)。
Training details.
共享参数ω采用Nesterov动量(Nesterov,1983)进行训练,其中学习率遵循lmax=0.05、lmin=0.001、T0=10和Tmul=2的余弦时间表(Loshchilov&Hutter,2017)。每个架构搜索运行310个阶段。我们用He初始化初始化ω(He et al.,2015)。我们还应用了10-4的 ℓ2权重衰减。我们使用相同的设置来训练控制器推荐的架构。策略参数θ在[-0.1,0.1]中统一初始化,并以0.00035的学习率与Adam一起训练。与第3.1节中的步骤类似,我们将tanh常数2.5和温度5.0应用于控制器的logits,并将控制器熵添加到奖励中,权重为0.1。
此外,在宏搜索空间中,我们通过增加两层之间的KL散度来增强跳跃连接的稀疏性:1)任意两层之间的跳跃连接概率;2)我们选择的概率ρ=0.4,它表示形成跳跃连接的先验信念。这个KL发散项的权重是0.8。更多培训细节见附录B。
B. Details on CIFAR-10 Experiments
我们发现以下技巧对于实现ENAS的良好性能至关重要。标准NAS(Zoph&Le,2017;Zoph等人,2018)也依赖于这些和其他技巧。
卷积层的结构。我们模型中的每个卷积按relu conv batchnorm的顺序应用(Ioffe&Szegedy,2015;He et al.,2016b)。此外,在我们的微搜索空间中,每个深度可分离卷积应用两次(Zoph等人,2018)。
稳定随机跳跃连接。如果一个层从它之前的多个层接收到跳过连接,那么这些层的输出将在其深度维度中连接起来,然后进行滤波器尺寸为1×1的卷积(接着是批处理规范化层和ReLU层),以确保不同体系结构之间的输出信道数不发生变化。当对一个固定的体系结构进行采样时,我们发现可以移除这些批处理规范化层,以节省最终模型的计算时间和参数,而不会牺牲显著的性能。
Global Average Pooling。在最后的卷积层之后,我们平均每个通道的所有激活,然后将它们传递到Softmax层。此技巧由(Lin等人,2013)引入,目的是减少到Softmax层的密集连接中的参数数量,以避免过度拟合。
牺牲显著的性能。
Global Average Pooling。在最后的卷积层之后,我们平均每个通道的所有激活,然后将它们传递到Softmax层。此技巧由(Lin等人,2013)引入,目的是减少到Softmax层的密集连接中的参数数量,以避免过度拟合。
最后两个技巧非常重要,因为如Eqn 1所述,共享参数ω的梯度更新具有非常高的方差。事实上,我们发现没有这两个技巧,ENAS的训练是非常不稳定的。















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









