







本文总结多篇相关博客:https://www.sohu.com/a/222705024_129720、https://zhuanlan.zhihu.com/p/60592822、https://blog.csdn.net/qq_14845119/article/details/84070640、https://blog.csdn.net/saturdaysunset/article/details/107170009,基于论文:Efficient Neural Architecture Search via Parameters Sharing进行总结介绍,论文链接:https://arxiv.org/abs/1802.03268
ENAS:通过参数共享实现高效的神经架构搜索《EfficientNet Neural Architecture Search via Parameter Sharing
ENAS基本概念参考:https://cloud.tencent.com/developer/article/1182704
ENAS的Pytorch实现:https://github.com/carpedm20/ENAS-pytorch
ENAS的实现2:https://github.com/melodyguan/enas
本文提出超越神经架构搜索(NAS)的高效神经架构搜索(ENAS),这是一种经济的自动化模型设计方法,通过强制所有子模型共享权重从而提升了NAS的效率,克服了NAS算力成本巨大且耗时的缺陷,GPU运算时间缩短了1000倍以上。在Penn Treebank数据集上,ENAS实现了55.8的测试困惑度;在CIFAR-10数据集上,其测试误差达到了2.89%,与NASNet不相上下(2.65%的测试误差)。
1. 简介
神经架构搜索(NAS)已成功用来设计图像分类和语言建模模型架构 (Zoph & Le, 2017; Zoph et al., 2018; Cai et al., 2018; Liu et al., 2017; 2018)。在 NAS 中,RNN 控制器进行循环训练:控制器首先采样候选架构,即一个子模型(child model),接着训练它收敛以测量其在所需任务上的表现。控制器接着把子模型表现作为指导信号以发现更好的架构。这一过程需要重复迭代很多次。尽管其实证表现令人印象深刻,NAS 的算力成本巨大且耗时,比如 Zoph et al. (2018) 使用 450 块 GPUs 耗时 3-4 天(即 32,400-43,200 GPU 小时)。同时,使用的资源越少,所得结果的竞争力就越小 (Negrinho & Gordon, 2017; Baker et al., 2017a)。我们发现 NAS 的计算瓶颈是训练每个子模型至收敛,只测量其精确度同时摈弃所有已训练的权重。
本文研究做出的主要贡献是通过强制所有子模型共享权重而提升了 NAS 的效率。这个想法明显存在争议,因为不同的子模型利用权重的方式也不同,但本文受到先前迁移学习和多任务学习工作的启发,即已确定一个特定任务的特定模型所学习的参数可用在其他任务的其他模型之上,几乎无需做出修改(Razavian et al., 2014; Zoph et al., 2016; Luong et al., 2016)。
研究者证明,不仅子模型之间共享参数是可能的,而且表现也很出色。尤其在 CIFAR-10 上,他们的方法取得了 2.89% 的测试误差,相比之下 NAS 为 2.65%。在 Penn Treebank 上,他们的方法实现了 55.8 的测试困惑度,明显优于 NAS 62.4 的测试困惑度 (Zoph & Le, 2017),这是 Penn Treebank 在不使用后训练处理的方法中所实现的一个新的当前最优结果。重要的是,在本研究所有使用单个 Nvidia GTX 1080Ti GPU 的实验中,搜索架构的时间都少于 16 小时。相较于 NAS,GPU 运算时间缩短了 1000 倍以上。鉴于其高效率,我们把这一方法命名为高效神经架构搜索(ENAS)。
ENAS的基本设计思想:
- 采用NAS论文controller RNN和强化学习的思想
- 采用NASNet的Cell和Block的设计
- 将搜索的模型参数共享,所有子网络共享同一份模型参数
在前两点上,借鉴了NAS论文方法和NASNet论文方法,都是采用controller RNN去预测Cell里面Block的input和operation等,Cell的种类也和NASNet一样,分为Normal和Reduction两种。
论文最大的改进在于第3点。之前的强化学习方法每次选择子网络后,都是重新开始训练一遍子网络模型,再从验证集上获得模型的精度。而ENAS的Cell模型空间参数只有一份,每次选择子网络后,都是在已训练的模型参数上继续训练。
比如说,Cell的第一个Block第一次选择的是 3 × 3 3\times3 3×3的卷积和 5 × 5 5\times5 5×5的卷积,在第一次训练完后,会反馈一次验证集的精度给controller RNN,如果第二次选择到了 3 × 3 3\times3 3×3的depthwise卷积和 5 × 5 5\times5 5×5卷积,那么 3 × 3 3\times3 3×3的depthwise卷积从初始化开始训练,而 5 × 5 5\times5 5×5的卷积则是在上一次训练后保存的基础上继续训练,就不用从初始化开始重新训练。
这种方法可以节省大量的子网络训练时间,因为很多参数重新训练的过程都是相似而冗余的,大量的计算时间浪费在同样的训练过程。ENAS通过参数共享的方式,让之前的子网络训练得到充分利用,在节省分布式计算资源的同时,也节省了大量的搜索时间。
2. 方法
ENAS 思想的核心是观察到 NAS 最终迭代的所有图可以看作更大图的子图。换句话说,我们可以使用单个有向无环图(DAG)来表征 NAS 的搜索空间。图 2 是一个通用实例 DAG,其架构可通过采用 DAG 的子图而实现。直观讲,ENAS 的 DAG 是 NAS 搜索空间之中所有可能的子模型的叠加,其中节点表征局部计算,边缘表征信息流。每一个节点的局部计算有其自己的参数,这些参数只有当特定计算被激活时才使用。因此在搜索空间中,ENAS 的设计允许参数在所有子模型(即架构)之间共享。
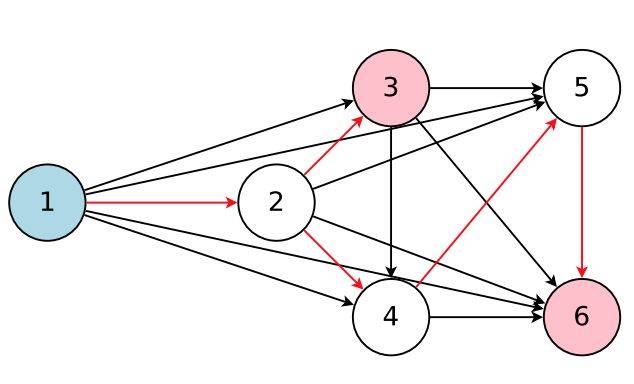
图 1:该图表征了整个搜索空间,同时红箭头定义了其中一个由控制器决定的模型。这里,节点 1 是模型的输入,节点 3 和 6 是模型的输出。
2.1 设计循环单元
为了设计循环单元,作者使用了有 N 个结点的有向无环图(DAG),其中每个节点代表局部运算,而每条边代表 N 个节点中的信息流。ENAS 的控制器是一个 RNN,它会控制:1)哪一条边处于激活状态;2)在 DAG 中的每一个结点会执行哪些运算。

图 2:搜索空间中带有四个计算节点的循环单元案例。左图为对应循环单元的计算 DAG,其中红色的边代表图中的信息流。中间为循环单元。右图为 RNN 控制器的输出结果,它将会生成中间的循环单元和左边的 DAG。注意节点 3 和 4 永远不会被 RNN 采样,所以它们结果是平均值,且可以作为单元的输出。
2.2 设计卷积网络
在卷积网络的搜索空间中,RNN 控制器在每一个决策模块上会制定两组决策:1)前一个单元需要连接什么;2)它需要什么样的运算过程。这些决策共同构建了卷积网络中的不同层级。

图 3:搜索空间中一个循环单元的实例运行,该空间带有 4 个计算节点,表征卷积网络的 4 个层。顶部:控制器 RNN 的输出。左下:对应于网络架构的计算 DAG。红箭头表征激活的计算路径。右下:完整的网络。虚线箭头表征跳跃连接。
2.3 设计卷积单元
本文并没有采用直接设计完整的卷积网络的方法,而是先设计小型的模块然后将模块连接以构建完整的网络(Zoph et al., 2018)。图 4 展示了这种设计的例子,其中设计了卷积单元和 reduction cell。接下来将讨论如何利用 ENAS 搜索由这些单元组成的架构。
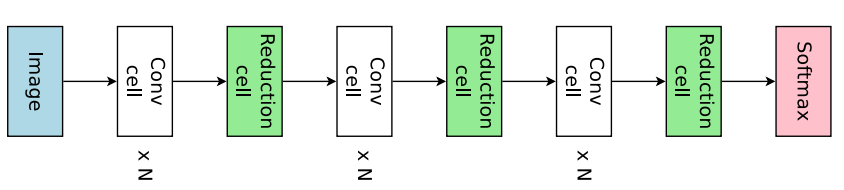
图 4:连接卷积单元和 reduction 单元,以构建完整的网络。
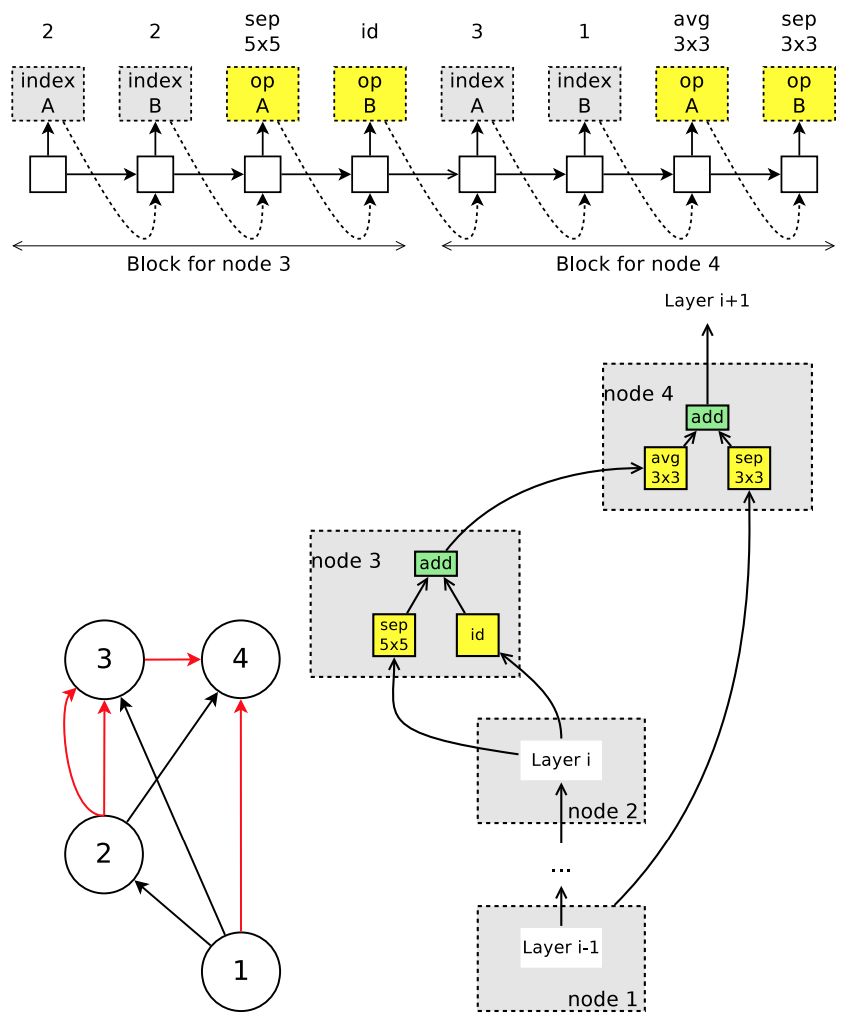
图 5:控制器在卷积单元搜索空间中运行的示例。上:控制器的输出。在卷积单元的搜索空间中,节点 1 和节点 2 是单元的输入,因此控制器只需要设计节点 3 和节点 4。左下:对应的 DAG,其中红边代表激活的连接。右下:由控制器采样得到的卷积单元。
3. 三种DAG图训练方式
论文中交代了3种DAG图的训练方式。
(1)整个网络训练,网络结构类似VGG性质的直型的网络


整个处理流程如上公式所示,
RNN包含N个节点,4个激活函数(tanh, ReLU,identity, sigmoid),最终一共可以生成4N × N! 种网络结构。每一个节点有4种激活方式,N个节点相互独立,生成4N种激活方式,第一个节点只能和输入进行连接,第二个节点可以和输入和第一个节点2个里面选一个连接,第三个节点可以和输入和第1,2共3个节点里面选一个连接,依次类推,最终产生N!种连接方式。所以最终生成4N × N!种有向图DAG。
在实验中节点数N=12。
(2)整个网络训练,网络结构类似resnet类型的带shortcut连接的网络

该结构只有1个输入,一共包含6种操作(3 × 3 卷积,5 × 5卷积,3 × 3 depthwise-separable卷积,5 × 5depthwise-separable卷积,max pooling,3 × 3 average pooling)。
假设一共L个层,也就是L个节点,最终将产生6L × 2 L(L-1)/2种网络结构。
每个节点相互对立,每一个节点都有6种操作可能,L个节点就会有6L种操作可能。
有L个节点的有向图一共有L(L-1)/2条连接线,每个连接线有连接,不连接,2种可能,整个图就会产生2 L(L-1)/2种连接结构。最终就会产生6L × 2 L(L-1)/2种网络结构。
在实验中节点数L=12。
(3)只有BLOCK模块的训练,网络结构包括2个输入端,带shortcut连接

处理流程如下,h1,h2是两个输入,

假设有B个节点,有2个节点是输入节点,剩下B-2个节点。对于任意一个节点i (3 ≤ i ≤ B),将会产生(5 × (B - 2)!)2种网络结构。
其中,5表示5中操作(identity,3 × 3 depthwise-separable卷积,5 × 5depthwise-separable卷积,3 × 3 max pooling,average pooling)。类似前面的思路,2个输入节点确定,B-2个节点有(B - 2)!种连接方式,这样就会产生5 × (B - 2)!种网络,而该BLOCK的每个节点都包含2个输入,每个输入相互独立,就会产生(5 × (B - 2)!)2种网络结构。也就是说,普通卷积就会产生(5 × (B - 2)!)2种网络结构,而该模块BLOCK还使用了stride=2的卷积,该卷积也会产生(5 × (B - 2)!)2种网络结构。最终就会产生(5 × (B - 2)!)4种网络结构。
实验中节点数B=7。
训练完该BLOCK模块就会基于此生成最终网络结构,

如上图所示,包含了3个BLOCK模块,每个模块包含N个正常卷积和1个stride=2的卷积。
最终产生基于PTB生成的网络:

基于CIFAR-10生成的网络:

总结:
论文通过参数共享,基于BLOCK的训练,大大的加快了搜索模型结构的速度。
4. 实验
4.1 在 Penn Treebank 数据集上训练的语言模型
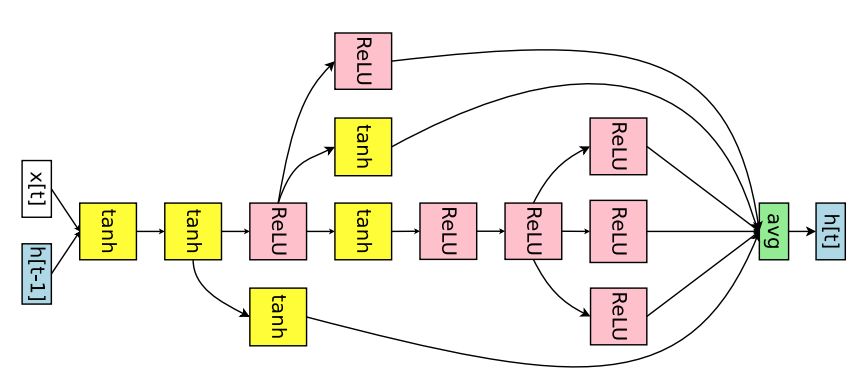
图 6:ENAS 为 Penn Treebank 数据集发现的 RNN 单元。
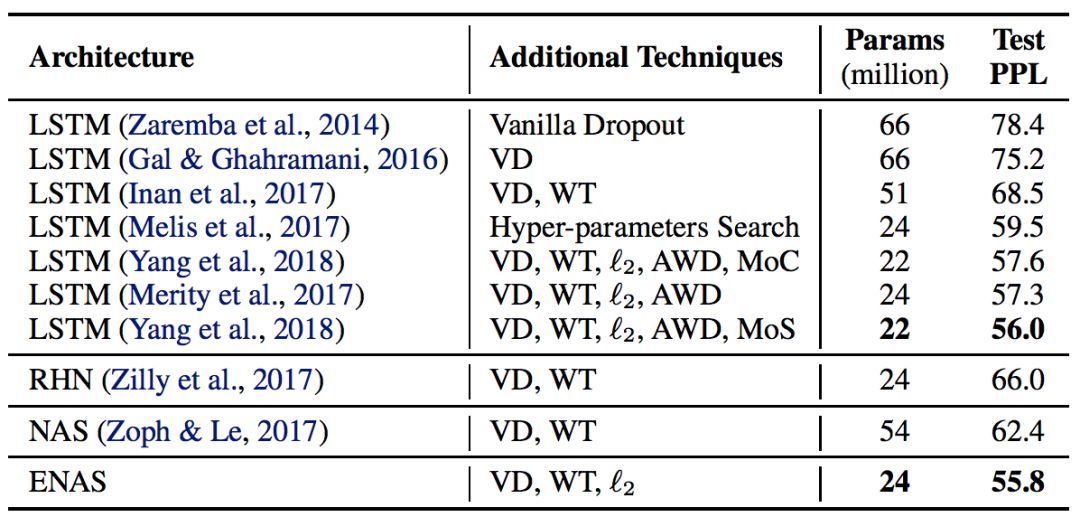
表 1:ENAS 为 Penn Treebank 数据集发现的架构的测试困惑度以及其它的基线结果的比较。(缩写说明:RHN 是 Recurrent Highway Network、VD 是 Variational Dropout、WT 是 Weight Tying、ℓ2 是 Weight Penalty、AWD 是 Averaged Weight Drop、MoC 是 Mixture of Contexts、MoS 是 Mixture of Softmaxes。)
3.2 在 CIFAR-10 数据集上的图像分类实验
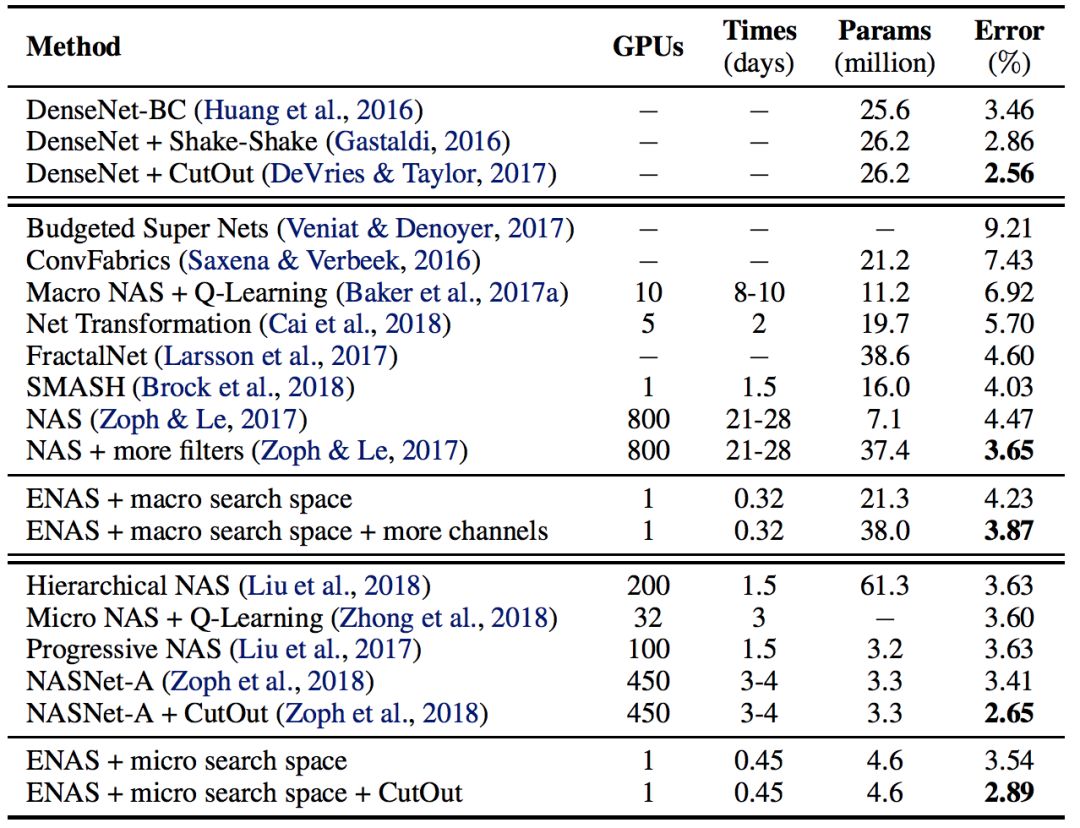
表 2:ENAS 发现的架构在 CIFAR-10 数据集上的分类误差和其它基线结果的对比。在这个表中,第一块展示了 DenseNet,由人类专家设计的当前最佳架构。第二块展示了设计整个网络的方法。最后一块展示了设计模块单元以构建大型模型的技术。
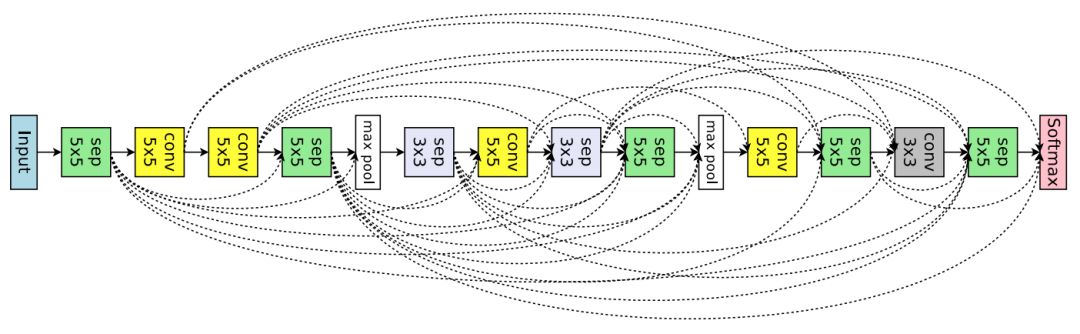
图 7:ENAS 从大型搜索空间中发现的用于图像分类的网络架构。
ENAS 用了 11.5 个小时来发现合适的卷积单元和 reduction 单元,如图 8 所示。
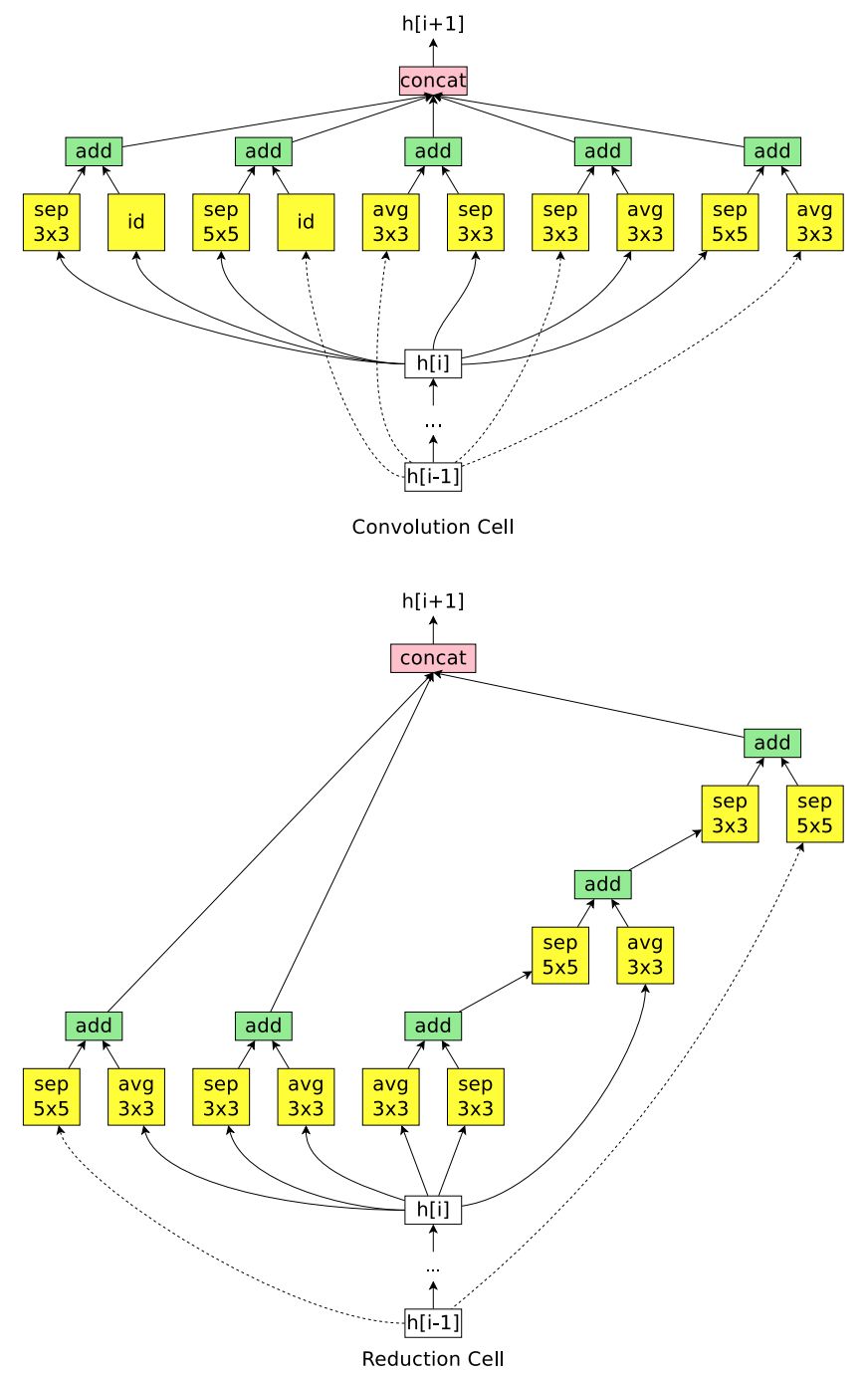
图 8:ENAS 在微搜索空间中挖掘新的单元。
5. 进一步解析
ENAS 流程:ENAS首先有一个控制器, 控制器是一个LSTM,用这个LSTM生成一个序列(其实就是一串数字), 序列表示要生成的RNN的结构, 然后将序列整理成一个字典如下:
{-1: [Node(id=0, name='ReLU')], -2: [Node(id=0, name='ReLU')], 0: [Node(id=1, name='sigmoid'), Node(id=7, name='sigmoid')], 1: [Node(id=2, name='ReLU'), Node(id=3, name='identity'), Node(id=4, name='sigmoid'), Node(id=11, name='tanh')], 3: [Node(id=5, name='sigmoid'), Node(id=9, name='identity'), Node(id=10, name='sigmoid')], 5: [Node(id=6, name='ReLU')], 4: [Node(id=8, name='tanh')], 2: [Node(id=12, name='avg')], 6: [Node(id=12, name='avg')], 7: [Node(id=12, name='avg')], 8: [Node(id=12, name='avg')], 9: [Node(id=12, name='avg')], 10: [Node(id=12, name='avg')], 11: [Node(id=12, name='avg')], 12: [Node(id=13, name='h[t]')]}
解释一下上面这个字典:
-1这个节点(x[t])的后面连接的是0节点(ReLU), -2节点(h[t-1])后面也是0节点(ReLU), 0节点后面连接的有1(sigmoid)、7(sigmoid)两个节点…
这个结构表示的RNN对应下面图(9): 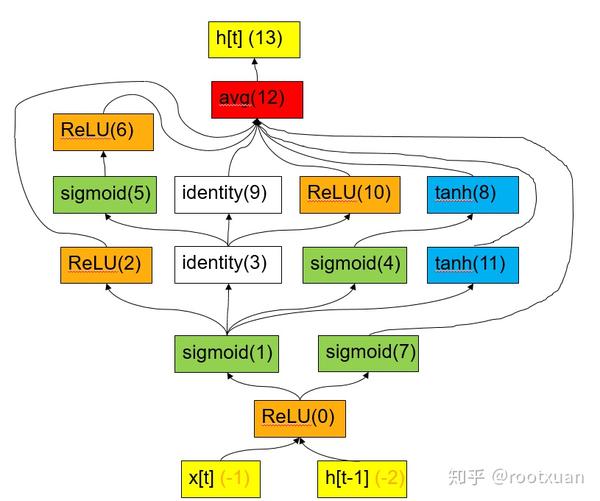
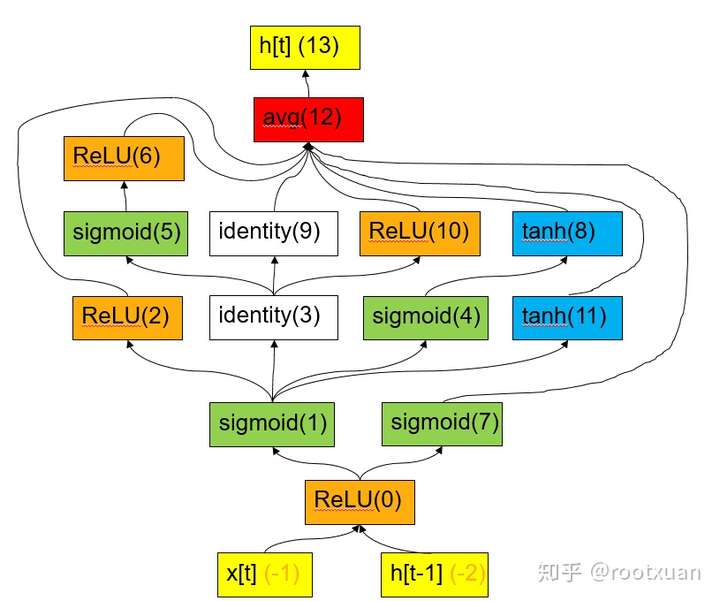
图 9
根据这个字典生成RNN结构, 如图(10):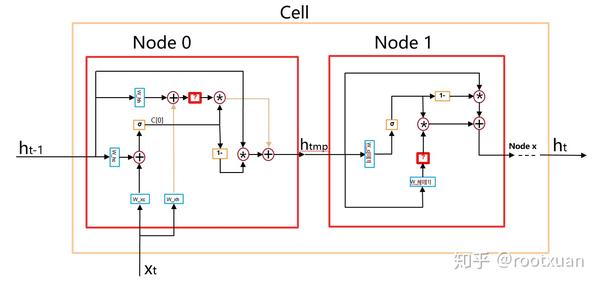
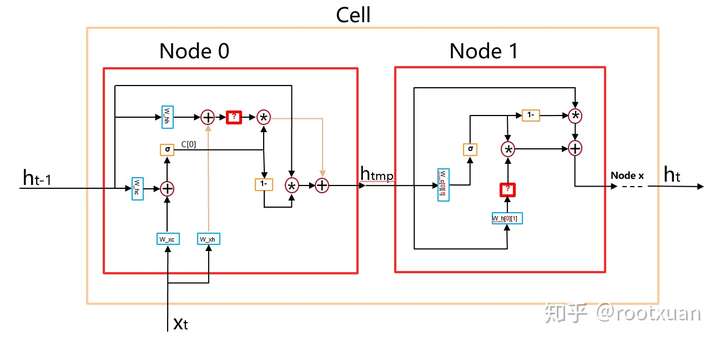
图 10
图(10)的整个Cell就对应图(9), Node 0就对应图(9)里的ReLU(0), Node 1就对应图(9)里的sigmoid(1), Node 0里的红色问号就表示ReLU激活函数, Node 1里的红色问号就表示sigmoid激活函数…所以其实可以调节的激活函数不多, 每个Node只有一个激活函数可以调节, 除了Node 0外, 其他Node的结构是一样的, 只有红色问号那个激活函数是由控制器挑选的。
可以看到整个Cell其实就类似一个LSTM单元, 但是比LSTM单元复杂的多。
生成RNN结构后就训练RNN, 训练一定step后, 再训练控制器。
下面重点讲一下控制器LSTM的输入输出以及生成的RNN如何共享参数。
控制器的输入输出 (以生成4个激活函数, 12个节点为例)
控制器是个LSTM, 在NLP领域, 一般RNN每一时刻的输入是一个词经过embedding处理后的一个词向量,在这里初始的输入是个全0的向量, 第0个时间步的输出是一个固定大小(hidden size)的向量, 经过一个全连接层后输出一个size为4的向量, 然后经过softmax函数后选出最大值对应的索引index,那么index就是0~3之间的一个值了,这个索引就对应着0号节点要选择的激活函数。
然后将index做为第1时间步的输入,将index进行embedding后输入LSTM, 输出还是一个固定大小(hidden size)的向量,经过一个全连接层后输出一个size为1的向量,然后经过softmax函数后选出最大值对应的索引index, 其实这个index就是0了(因为size为1),这个索引就对应着1号节点的前置节点是0,再将index+4做为第2个时间步的输入,index+4进行embedding后输入LSTM, (稍后解释为什么要+4),输出是一个固定大小(hidden size)的向量, 经过一个全连接层后输出一个size为4的向量,如此循环,但是注意第1、3、5、7…时间步的输出size分别是1,2,3,4…,因此第1时间步(也就是节点1)的前置节点就只能选0, 第3时间步(也就是节点2)的前置节点只能在[0,1]中选, 第5时间步(也就是节点3)的前置节点只能在[0,1,2]中选…如图(11)(注:图11的Node 1相当于本文描述的0节点)。
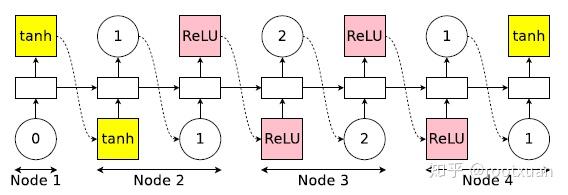
图 11
为什么第2、4、6…时间步的输入是index+4呢, 主要是1、3、5、7…时间步将生成节点的前置节点索引,范围是0~11, 而0、2、4、6…时间步将生成激活函数的索引,范围是0~3, 为了让输入有所区别, 2、4、6…时间步的输入是1、3、5、7…时间步输出+4,那么2、4、6…时间步的输入范围就是415,1、3、5、7…时间步的输入范围就是03,这样就可以区分开输入(想想毕竟输出的是不同类别的东西, 输入区分开也是应该的)。见图(12)
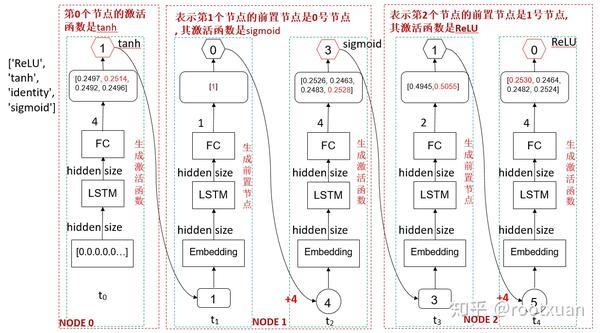
图 12
生成的RNN如何共享参数
ENAS最重要的贡献是共享参数, 那么怎么做到共享参数呢?
首先需要了解的是, 一个节点的前置节点一定比本节点小, 也就是如果node m的前置节点是mode n的话, 那么n一定比m小, 通过图9也可以看的出来。
那么先把所有的权重先建立好, 也就是图10中的W_c和W_h, 先建立所有的W_c[n][m]和W_h[n][m], 其中m表示本节点, n表示本节点的前置节点,且n<m。然后参照图10,在构建网络的时候,直接使用相应的W_c和W_h即可。
小结
我们在本文中提出高效神经架构搜索(ENAS),这是一种高效和经济的自动化模型设计的方法。在 ENAS 中,有一个控制器通过在一个大型计算图中搜索一个最优的子图以学习发现最优神经网络架构的方法。控制器采用策略梯度进行训练,以选择最大化验证集期望奖励的子图。同时,和所选子图对应的模型将进行训练以最小化标准交叉熵损失。由于子模型之间的参数共享,ENAS 的速度很快:它只需要使用少得多的 GPU 运算时间就能达到比当前的自动化模型设计方法好很多的经验性能,尤其是,其计算成本只有标准的神经架构搜索(NAS)的千分之一。在 Penn Treebank 数据集上,ENAS 发现了一个新颖的架构,其达到了 55.8 的测试困惑度,这是未经后处理而达到当前最佳性能的新方法。在 CIFAR-10 数据集上,ENAS 设计了一个新颖的架构,其测试误差达到了 2.89%,与 NASNet(Zoph et al., 2018)不相上下(2.65% 的测试误差)。















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









