







定义
TripletLoss T r i p l e t L o s s 的提出,是在这篇论文中——FaceNet: A Unified Embedding for Face Recognition and Clustering,论文中对 TripletLoss T r i p l e t L o s s 的定义如下:
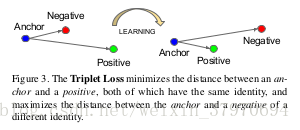
如上图所示, triplet t r i p l e t 是一个三元组,这个三元组是主要构成的:从训练样本中随机选取一个样本,称为 anchor(xa) a n c h o r ( x a ) ,然后再随机分别选取一个和 anchor a n c h o r 类别相同的样本 positive(xp) p o s i t i v e ( x p ) 以及和 anchor a n c h o r 类别不同的样本 negative(xn) n e g a t i v e ( x n ) ,因此构成了[ anchor,positive,negative a n c h o r , p o s i t i v e , n e g a t i v e ]三元组。 TripletLoss T r i p l e t L o s s 的作用就是让特征表达 xa x a 与 xp x p 之间的距离尽可能小,让 xa x a 与 xn x n 的距离尽可能大。
公式
参考博文链接
同时,要让
xa
x
a
与
xn
x
n
之间的距离和
xa
x
a
与
xp之间的距离有一个最小的间隔
x
p
之
间
的
距
离
有
一
个
最
小
的
间
隔
α
α
,公式化的表示即:
对应的目标函数 L L :这里距离用欧式距离度量,表示[.]内的值大于0的时候,取该值为损失,小于0的时候,损失为0。
对目标函数 L L 求导:
代码
参数:
anchor−−>bottom[0]:N∗C∗1∗1
a
n
c
h
o
r
−
−
>
b
o
t
t
o
m
[
0
]
:
N
∗
C
∗
1
∗
1
positive−−>bottom[1]:N∗C∗1∗1
p
o
s
i
t
i
v
e
−
−
>
b
o
t
t
o
m
[
1
]
:
N
∗
C
∗
1
∗
1
negative−−>bottom[2]:N∗C∗1∗1
n
e
g
a
t
i
v
e
−
−
>
b
o
t
t
o
m
[
2
]
:
N
∗
C
∗
1
∗
1
(1)caffe.proto
层参数定义文件位于src/caffe/proto/caffe.proto
optional TripletLossParameter triplet_loss_param = 6667;message TripletLossParameter {
//margin for negative triplet
optional float margin = 1 [default = 1.0];
}(2)LayerSetUp
template <typename Dtype>
void TripletLossLayer<Dtype>::LayerSetUp(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
LossLayer<Dtype>::LayerSetUp(bottom, top);
//输入数据维度保持一致
CHECK_EQ(bottom[0]->num(), bottom[1]->num());
CHECK_EQ(bottom[1]->num(), bottom[2]->num());
CHECK_EQ(bottom[0]->channels(), bottom[1]->channels());
CHECK_EQ(bottom[1]->channels(), bottom[2]->channels());
CHECK_EQ(bottom[0]->height(), 1);
CHECK_EQ(bottom[0]->width(), 1);
CHECK_EQ(bottom[1]->height(), 1);
CHECK_EQ(bottom[1]->width(), 1);
CHECK_EQ(bottom[2]->height(), 1);
CHECK_EQ(bottom[2]->width(), 1);
diff_ap_.Reshape(bottom[0]->num(), bottom[0]->channels(), 1, 1);
diff_an_.Reshape(bottom[0]->num(), bottom[0]->channels(), 1, 1);
diff_pn_.Reshape(bottom[0]->num(), bottom[0]->channels(), 1, 1);
diff_sq_ap_.Reshape(bottom[0]->num(), bottom[0]->channels(), 1, 1);
diff_sq_an_.Reshape(bottom[0]->num(), bottom[0]->channels(), 1, 1);
dist_sq_ap_.Reshape(bottom[0]->num(), 1, 1, 1);
dist_sq_an_.Reshape(bottom[0]->num(), 1, 1, 1);
// vector of ones used to sum along channels
summer_vec_.Reshape(bottom[0]->channels(), 1, 1, 1);
for (int i = 0; i < bottom[0]->channels(); ++i)
summer_vec_.mutable_cpu_data()[i] = Dtype(1);
dist_binary_.Reshape(bottom[0]->num(), 1, 1, 1);
for (int i = 0; i < bottom[0]->num(); ++i)
dist_binary_.mutable_cpu_data()[i] = Dtype(1);
}(3)Forward
template <typename Dtype>
void TripletLossLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
int count = bottom[0]->count();
//const Dtype* sampleW = bottom[3]->cpu_data();
const Dtype sampleW = Dtype(1);
caffe_sub(
count,
bottom[0]->cpu_data(), // anchor
bottom[1]->cpu_data(), // positive
diff_ap_.mutable_cpu_data()); // a_i-p_i
caffe_sub(
count,
bottom[0]->cpu_data(), // anchor
bottom[2]->cpu_data(), // negative
diff_an_.mutable_cpu_data()); // a_i-n_i
caffe_sub(
count,
bottom[1]->cpu_data(), // positive
bottom[2]->cpu_data(), // negative
diff_pn_.mutable_cpu_data()); // p_i-n_i
const int channels = bottom[0]->channels();
Dtype margin = this->layer_param_.triplet_loss_param().margin();//参数\alpha
Dtype loss(0.0);
for (int i = 0; i < bottom[0]->num(); ++i) {
//dist_sq_ap_=diff_ap_.cpu_data*diff_ap_.cpu_data
//即Loss表达式的前半部分
dist_sq_ap_.mutable_cpu_data()[i] = caffe_cpu_dot(channels,
diff_ap_.cpu_data() + (i*channels), diff_ap_.cpu_data() + (i*channels));
//dist_sq_an_=diff_an_.cpu_data*diff_an_.cpu_data
//即Loss表达式的后半部分
dist_sq_an_.mutable_cpu_data()[i] = caffe_cpu_dot(channels,
diff_an_.cpu_data() + (i*channels), diff_an_.cpu_data() + (i*channels));
Dtype mdist = sampleW*std::max(margin + dist_sq_ap_.cpu_data()[i] - dist_sq_an_.cpu_data()[i], Dtype(0.0));//Loss公式
loss += mdist;
if (mdist < Dtype(1e-9)) {
//dist_binary_.mutable_cpu_data()[i] = Dtype(0);
//prepare for backward pass
//对diff_ap_、diff_an_、diff_pn_进行初始化
caffe_set(channels, Dtype(0), diff_ap_.mutable_cpu_data() + (i*channels));
caffe_set(channels, Dtype(0), diff_an_.mutable_cpu_data() + (i*channels));
caffe_set(channels, Dtype(0), diff_pn_.mutable_cpu_data() + (i*channels));
}
}
loss = loss / static_cast<Dtype>(bottom[0]->num()) / Dtype(2);
top[0]->mutable_cpu_data()[0] = loss;//将loss向前传播输出至top
}(4)Backward
template <typename Dtype>
void TripletLossLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
//Dtype margin = this->layer_param_.contrastive_loss_param().margin();
//const Dtype* sampleW = bottom[3]->cpu_data();
const Dtype sampleW = Dtype(1);
for (int i = 0; i < 3; ++i) {//3个输入bottom都需要做反向传播
if (propagate_down[i]) {
const Dtype sign = (i < 2) ? -1 : 1;
const Dtype alpha = sign * top[0]->cpu_diff()[0] /
static_cast<Dtype>(bottom[i]->num());
int num = bottom[i]->num();
int channels = bottom[i]->channels();
for (int j = 0; j < num; ++j) {
Dtype* bout = bottom[i]->mutable_cpu_diff();
if (i == 0) {
//对输入bottom[0]anchor求导
//caffe_cpu_axpby:Y=aX+bY
//diff_pn_=alpha*sampleW*diff_pn_
caffe_cpu_axpby(
channels,
alpha*sampleW,
diff_pn_.cpu_data() + (j*channels),
Dtype(0.0),
bout + (j*channels));
}
else if (i == 1) {
//对输入bottom[1]positive求导
//diff_ap_=alpha*sampleW*diff_ap_
caffe_cpu_axpby(
channels,
alpha*sampleW,
diff_ap_.cpu_data() + (j*channels),
Dtype(0.0),
bout + (j*channels));
}
else if (i == 2) {
// 对输入bottom[2]negative求导
//diff_an_=alpha*sampleW*diff_an_
caffe_cpu_axpby(
channels,
alpha*sampleW,
diff_an_.cpu_data() + (j*channels),
Dtype(0.0),
bout + (j*channels));
}
}
}
}
}














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









