









【前言】
最近,learning to rank 的思想逐渐被应用到很多领域,比如google用来做人脸识别(faceNet),微软Jingdong Wang 用来做 person-reid 等等。learning to rank中其中重要的一个步骤就是找到一个好的similarity function,而triplet loss是用的非常广泛的一种。
【理解triplet】
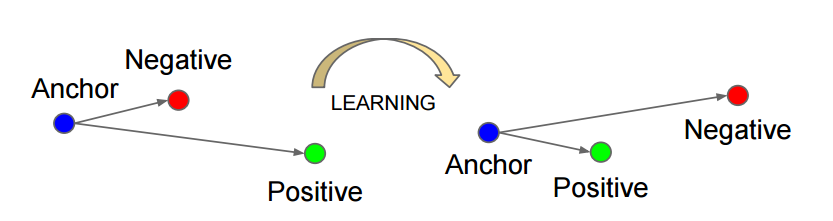
如上图所示,triplet是一个三元组,这个三元组是这样构成的:从训练数据集中随机选一个样本,该样本称为Anchor,然后再随机选取一个和Anchor (记为x_a)属于同一类的样本和不同类的样本,这两个样本对应的称为Positive (记为x_p)和Negative (记为x_n),由此构成一个(Anchor,Positive,Negative)三元组。
【理解triplet loss】
有了上面的triplet的概念, triplet loss就好理解了。针对三元组中的每个元素(样本),训练一个参数共享或者不共享的网络,得到三个元素的特征表达,分别记为: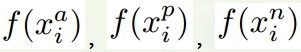
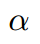
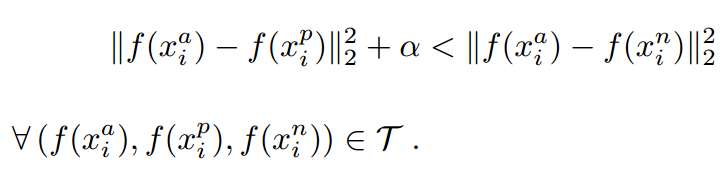
对应的目标函数也就很清楚了:
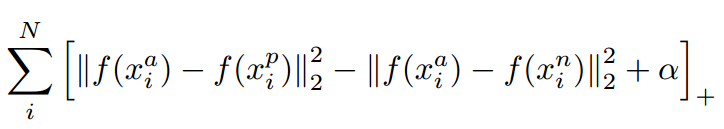
这里距离用欧式距离度量,+表示[]内的值大于零的时候,取该值为损失,小于零的时候,损失为零。
由目标函数可以看出:
- 当x_a与x_n之间的距离 < x_a与x_p之间的距离加
时,[]内的值大于零,就会产生损失。
- 当x_a与x_n之间的距离 >= x_a与x_p之间的距离加
时,损失为零。
【triplet loss 梯度推导】
上述目标函数记为L。则当第i个triplet损失大于零的时候,仅就上述公式而言,有:
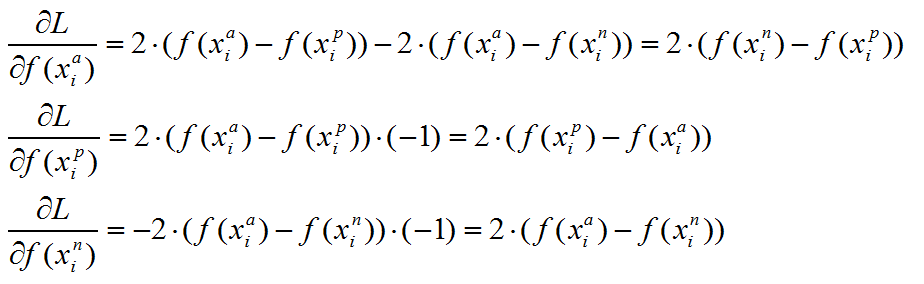
【算法实现时候的提示】
可以看到,对x_p和x_n特征表达的梯度刚好利用了求损失时候的中间结果,给的启示就是,如果在CNN中实现 triplet loss layer, 如果能够在前向传播中存储着两个中间结果,反向传播的时候就能避免重复计算。这仅仅是算法实现时候的一个Trick。
下一节给出caffe中实现triplet loss的方法和代码。

















 1546
1546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









