








-
作者:Junyou Zhu, Yanyuan Qiao, Siqi Zhang, Xingjian He, Qi Wu and Jing Liu
-
单位:中科院自动化所,阿德莱德大学机器学习研究所,同济大学计算机科学与技术系
-
原文链接:MiniVLN: Efficient Vision-and-Language Navigation by Progressive Knowledge Distillation (https://arxiv.org/pdf/2409.18800)
主要贡献
-
论文提出了一种新的两阶段知识蒸馏方法MiniVLN,分别在预训练阶段和微调阶段进行知识蒸馏,从而在保持较高性能的同时显著减少了模型参数。
-
在预训练阶段,MiniVLN通过特征对齐和表示对齐学习细粒度知识;在微调阶段,重点蒸馏直接影响导航性能的知识,如融合信息logits。
-
在CPU上运行时,MiniVLN的推理速度比其教师模型快了三倍多,展示了其在资源受限环境中的实际部署潜力。
研究背景
研究问题
随着模型规模的增大,计算资源的需求也在增加,这与具身AI平台的有限计算能力发生冲突。在此背景下,论文主要解决如何在具身AI中实现高效视觉语言导航。
研究难点
该问题的研究难点包括:如何在保持高性能的同时减少模型的复杂性和计算需求,特别是在资源受限的环境中部署模型。
相关工作
现有的VLN方法通过利用大规模预训练模型来解释多模态信息并指导智能体通过复杂环境取得了显著进展。
然而,这些模型计算密集,需要大量的内存和处理能力,限制了它们在实时或资源受限场景中的部署。
研究方法
论文提出了一种包括预训练和微调两阶段的知识蒸馏框架,用于解决VLN任务中的模型复杂性和计算需求问题。
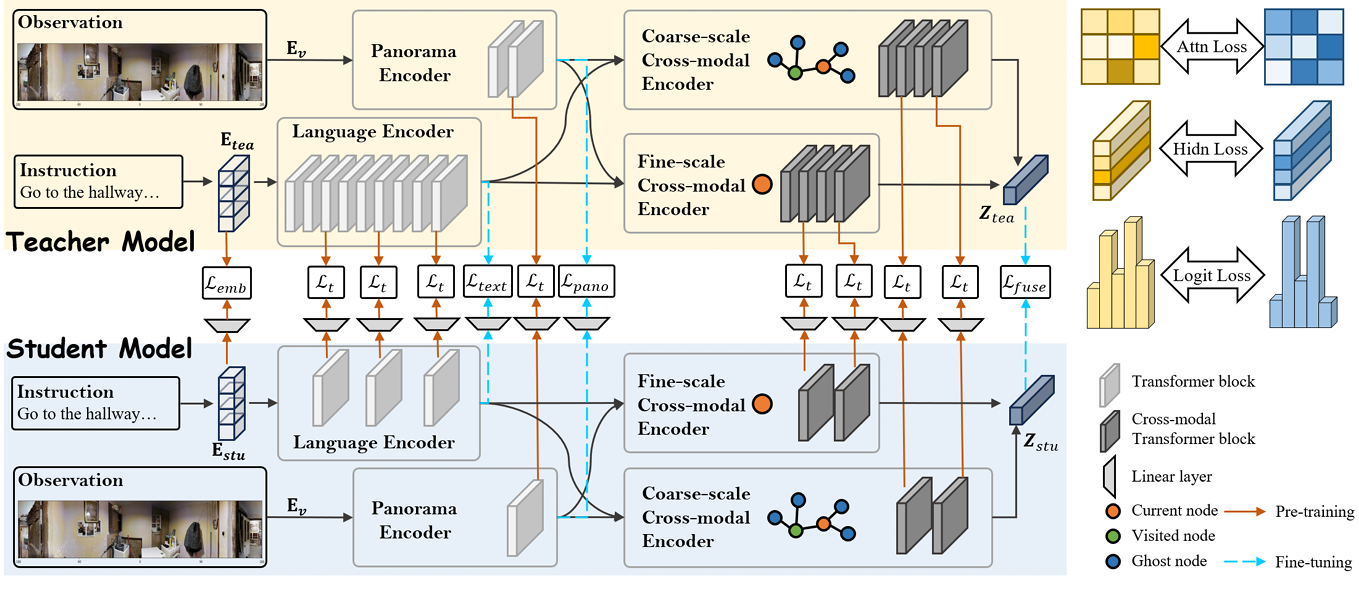
预训练阶段
该阶段专注于学习细粒度的知识。通过特征对齐和表示对齐,从“教师”模型中学习知识。具体公式如下:
-
嵌入层蒸馏损失:,其中,是教师(学生)模型的指令嵌入, 是一个可学习的缩放矩阵。
-
注意力层蒸馏损失:,其中, 表示注意力头的数量,是教师(学生)模型在第 个头中的注意力矩阵。
-
隐藏状态蒸馏损失:,其中, 是教师(学生)模型的隐藏状态,是一个可学习的矩阵。
微调阶段
该阶段专注于蒸馏直接影响导航性能的知识,例如在导航过程中使用的融合信息logits。具体公式如下:
-
文本编码器蒸馏损失:,其中,是一个可学习的权重矩阵,用于对齐学生模型和教师模型的输出空间。
-
全景编码器蒸馏损失:,其中,是另一个可学习的权重矩阵,用于调整学生模型的表现以匹配教师模型的全景观测。
-
局部和全局信息融合蒸馏损失:,其中, 表示交叉熵损失, 表示温度值,在实验中设置为 。
实验设计
数据集
论文使用R2R和REVERIE数据集进行实验。
R2R数据集包含22k个人工标注的导航指令,每个指令平均长度为32个词。REVERIE数据集提供高层次的指令,平均长度为21个词,且更强调目标物体的位置。
使用ScaleVLN作为R2R数据集的教师模型进行知识蒸馏,使用AutoVLN作为REVERIE数据集的教师模型。
评估指标
使用标准的VLN指标评估智能体性能,包括成功率(Success Rate, SR)和按路径长度加权的成功率(Success weighted by Path Length, SPL)。
还使用RGS(Remote Grounding Success, )及其路径长度惩罚加权(RGSPL)评估物体定位精度。
训练细节
在R2R数据集上训练200,000次迭代,批量大小为16;在REVERIE数据集上训练20,000次迭代,批量大小为32。这些设置在本文的所有实验中保持一致。
结果与分析
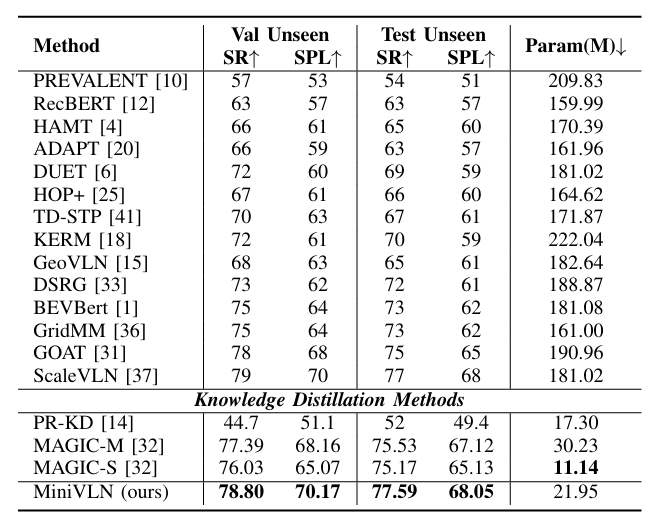
R2R数据集上的结果
-
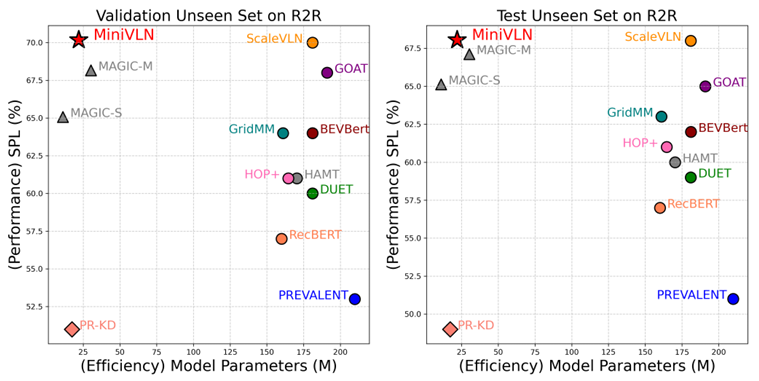
在test-unseen数据集上,MiniVLN实现了77.59%的成功率和68.05%的SPL,超过了ScaleVLN的77% SR和68% SPL。
-
MiniVLN的模型大小约为ScaleVLN的九分之一。
-
与MAGIC-M和MAGIC-S相比,MiniVLN在valid-unseen数据集和test-unseen数据集上均表现出优越的性能,同时保持相当的参数大小。
REVERIE数据集上的结果
-
在路径加权指标上,MiniVLN达到了教师模型SPL的102%和RGSPL的103%。
-
MiniVLN在SR和RGS上分别达到了教师模型性能的约97%。
消融研究
两阶段蒸馏过程的有效性通过使用TinyBERT进行实验验证,结果表明MiniVLN在valid-unseen数据集和test-unseen数据集上的SR分别为78.80%和77.59%,SPL分别为70.17%和68.05%,显著优于未蒸馏模型。
总结
论文提出了一种两阶段知识蒸馏框架,通过在预训练阶段学习细粒度知识,在微调阶段学习直接影响导航决策的知识,实现了高性能和低复杂度的VLN模型。
实验结果表明,两阶段蒸馏方法比单阶段方法更能缩小教师模型和学生模型之间的性能差距。
该方法将模型大小减少到原始模型的12%,为在移动和边缘设备上部署具身VLN场景提供了一个高性能、低复杂度的解决方案。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









