








- 作者:Wei Ziming 1 ^{1} 1,Lin Bingqian 2 ^{2} 2,Nie Yunshuang 1 ^{1} 1,Chen Jiaqi 3 ^{3} 3,Ma Shikui 4 ^{4} 4,Xu, Hang 5 ^{5} 5,Liang Xiaodan 1 ^{1} 1
- 单位: 1 ^{1} 1中山大学深圳校区, 2 ^{2} 2上海交通大学, 3 ^{3} 3香港大学, 4 ^{4} 4Dataa机器人, 5 ^{5} 5华为诺亚方舟实验室
- 论文标题:Unseen from Seen: Rewriting Observation-Instruction Using Foundation Models for Augmenting Vision-Language Navigation
- 论文链接:https://arxiv.org/pdf/2503.18065
- 代码链接:https://github.com/SaDil13/VLN-RAM
主要贡献
- 提出RAM范式:通过改写人类标注的训练数据生成未见过的观察-指令对,无需依赖模拟器环境或网络收集的数据,将多种基础模型相结合实现数据增强。
- 开发训练策略:引入了混合-聚焦训练策略以及随机观察裁剪方案,有效结合原始数据和增强数据进行训练,充分激发增强数据的优势,同时减轻其固有噪声对训练的影响。
- 验证方法有效性:在多个VLN数据集上进行实验,结果表明RAM具有出色的泛化能力,仅引入约少100倍的增强数据,就能达到与最近基于大规模额外模拟器数据的先进数据增强方法相当甚至更好的性能。
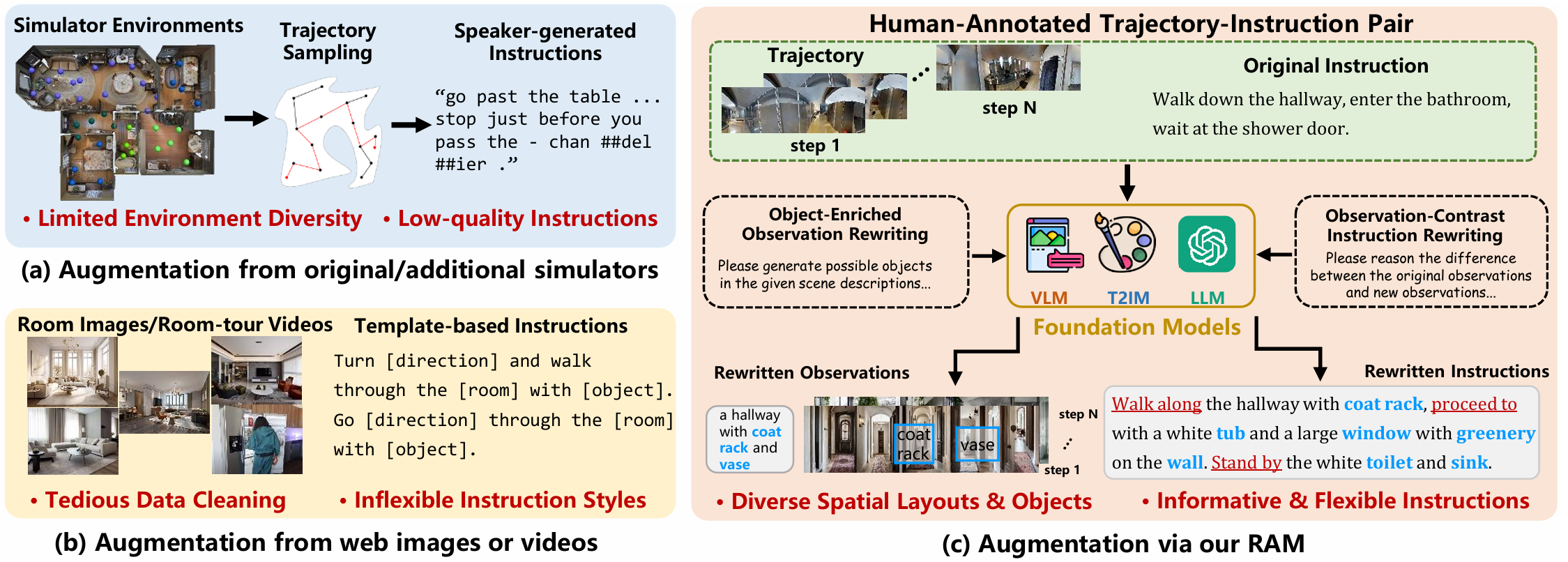
研究背景
- VLN任务重要性:视觉-语言导航(VLN)是实现具身智能的关键研究路径之一,要求具身智能体能够在复杂3D环境中按照自然语言指令进行导航。
- 数据稀缺问题:高质量的手动标注VLN数据有限,限制了现有智能体对各种可能空间布局和共现对象的未见环境的泛化能力。以往研究主要依赖模拟器数据或网络收集的图像/视频来改进泛化能力,但这两种方法分别存在环境多样性有限和数据噪声大、清理工作繁琐等问题。
研究方法
VLN问题设置
-
在离散VLN任务中,智能体需要在导航连接图 G = ( V , E ) G = (V, E) G=(V,E) 中移动,从起始节点到达目标节点,遵循给定的语言指令。
-
其中, V V V 和 E E E 分别表示导航连接图中的节点和边。在时间步 t t t,智能体接收全景观察 O t O_t Ot,其中包含 K K K 个单视图观察 O t , k O_{t,k} Ot,k,即 O t = { O t , k } k = 1 K O_t = \{O_{t,k}\}_{k=1}^K Ot={Ot,k}k=1K。
-
在 K K K 个视图中有 N N N 个可导航视图,动作空间包括这些可导航视图和一个“STOP”动作,智能体需要从中选择一个作为动作预测 a t a_t at。
-
连续VLN建立在Habitat模拟器上,智能体可以在环境中导航到任何点,而不仅仅局限于预定义的图节点。
-
在训练过程中,智能体被输入轨迹-指令对,以学习跨模态对齐知识和导航技能,通过模仿学习算法或强化学习算法进行优化。
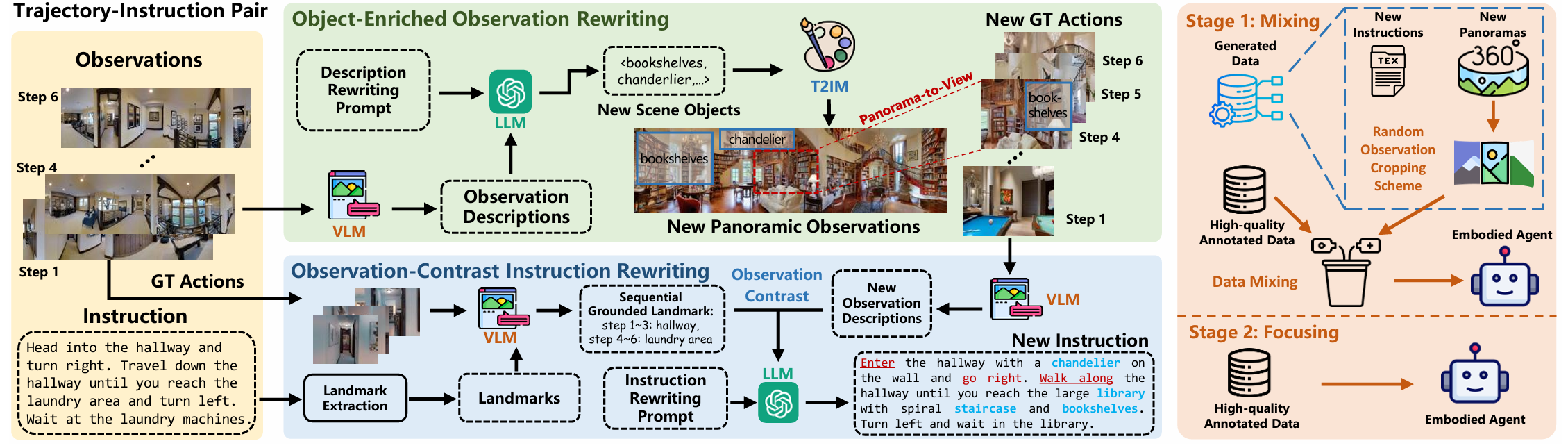
对象丰富观察改写
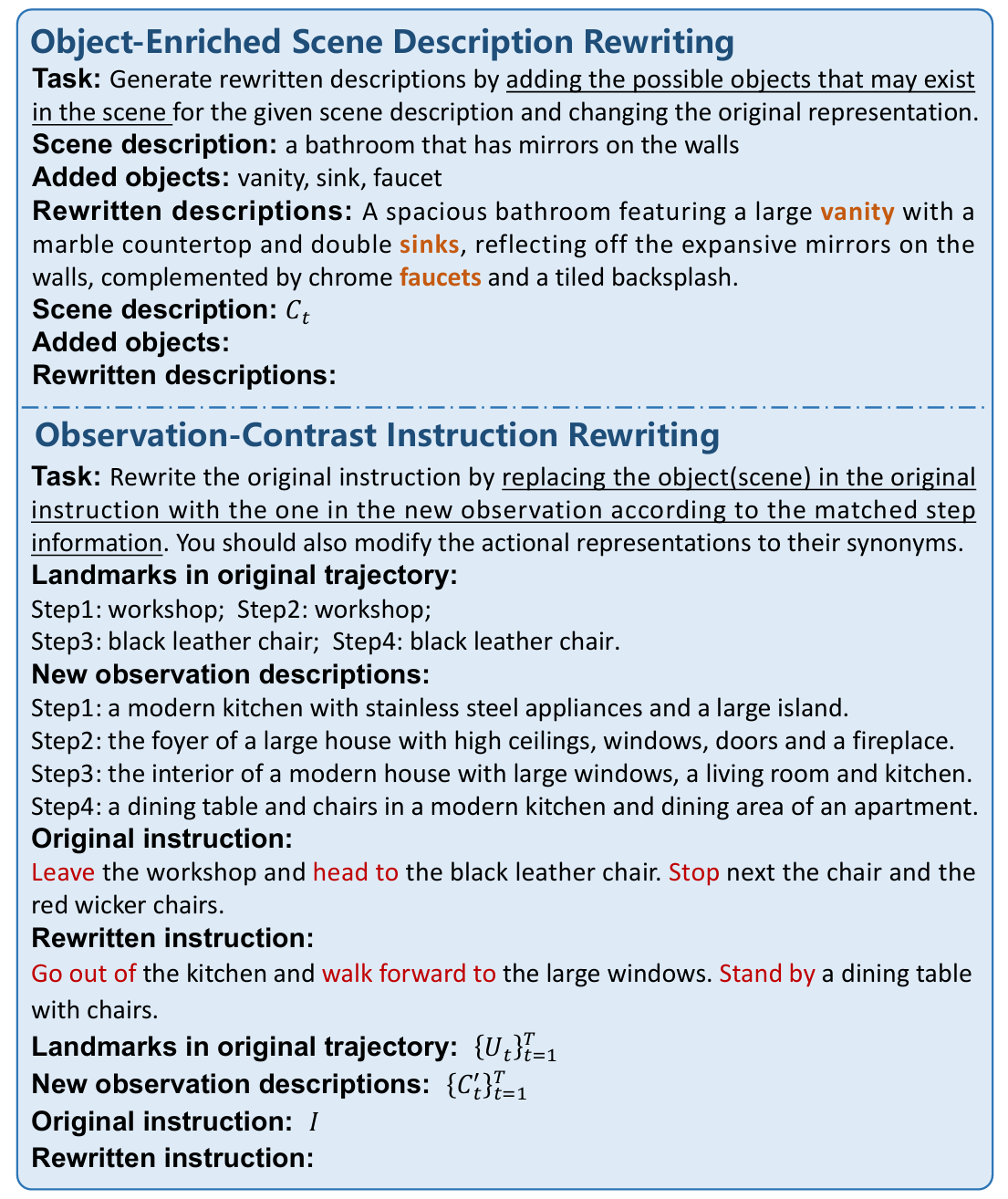
对象丰富场景描述改写:
- 对于人类标注的轨迹-指令对,首先使用视觉-语言模型(VLM)收集轨迹中不同导航时间步的全景观察描述。
- 对于时间步 t t t 的全景观察 O t O_t Ot,通过VLM得到其场景描述 C t = VLM ( O t ) C_t = \text{VLM}(O_t) Ct=VLM(Ot)。
- 然后构造场景描述改写提示 P c P_c Pc,要求LLM生成包含可能存在于场景中的对象的改写场景描述,并改变原始场景描述的表示以突出不同对象。
- 通过这种方式,得到改写后的对象丰富场景描述 C t r C^r_t Ctr 和添加的对象 { B t , n } n = 1 N \{B_{t,n}\}_{n=1}^N {Bt,n}n=1N。
全景图到视图观察生成:
- 将改写后的场景描述 C t r C^r_t Ctr 输入文本到图像生成模型(T2IM),生成改写后的全景图。
- 然后使用Equirec2Perspec算法对全景图进行离散化,得到 K K K 个单视图观察,即 O t r = { O t , k r } k = 1 K O^r_t = \{O^r_{t,k}\}_{k=1}^K Otr={Ot,kr}k=1K。
- 该算法利用相机参数(视场角
FOV
\text{FOV}
FOV、航向
θ
\theta
θ 和俯仰角
ϕ
\phi
ϕ)计算相机投影矩阵的逆矩阵
J
inv
J_{\text{inv}}
Jinv 和旋转矩阵
R
R
R,进而将全景图上的像素坐标转换为球面上的三维点坐标,再转换为图像平面上的二维坐标,生成单视图图像:
J inv = M C proj ( FOV , θ , ϕ ) R = M C rot ( θ , ϕ ) \begin{gathered} J_{\text{inv}} = MC_{\text{proj}}(\text{FOV}, \theta, \phi) \\ R = MC_{\text{rot}}(\theta, \phi) \end{gathered} Jinv=MCproj(FOV,θ,ϕ)R=MCrot(θ,ϕ)
其中, M C proj ( ⋅ ) MC_{\text{proj}}(\cdot) MCproj(⋅) 是相机的投影矩阵计算函数, M C rot ( ⋅ ) MC_{\text{rot}}(\cdot) MCrot(⋅) 是旋转矩阵计算函数。然后通过以下方式将全景图转换为单视图图像:
{ O t , k r } k = 1 K = Equirec2Perspec ( J inv , R , O t r ) \{O^r_{t,k}\}_{k=1}^K = \text{Equirec2Perspec}(J_{\text{inv}}, R, O^r_t) {Ot,kr}k=1K=Equirec2Perspec(Jinv,R,Otr)
观察对比指令改写
序列地标定位:
- 由于指令中提到的地标通常存在于真实动作(观察)中,对于每个真实观察,从指令中找到其匹配的地标以进行序列地标定位。
- 首先使用LLM从原始指令
I
I
I 中提取序列地标
U
=
{
U
k
}
k
=
1
M
U = \{U_k\}_{k=1}^M
U={Uk}k=1M。对于从原始观察
O
t
O_t
Ot 中提取的真实动作(观察)
G
t
G_t
Gt,使用VLM找到与其匹配的地标
U
t
U_t
Ut,即:
U t = arg max U k Sim ( F v ( G t ) , F t ( U k ) ) U_t = \mathop{\arg\max}_{U_k} \text{Sim}(F_v(G_t), F_t(U_k)) Ut=argmaxUkSim(Fv(Gt),Ft(Uk))
其中, F t F_t Ft 和 F v F_v Fv 分别是VLM的文本编码器和图像编码器。
新观察描述收集:
- 在对原始轨迹中的每个真实动作(观察) G t G_t Gt 进行序列地标定位以收集 { U t } t = 1 T \{U_t\}_{t=1}^T {Ut}t=1T 后,从改写后的观察 O t r O^r_t Otr 中提取与 G t G_t Gt 位置相同的真实动作(观察) G t ′ G'_t Gt′。然后使用VLM生成 G t ′ G'_t Gt′ 的描述 C t ′ C'_t Ct′。
基于观察对比的指令改写:
- 构建指令改写提示 P i P_i Pi,要求LLM替换原始指令中的对象(场景)为新观察中的对象,并改变原始动作描述的表达方式。
- 具体来说,根据匹配的步骤信息,用出现在
C
t
′
C'_t
Ct′ 中的地标替换
I
I
I 中的
U
t
U_t
Ut,并将原始动作描述更改为同义词。通过这种方式,得到改写后的指令:
I r = LLM ( { U t } t = 1 T , { C t ′ } t = 1 T , I , P i ) I_r = \text{LLM}(\{U_t\}_{t=1}^T, \{C'_t\}_{t=1}^T, I, P_i) Ir=LLM({Ut}t=1T,{Ct′}t=1T,I,Pi)
混合-聚焦训练机制
- 在获得改写数据后,直接将其与原始数据混合训练可能会引入意外噪声。
- 因此,提出了一种两阶段的混合-聚焦训练机制,在第一阶段将原始数据与改写数据混合训练,同时引入随机观察裁剪方案作为数据增强方法;
- 在第二阶段仅使用原始数据训练,以减少噪声影响。具体来说,第一阶段的导航损失为:
L s 1 = E n ( { O t } t = 1 T , I ) , RC ( { O t r } t = 1 T ) , I r L_{s1} = E_n\left(\{O_t\}_{t=1}^T, I\right), \text{RC}(\{O^r_t\}_{t=1}^T), I_r Ls1=En({Ot}t=1T,I),RC({Otr}t=1T),Ir
第二阶段的导航损失为:
L s 2 = E n ( { O t } t = 1 T , I ) L_{s2} = E_n\left(\{O_t\}_{t=1}^T, I\right) Ls2=En({Ot}t=1T,I)
其中, E n E_n En 表示导航智能体, RC ( ⋅ ) \text{RC}(\cdot) RC(⋅) 表示随机观察裁剪方案。
实验
实验设置
- 数据集:实验主要在四个数据集上进行,包括三个离散VLN基准数据集R2R、REVERIE、R4R,以及连续VLN数据集R2R-CE。
- 这些数据集各有特点,如R2R包含90个室内场景和7189个轨迹,REVERIE将细粒度指令替换为高级指令,R4R创建更长的指令和轨迹,R2R-CE则将离散轨迹转换为连续3D扫描。
- 评估指标:对于不同数据集,使用不同的评估指标。
- 例如,在R2R和R2R-CE上,关注轨迹长度(TL)、导航误差(NE)、成功率(SR)、基于路径长度加权的成功率(SPL)等;
- 在REVERIE上,还关注远程定位成功率(RGS)、基于路径长度加权的远程定位成功率(RGSPL)、oracle成功率(OSR)等;
- 在R4R上,进一步采用覆盖长度分数(CLS)、归一化动态时间规整(nDTW)、基于nDTW的成功率(SDTW)等指标。
- 实现细节:
- 将RAM集成到一个强大的预训练基线模型中,在预训练和微调阶段都添加改写数据。预训练阶段使用三个智能体任务训练智能体;
- 微调阶段采用DAGGER方法训练智能体。使用CLIP ViT B/16和CLIP ViT L/14两种视觉编码器进行验证,采用Tag2Text作为VLM,ChatGPT作为LLM,且所有模型均以零样本方式进行实验。
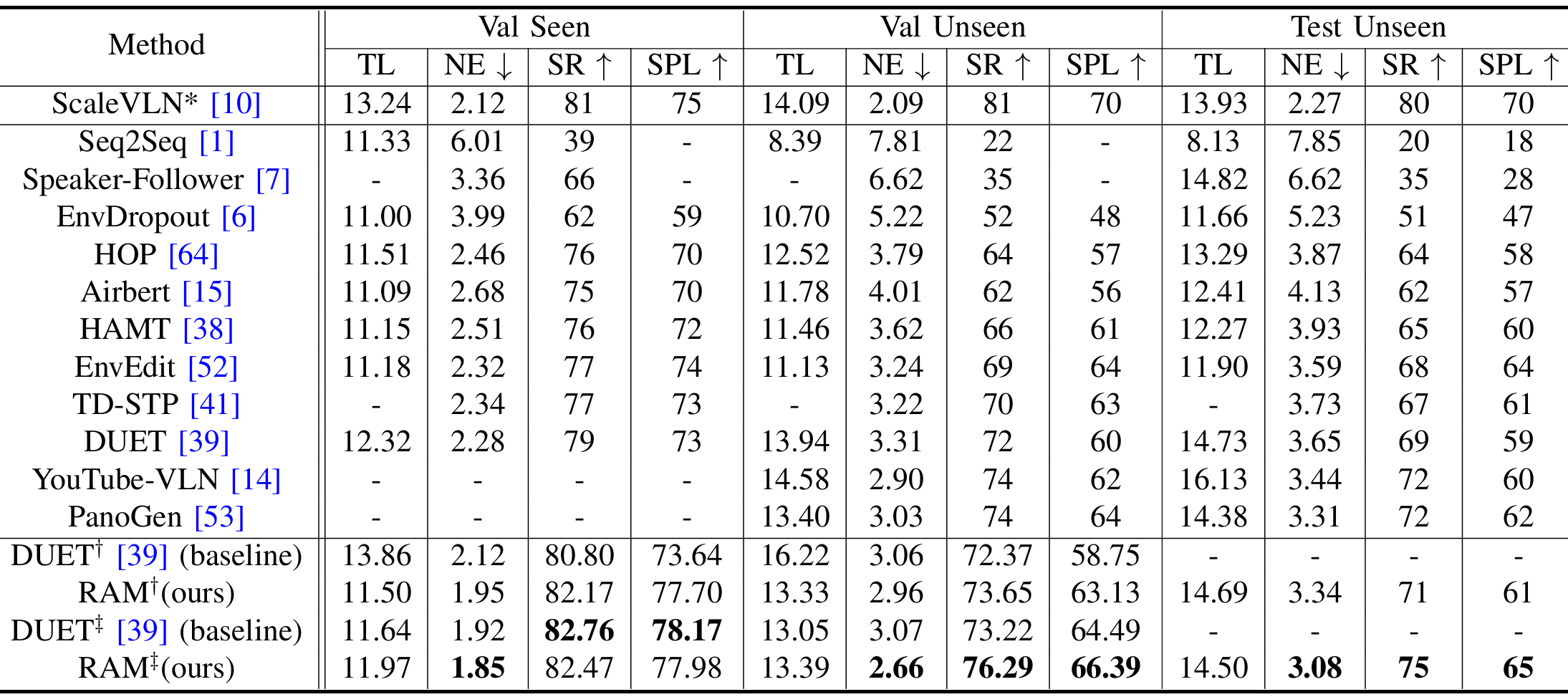
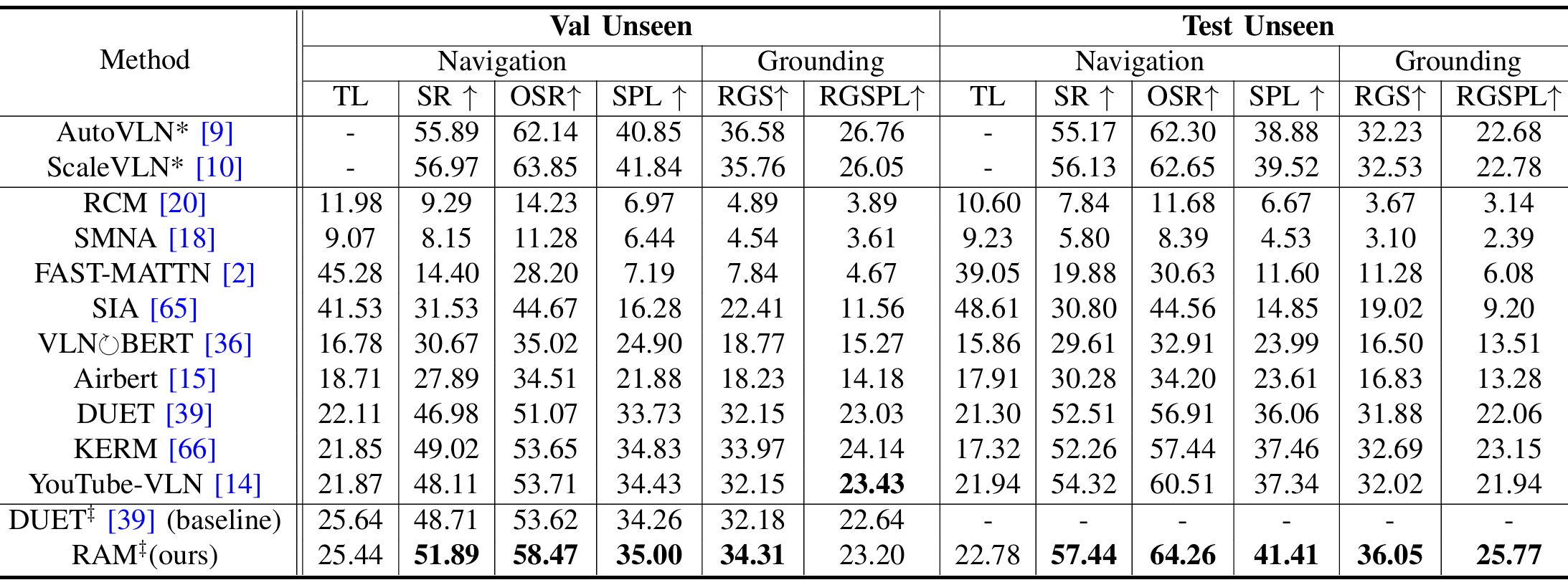
与现有方法的对比
-
R2R数据集:
- RAM在Val Seen分割上优于所有不引入大规模额外数据训练的先前工作,在Val Unseen分割上超越了ScaleVLN。
- 尽管ScaleVLN在Test Unseen分割上表现更好,但其依赖于大规模真实数据资源,而RAM仅引入了少量生成数据。
- 此外,RAM在使用不同图像特征时,均在Val Unseen分割上优于基线DUET。
-
REVERIE数据集:
- RAM在Val Unseen分割上的导航和对象定位指标上均大幅超越基线,在Test Unseen分割上优于引入大规模额外模拟器数据的先前工作。
-
R4R数据集:
- RAM在Val Unseen分割上的导航和指令遵循指标上均优于基线。
-
R2R-CE数据集:
- 尽管RAM主要基于离散环境构建,但在R2R-CE上仍优于基线方法,显示出其向连续环境泛化的潜力。
消融实验
-
观察-指令改写效果:
- 仅进行观察或指令改写就能提升性能,同时进行两者改写效果最佳。
- 与仅基于原始场景描述生成观察相比,基于改写后的场景描述生成观察能带来更大的性能提升。
- 此外,RAM生成的指令比Speaker模型生成的指令更具信息量和多样性。
-
数据融合策略效果:
- 混合-聚焦训练策略优于单一阶段变体,且引入随机观察裁剪方案可进一步提升性能,表明该方案能有效减轻基础模型带来的噪声并提高数据分布多样性。
-
预训练和微调阶段的消融结果:
- 在微调阶段添加RAM数据可有效提升导航性能,表明增强数据有助于提高VLN智能体对未见场景的泛化能力。
- 进一步在预训练阶段添加增强数据,可进一步提升性能。
低资源实验
- 低资源实验验证了RAM增强数据在缓解数据稀缺问题方面的帮助。仅提取部分原始数据用于训练基线,而RAM则添加从相应部分原始数据生成的增强数据。
- 结果表明,RAM在所有比例下均优于基线,且在60%设置下,RAM的性能与使用全部原始训练数据的基线相当。
可视化改写观察-指令示例
- 改写数据示例:RAM生成的改写后的对象丰富场景描述明确指示了多种对象,生成的全景图包含这些新引入的对象和新的空间布局,显著增强了环境的多样性。改写后的指令成功指示了新轨迹中的模态对齐对象。
- 与Speaker模型指令的比较:Speaker模型生成的指令信息量较少,包含重复短语,且与观察的对齐不佳,动作信息有误。相比之下,RAM生成的指令引入了合理的动作描述,并指示了与原始指令不同的多个模态对齐对象。
- Cross-step一致性:从改写后的全景图中提取的多个连续步骤的候选观察显示出Cross-step语义一致性,有助于合理的序贯动作决策。
结论与未来工作
- 结论:RAM范式通过巧妙地利用多种基础模型进行观察-指令改写,并结合混合-聚焦训练策略和随机观察裁剪方案,在多个流行的VLN基准测试中展现出令人印象深刻的泛化能力,为解决具身任务中的关键数据稀缺问题提供了新的见解。
- 未来工作:计划引入更有效的机制,如参数高效的微调和基于反馈的学习,以进一步使基础模型适应VLN数据增强。


















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









