








-
作者:Baichuan Zhou, Haote Yang, Dairong Chen, Junyan Ye, Tianyi Bai, Jinhua Yu, Songyang Zhang, Dahua Lin, Conghui He, Weijia Li
-
单位:上海人工智能实验室,中山大学,商汤科技,武汉大学
-
标题:UrBench: A Comprehensive Benchmark for Evaluating Large Multimodal Models in Multi-View Urban Scenarios
-
原文链接:https://arxiv.org/pdf/2408.17267
-
项目主页:https://opendatalab.github.io/UrBench/
-
代码链接:https://github.com/opendatalab/UrBench
-
数据集:https://huggingface.co/datasets/bczhou/UrBench
主要贡献
-
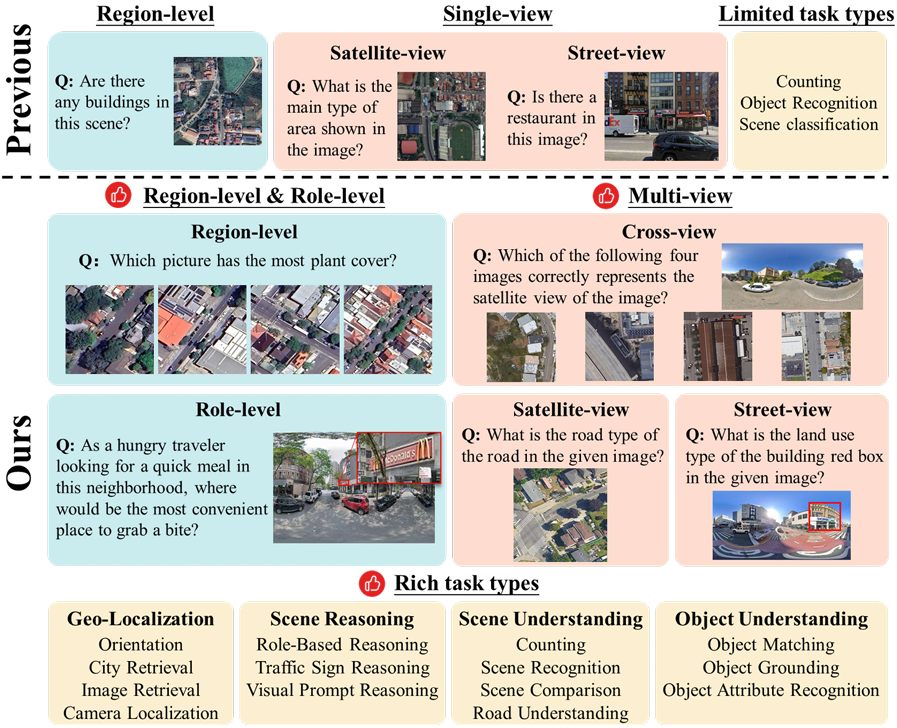
论文设计了一个多视角基准测试UrBench,用于评估多模态大模型(LMMs)在城市环境中的表现。UrBench包括14种城市任务,涵盖了从区域级评估到角色级评估的广泛任务类型。
-
介绍了新的基准测试创建流程,包括跨视角检测匹配算法用于对象级标注生成,以及结合了基于模型、规则和人工的问题生成方法,增强了城市任务的多样性和深度。
-
在UrBench上评估了21种流行的LMMs,结果表明当前的模型在大多数任务上落后于人类专家,揭示了LMMs在城市环境中理解能力的局限性。
-
通过评估发现LMMs在不同城市视角下表现出不一致的行为,特别是在理解跨视角关系方面。这表明当前LMMs在处理多视角信息时存在显著的限制。
研究背景
研究问题
论文主要解决的问题是如何全面评估多模态大模型(LMMs)在城市环境中的表现。
现有的评估基准主要集中在单一视角的区域级任务上,缺乏对城市环境中多模态模型能力的全面评估。
研究难点
该问题的研究难点包括:
-
城市环境的多视角特性、
-
跨视角关系的理解、
-
以及从多个视角综合理解城市环境的复杂性。
相关工作
多模态大模型
-
背景:LMMs建立在大型语言模型(LLMs)的基础上,能够处理来自多种模态的输入,并完成复杂的视觉推理和理解任务。LMMs的发展得益于LLMs在复杂语言推理和理解方面的优势。
-
应用:LMMs在多个领域展现出潜力,包括城市规划和视觉-语言导航等。例如,UrbanCLIP利用LLMs和CLIP进行城市区域分析,Velma结合LLMs和CLIP进行街景导航,Scene-LLM用于室内多视角3D推理,CityGPT研究LMMs在城市空间理解任务中的表现。
-
局限性:现有工作主要集中在LLMs或LLMs与CLIP的组合上,对LMMs的分析有限。此外,这些工作通常集中在单一视角的城市任务上,缺乏对需要高级视觉推理或多视角理解的广泛评估。
多模态基准测试
-
背景:随着LMMs的快速发展,传统的多模态问答基准测试(如VQA和GQA)已不足以全面评估LMMs的能力。近年来,引入了更全面的基准测试来更好地评估LMMs。
-
现有基准:例如,MME是第一个全面评估LMMs在14种感知和推理任务上的能力,MMMU使用大学水平的问题来评估专家级知识,显示当前模型仍落后于人类专家。其他基准如Jiang等人的工作和Wang等人的MUIRBench专注于多图像推理,并包括不可回答的问题。
-
城市环境基准:在遥感领域的基准测试中,RSVQA、EarthVQA、RSIEval、LHRS-Bench、Geochat、VRSBench和CityBench等评估了LMMs在遥感图像上的表现。然而,这些基准测试在任务多样性、多视角样本和地理多样性方面存在限制。
-
论文提出的UrBench填补了这一空白,通过构建一个新的基准测试来评估LMMs在城市规划、推理和理解中的潜力,扩展了任务范围并引入了来自不同地理位置的多视角图像。
UrBench
基准测试分析
概述
- 特征:
-
多视角整合:UrBench结合了街景、卫星视图和街景-卫星交叉视图图像,提供了对城市场景更全面的理解。
-
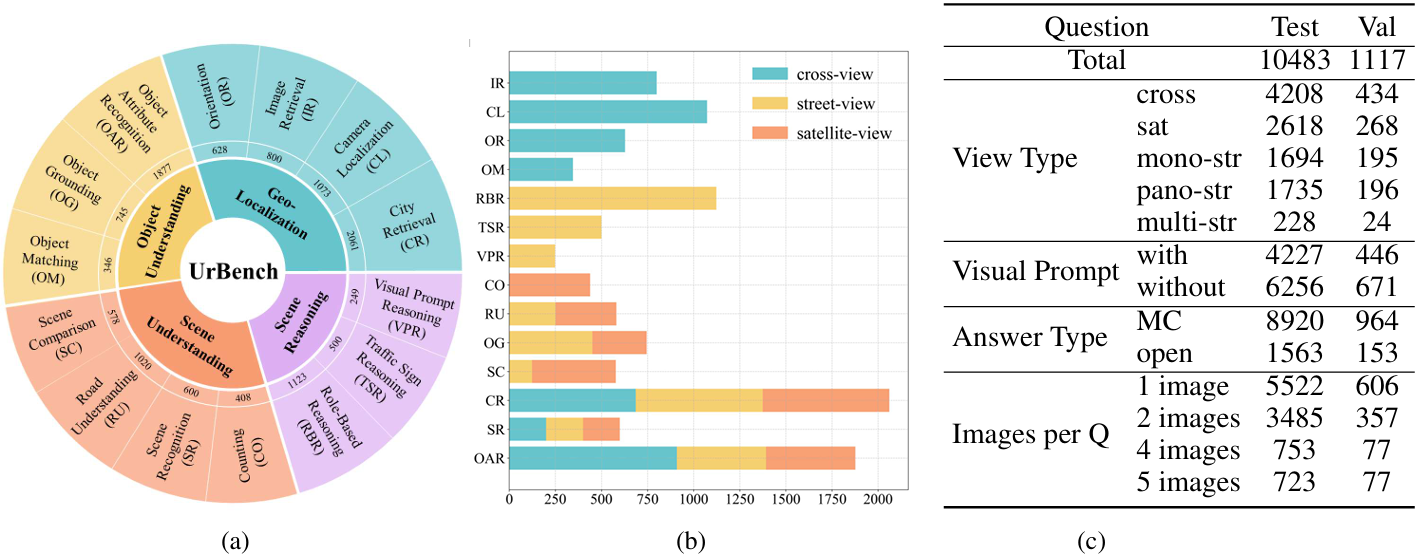
多维度评估:评估LMMs在城市场景中的能力,涵盖地理定位、场景推理、场景理解和物体理解四个维度,总计14种任务类型。
-
问题生成方法:问题通过集成方法生成,包括基于模型的、基于规则的和基于人工的方法,确保生成大量高质量的问题集。
-
与现有基准的比较
-
现有基准:如MUIRBench和MMMU主要评估LMMs在一般场景下的能力,通常从单一视角进行评估。
-
城市场景基准:如CityBench和EarthVQA侧重于单一视角图像和有限的任务范围,而UrBench则结合多视角图像,涵盖更多样化的任务类型。
基准任务
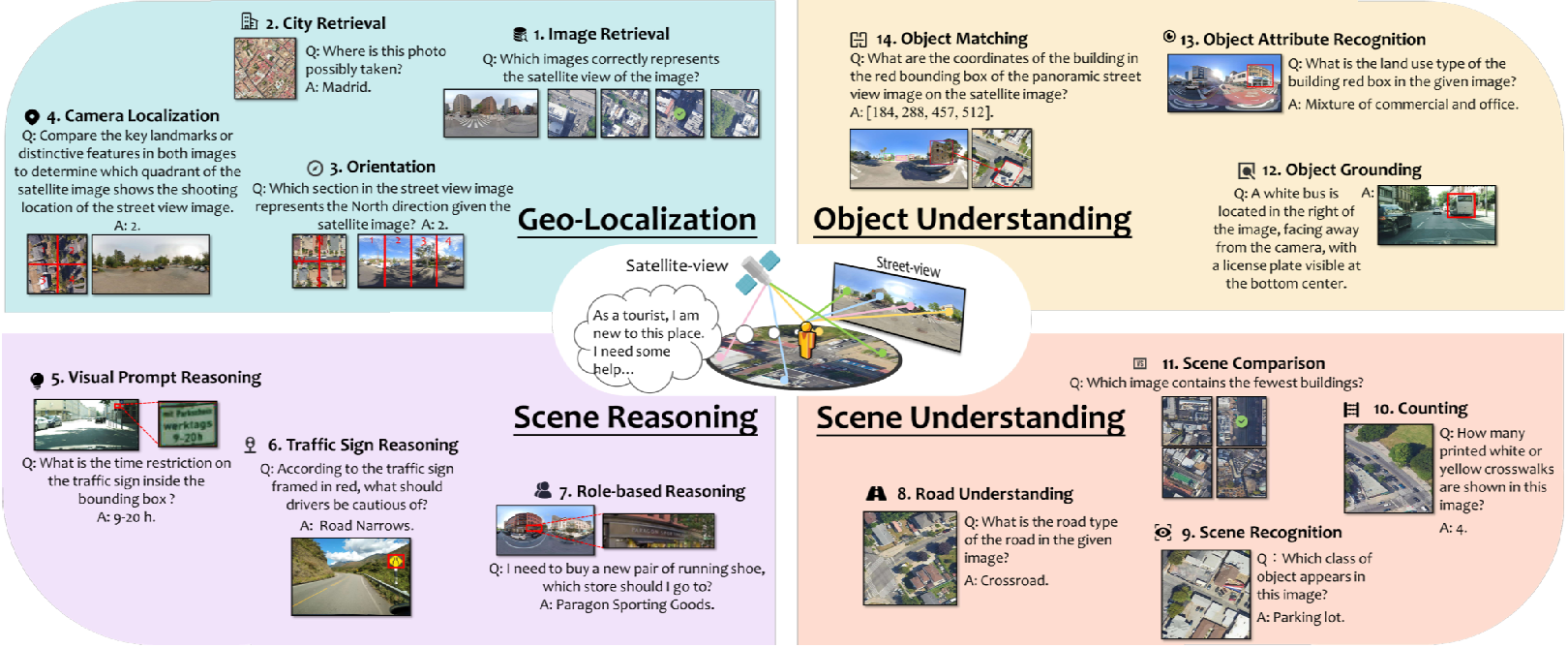
地理定位
-
任务类型:包含角色级任务,要求LMMs根据图像预测地理坐标和方向。具体任务包括图像检索(IR)、城市检索(CR)、定向(OR)和相机定位(CL)。
场景推理
-
任务类型:设计用于评估LMMs在城市多视角场景下的推理能力。具体任务包括视觉提示推理(VPR)、交通标志推理(TSR)和基于角色的推理(Role-based Reasoning)。
场景理解
-
任务类型:评估LMMs在区域级场景理解的能力。具体任务包括计数(CO)、场景识别(SR)、场景比较(SC)和道路理解(RU)。
物体理解
-
任务类型:评估LMMs在城市环境中对物体的细粒度理解能力。具体任务包括物体定位(OG)、物体匹配(OM)和物体属性识别(OAR)。
基准构建
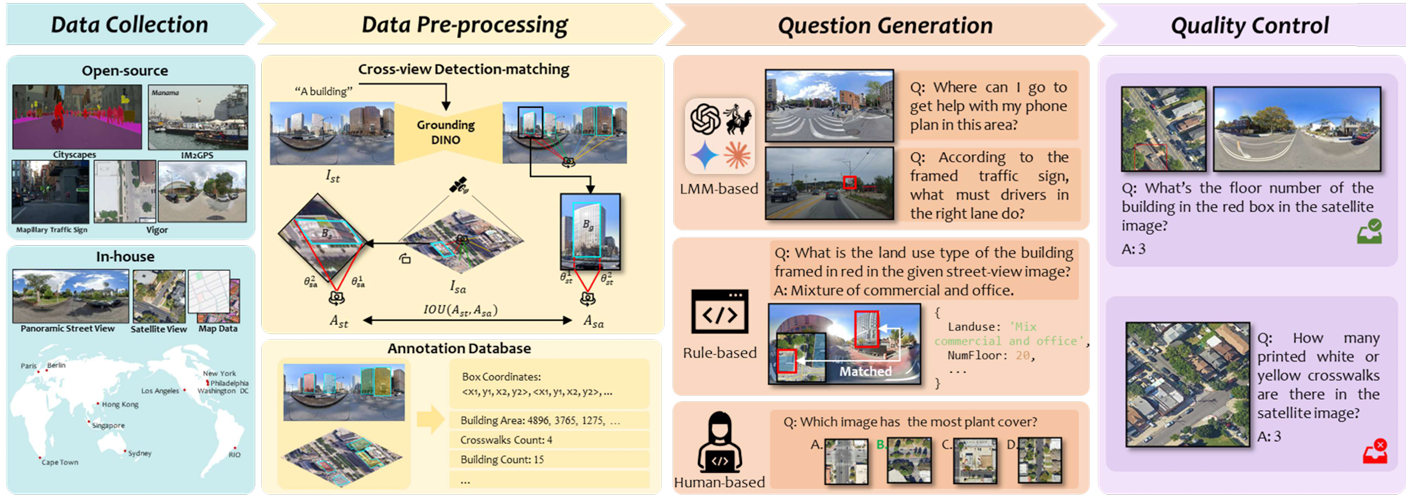
数据收集
-
数据来源:包括自收集数据和开放数据集。
-
自收集数据包含来自Google Street View和Google Earth的街景和卫星视图图像。
-
开放数据集包括Cityscapes、Mapillary Traffic Sign Dataset、VIGOR dataset和IM2GPS。
数据预处理
-
标注生成:为跨视角任务生成实例级别的标注。
-
使用预训练的Grounding DINO获取街景图像的边界框标注,并通过射线追踪将街景框映射到卫星视图。
-
计算映射后的边界框与原始卫星视图边界框的IoU,选择IoU大于0.5的对作为跨视角匹配。
问题生成
-
基于LMM的方法:对于场景推理任务,使用LMM生成问答对。
-
基于规则的方法:对于固定设置的任务,使用规则模板生成问题。
-
基于人工的方法:对于无法从标注中推导答案的任务,由人工标注生成问答对。
质量控制
-
人工检查:去除具有显著时间变化的图像,验证跨视角检测匹配方法的正确性,消除LMM生成数据中的幻觉,确保数据质量和一致性。
实验
实验设计
-
模型评估:实验评估了多种LMMs,包括闭源模型和开源模型。闭源模型包括GPT-4o、Gemini-1.5-Flash和Claude-3.5-Sonnet。开源模型分为单图像类型和多图像类型,包括LLaVA系列、XComposer、InstructBLIP、Mantis系列、VILA系列和InternVL系列。
-
评估协议:问题有两种响应格式:多项选择和开放式。遵循标准设置处理LMMs的响应,确保可重复性,设置温度为0并执行贪婪解码。对于不支持多图像输入的模型,将图像拼接为一个输入。
评估设置
评估模型
-
模型分类:根据训练数据和策略,将开源模型分为单图像类型和多图像类型。
-
单图像类型包括LLaVA系列、XComposer、InstructBLIP和idéfics。
-
多图像类型包括Mantis系列、VILA系列、InternVL系列和LLaVA-NeXT-Interleave。
评估协议
-
包括多选题和开放题两种响应格式。
-
为了确保结果的可比性和一致性,使用标准的响应处理方法。
-
对于多图像输入,将图像拼接为一个输入进行处理。
主要结果分析
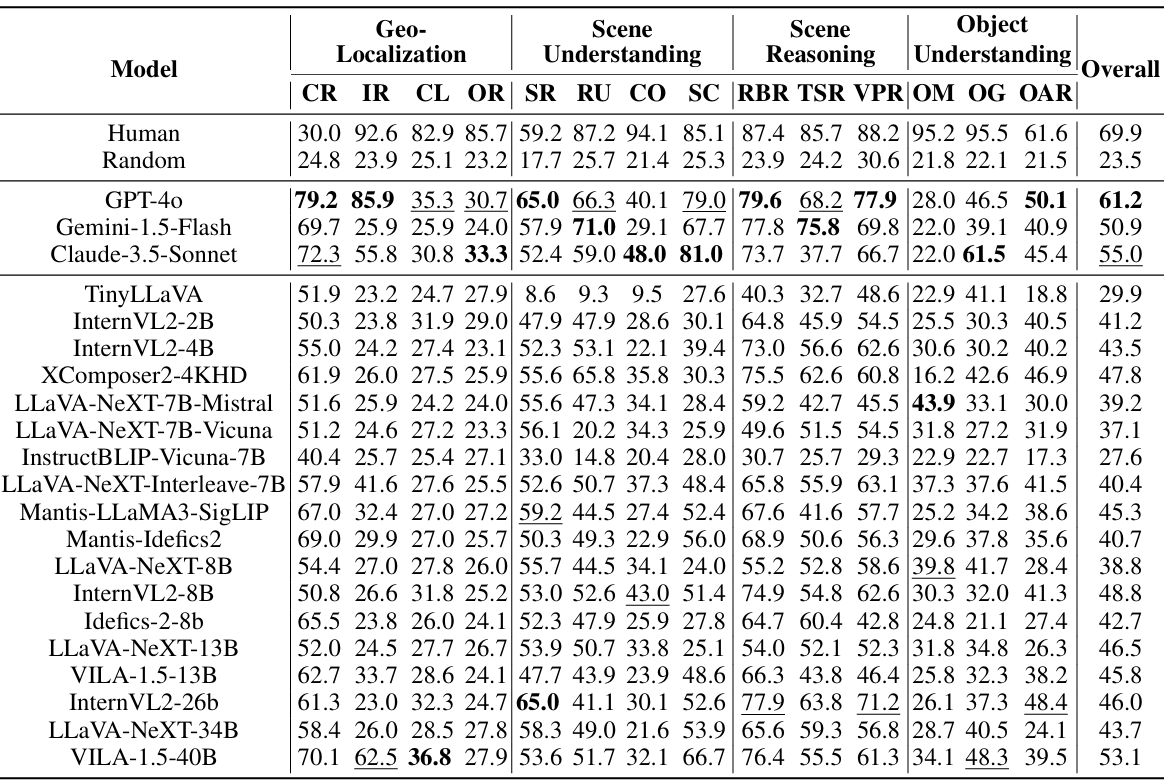
整体挑战
-
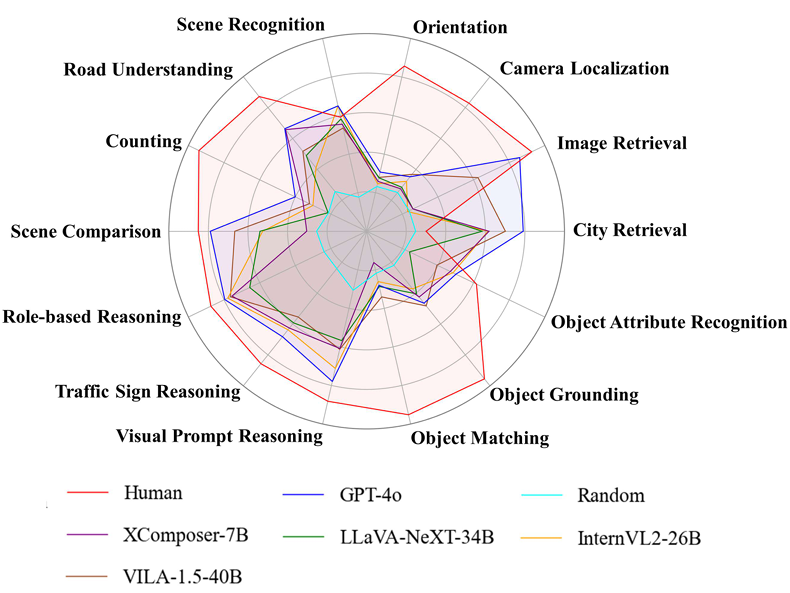
性能表现:UrBench对当前最先进的LMMs提出了显著的挑战。GPT-4o和VILA-1.5-40B分别实现了61.2%和53.1%的准确率。大多数模型在跨视角任务中表现不佳,平均只有36.2%的准确率。
-
任务维度表现:在场景推理任务中,模型表现出色,但在地理定位任务中表现较差。例如,在计数任务中,GPT-4o比人类专家落后54.1%,在物体定位任务中落后67.8%。
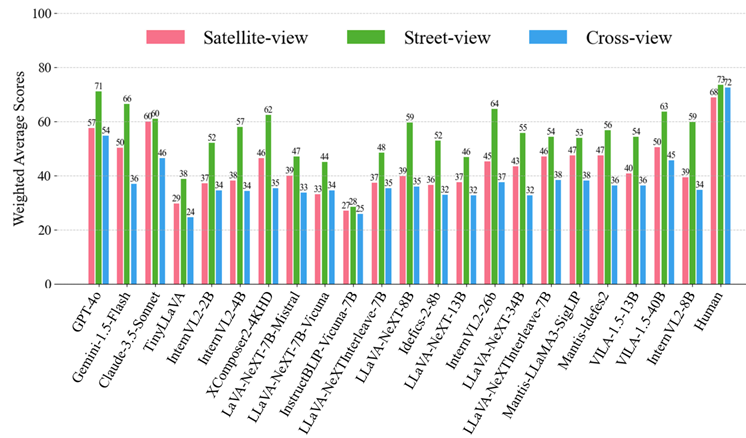
不同视角的一致性
-
模型在不同视角下表现不一致,特别是在跨视角任务中。
-
大多数模型在跨视角任务中的表现不如随机猜测。
详细分析
跨视角关系的理解
-
多个UrBench任务涉及理解卫星视图和街景视图之间的内部关系。
-
尽管专业模型在跨视角任务中表现出色,但通用LMMs在这方面的能力非常有限,平均表现仅比随机猜测高3%。
不同视角的一致性
-
即使在相同地理位置以相同问题提示时,模型在不同视角下的表现也不同。
-
例如,在城市检索任务中,模型在街景和跨视角中的表现优于卫星视图。
-
这可能是因为大多数模型在卫星样本上的训练不足,导致地理定位的知识更倾向于街景图像。
总结
-
论文提出了UrBench,一个用于评估多模态大模型在城市环境中表现的新基准。
-
通过收集和预处理多视角图像数据,设计了多种方法生成高质量的问题样本,并进行了详细的评估和分析。
-
结果表明,当前LLMs在城市环境中的表现仍有显著不足,特别是在跨视角理解和地理定位任务中。
-
研究结果为进一步改进LLMs在城市场景中的应用提供了指导。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









