









-
作者:Qinhong Zhou, Hongxin Zhang, Yutian Chen, Zheyuan Zhang, Xiangye Lin, Jincheng Yang, Lixing Fang, Jiageng Liu, Xinyu Sun, Chuang Gan
-
单位:马萨诸塞大学阿默斯特分校
-
论文标题:VIRTUAL COMMUNITY: A GENERATIVE SOCIAL WORLD FOR EMBODIED AI
-
论文链接:https://openreview.net/pdf?id=aRxLDcxFcL
-
项目主页:https://sites.google.com/view/virtual-community-simulation
主要贡献
-
论文提出了一种能够自动生成大规模3D场景的方法,通过结合生成模型和真实世界的地理空间数据,Virtual Community能够创建具有多种互动对象的场景,支持在开放世界中进行模拟。
-
Virtual Community引入了具有基于场景的角色和社会关系网络的具身智能体。这是首次在社区层面模拟具有社会连接的智能体,增强了模拟的真实性和复杂性。
-
设计了两个挑战任务来展示Virtual Community的能力:路线规划和选举活动,旨在评估具身智能体在开放世界场景中的社会推理和规划能力,提供了测试平台来研究智能体在复杂社会任务中的表现。
-
论文计划将Virtual Community开源,以促进具身AI领域的发展。通过提供一个强大的模拟平台,Virtual Community有望加速在模拟环境中训练具身通用智能的研究进展。
研究背景
研究问题
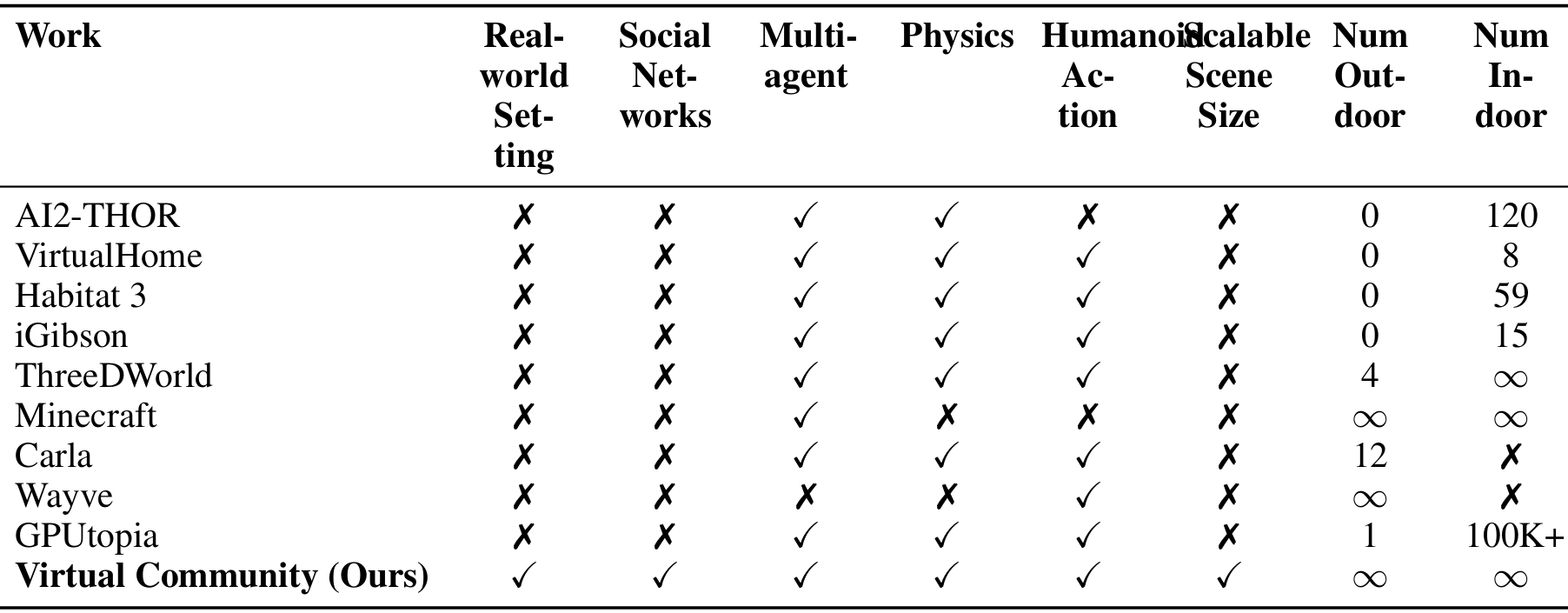
论文主要解决的问题是如何在3D开放世界环境中实现具身智能的模拟,特别是支持具身AI研究的大规模社区场景生成和具身智能体的社会关系网络模拟。
研究难点
该问题的研究难点包括:
-
现有的模拟器难以在大规模3D开放世界环境中实现现实社交互动的扎根;
-
大多数模拟器只能模拟有限数量的智能体且缺乏社交关系;
-
现有方法在数据量、时间跨度和空间跨度上的扩展性有限。
相关工作
-
具身AI模拟:
-
现有的具身AI模拟平台主要集中在家庭环境中的任务模拟,一些平台则扩展到了户外场景。
-
然而,这些平台通常缺乏多样化和可扩展的户外环境,无法容纳更多的智能体并支持更复杂的任务。
-
-
具身社交智能:
-
当前的具身社交智能研究往往局限于小规模的智能体群体和受限的家庭场景,或者简化到2D或网格世界,这限制了在开放世界中模型的发展。
-
Park等人展示了在符号社区中模拟类人智能体的鲁棒性,但忽略了开放世界中的3D感知和现实物理。
-
-
多智能体强化学习和其他规划模型:
-
多智能体强化学习在开放世界设置中面临可扩展性问题,因为随着智能体数量的增加,状态和动作空间的指数增长使得学习有效策略变得困难。
-
此外,MARL方法通常需要大量的训练数据和计算资源,这在实际应用中可能不可行。
-
其他规划模型虽然可能更高效,但在处理开放世界交互的不可预测性时缺乏适应性,可能会依赖于不适用于所有场景的预定义规则或假设,导致次优性能和有限的新情境泛化。
-
-
基础模型和生成模型:
-
随着基础模型的进步,许多工作探索了如何利用它们来构建强大的具身智能体。这些工作还包括使用生成模型来创建模拟场景。
-
与这些工作不同,本文旨在使用生成管道流程来创建开放世界场景和智能体社区,而不是约束在室内场景和任务上。
-
可扩展3D场景生成
论文介绍了如何从现有的3D地理空间数据生成适合具身AI研究的仿真场景。
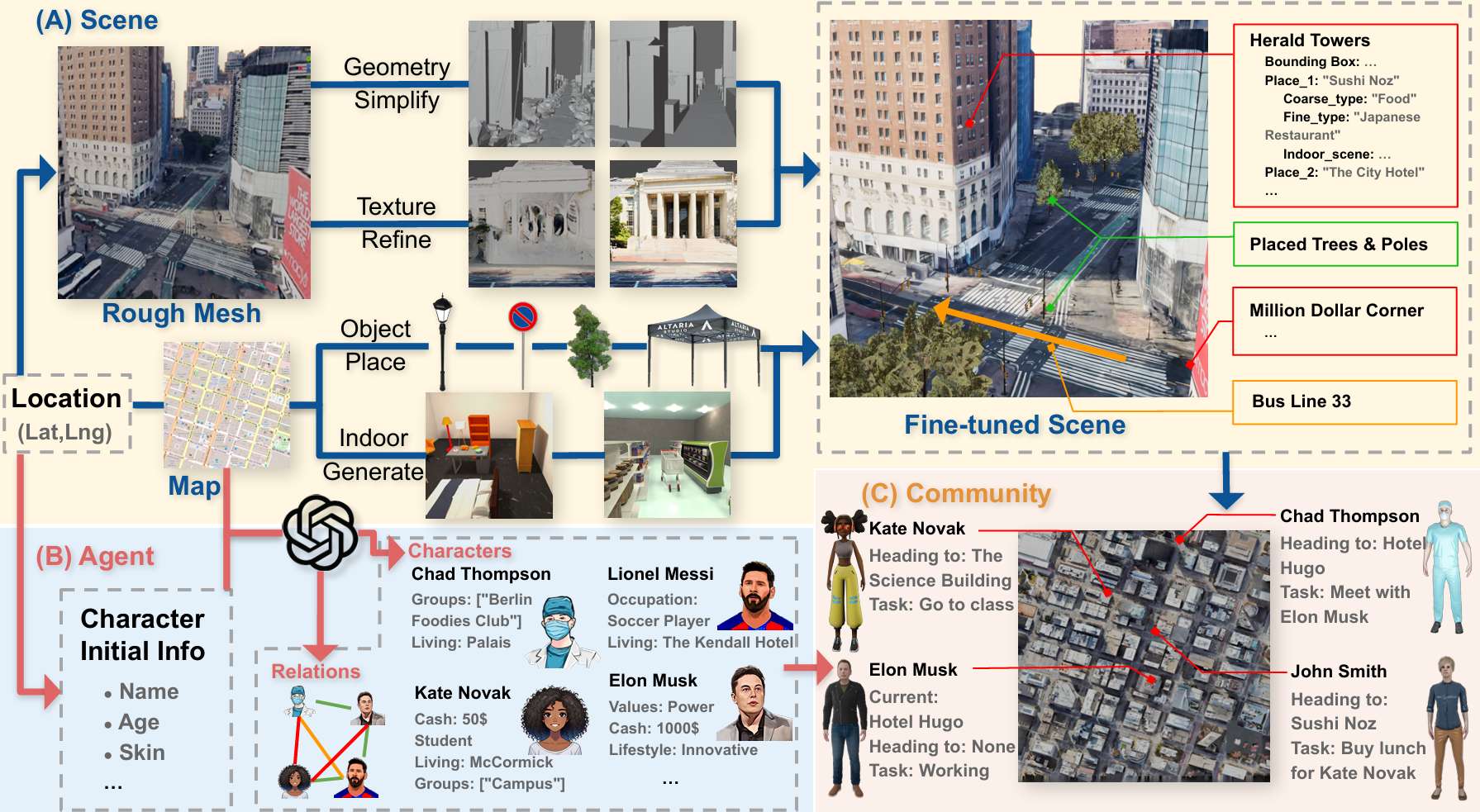
3D地理空间数据的挑战
-
现有的3D地理空间数据虽然数量和多样性丰富,但由于包含噪声、视觉质量不足等问题,不适合直接用于具身AI研究。
-
这些问题包括行人、车辆等瞬态对象的存在,以及从航空影像重建的环境在地面视角下的纹理和几何细节不足。

场景生成管道流程
-
为了克服这些挑战,提出了一个将3D地理空间数据转换为仿真场景的管道流程。
-
这个流程包括四个主要步骤:网格简化、纹理增强、物体放置和自动标注。
网格构建和简化
-
场景被分解为地形、建筑物和装饰屋顶,并对每个部分进行不同的操作以重建场景。
-
地形使用稀疏参考高程点和双线性插值构建,然后通过OpenStreetMap (OSM) 服务提供的信息生成简单且拓扑合理的网格。
-
建筑网格根据Google 3D瓦片的几何形状进行调整,以减少噪声并提高物理模拟和渲染性能。

纹理质量增强
-
使用基于稳定扩散的修复方法去除纹理中的噪声和修复缺失或损坏的区域。
-
通过结合街景图像和超分辨率工具,进一步增强了纹理的细节,提高了视觉质量。
物体放置和交互性提升
-
使用生成方法在环境中放置互动物体(如自行车和帐篷),并通过OpenStreetMap (OSM) 数据集的注释确定物体的类型和位置。
-
这些生成的对象被赋予物理属性,以便在模拟中与智能体无缝互动。
场景自动标注
-
使用地理空间数据自动标注场景,集成来自OpenStreetMap和其他GIS数据库的元数据,标记建筑物、道路和其他地标。
-
这种标注支持智能体访问位置特定信息,并促进需要理解空间上下文的任务,如导航和基于位置的决策。

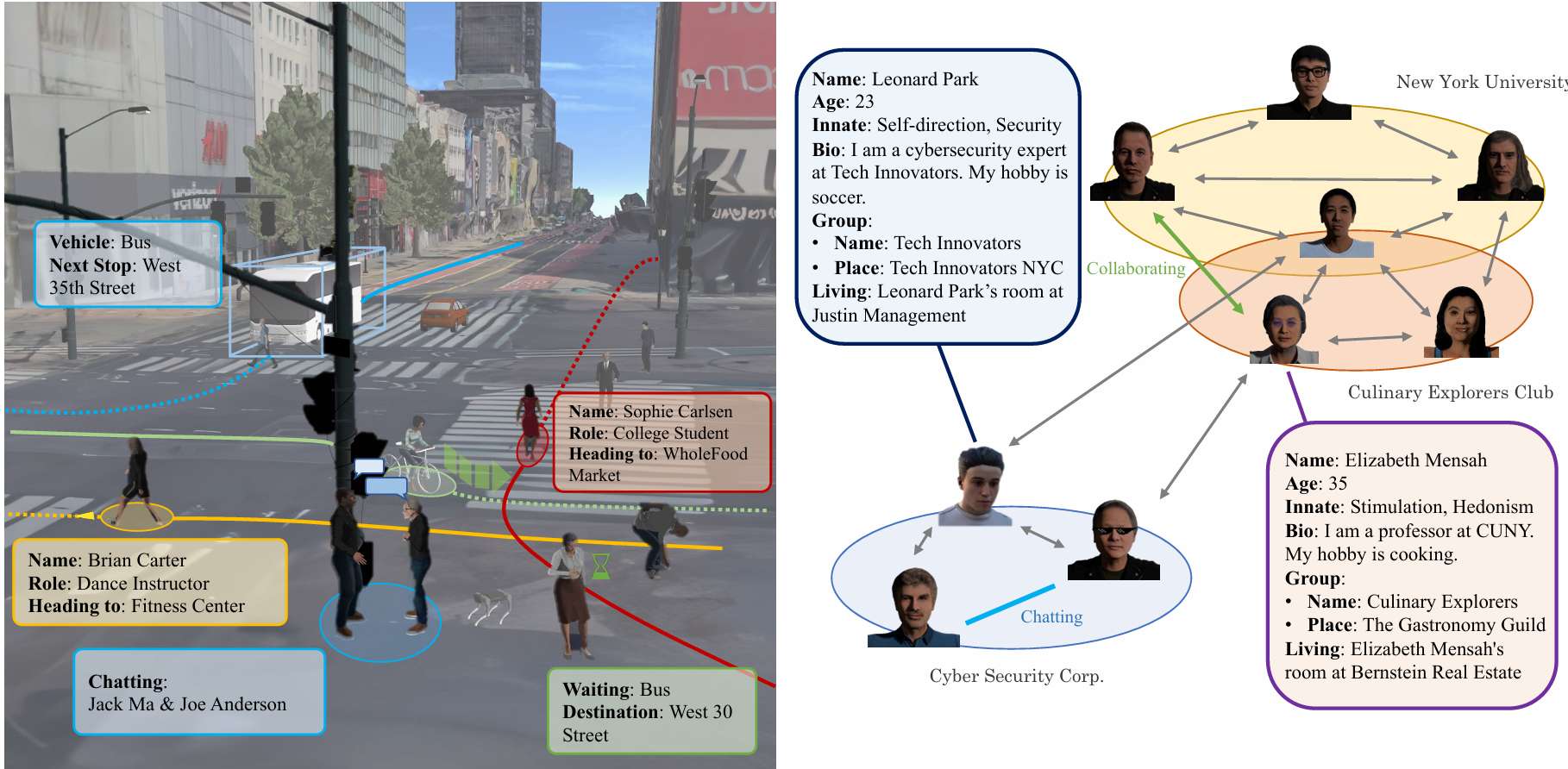
具有社交关系的具身智能体社区
介绍了如何在生成的多样化场景中引入具身智能体社区,这些智能体具有基于场景的角色和社交关系网络。
基于场景的角色和社交关系网络生成
-
利用大型语言模型(LLM)的知识来生成智能体的角色档案和个性,使其与场景紧密结合。
-
输入到LLM的信息分为两部分:一部分是关于场景的相关信息,包括场景名称和各种地点的详细信息;另一部分是关于智能体的外观细节,以确保其视觉属性与生成的角色档案一致。
-
LLM根据这两部分信息生成智能体的角色档案及其社交关系。
角色档案和社交关系的结构
-
角色档案包括基本属性,如姓名、年龄、职业、个性和爱好,这些属性影响智能体的日常决策。
-
社交关系被结构化为群体,每个群体包含一组智能体,并附有文本描述和指定的活动地点,从而将这些智能体连接成一个有凝聚力的社区,支持丰富的复杂社交互动。

角色验证模块
-
论文实现了一个角色验证模块,用于检查生成的角色档案是否准确地与场景相关联。
-
如果验证失败,LLM会根据验证模块的反馈重新生成角色档案,直到通过验证。
-
实验表明,通常经过1-2轮提示即可通过验证。
人类化身实现
-
论文从Mixamo网站获取了不同性别、职业和外貌的12个化身皮肤模型,并将其集成到Virtual Community中。
-
每个皮肤模型包括71个骨骼关节,可以适应SMPL-X和FBX格式的动画序列。
-
为了减少动画播放时的计算负载,论文优化了皮肤模型,减少了3D皮肤网格的顶点数量。
动作控制
-
结合SMPL-X人体骨架和创建的化身皮肤来模拟人类化身。化身的动作由SMPL-X姿态向量、全局平移和旋转向量参数化。
-
基于这些姿态表示,计算每个化身的皮肤网格。动作模型支持超过15种不同的动作,如行走、拾取物体和进入各种车辆。
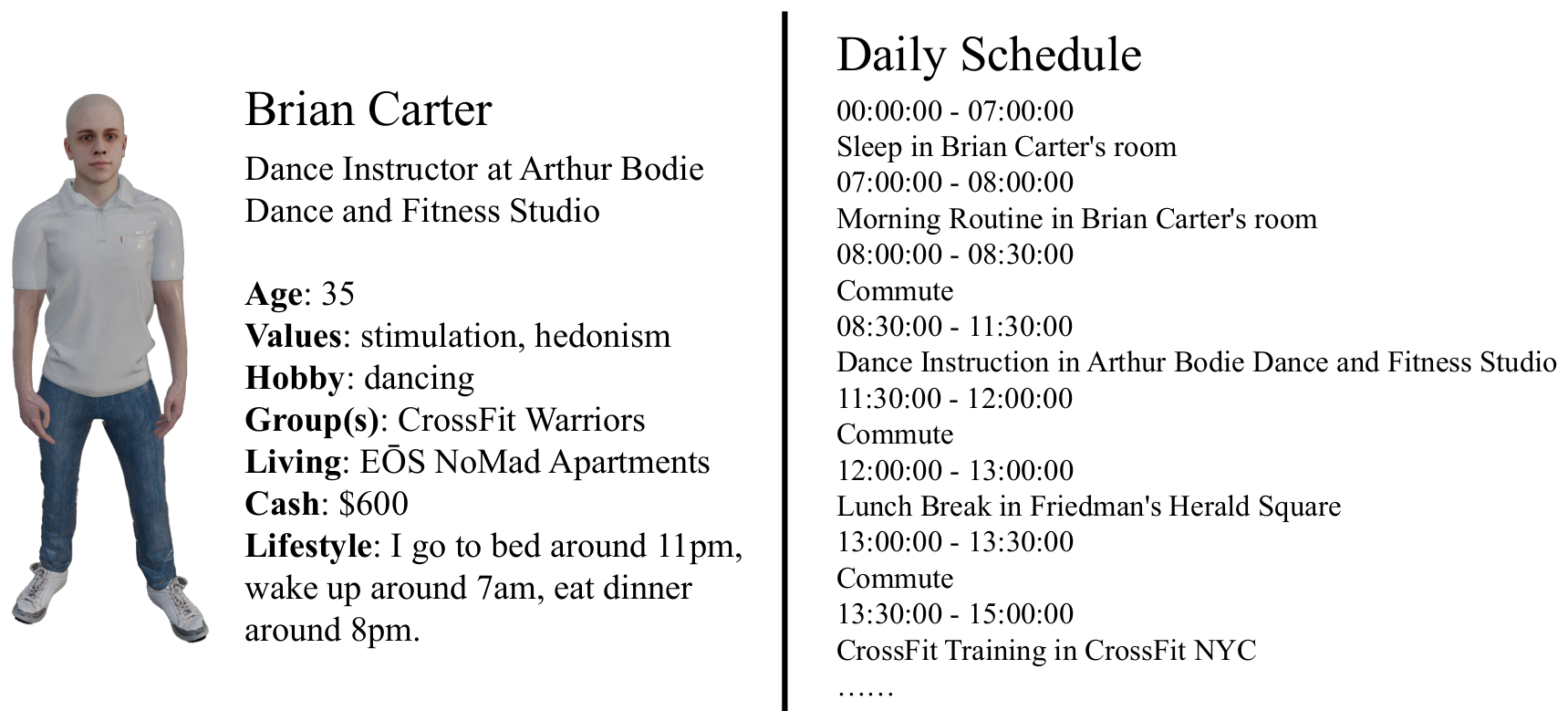
日常计划生成
-
在给定场景角色的基础上,使用基础模型为每个智能体生成日常计划。
-
生成的计划以结构化的方式表示,每个活动包括开始时间、结束时间、活动描述和相应的活动地点,并考虑了在不同地点之间进行活动所需的通勤时间。

虚拟社区中的开放世界和社会挑战
-
介绍了在Virtual Community中引入的两个开放世界和社会挑战任务:路线规划(Route Planning)和选举活动(Election Campaign)。
-
这些任务旨在评估具身智能体在开放世界场景中的规划能力和社交智能。
路线规划
任务定义
-
为了在社区中过日常生活,具身智能体需要能够规划从一个地方到另一个地方的路线。
-
在这个任务中,智能体需要根据日程安排每天往返5-7次。智能体可以使用公共汽车和沿路的共享单车作为交通工具。
-
每一步模拟中,智能体会接收到RGB-D图像、当前位置、日程安排和社区交通信息的观察结果。
-
智能体的动作空间包括前进、转向、乘坐/离开公共汽车和共享单车等。
基线方法
-
比较了三种基线智能体:基于规则的智能体、基于蒙特卡洛树搜索(MCTS)的智能体和基于大型语言模型(LLM)的智能体。
-
基于规则的智能体总是选择直接向目标位置行走;
-
MCTS智能体通过模拟各种决策来选择乘坐公共汽车;
-
LLM智能体将任务信息转化为提示,查询LLM生成通勤计划。
评估指标
-
使用到达率和平均耗时来评估智能体的表现。
实验结果
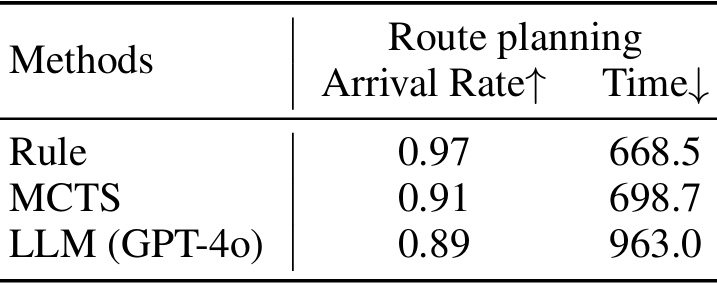
结果表明,基于搜索和LLM的智能体未能有效利用公共交通选项,导致通勤时间和到达率不如基于规则的智能体。
选举活动
任务定义
-
在这个任务中,社区中的两个智能体被指定为候选人。候选人需要在社区中寻找潜在选民并通过直接沟通说服他们投票。
-
选举在一天结束时进行,获胜者由每个候选人获得的选票百分比决定。
-
由于预先存在的社交关系,一些选民可能对某些候选人有初始偏好,因此候选人需要制定策略来影响和改变选民的意见。
基线方法
-
使用基于LLM的智能体作为基线。智能体的行为通过迭代提示LLM来确定下一个要访问的选民。候
-
选人导航到选民的位置并进行竞选演讲,这一过程重复进行,直到模拟结束。
实验结果

实验显示,不同的候选人采取了不同的策略来吸引选民,显示出LLM驱动的智能体在选举活动中的行为差异。
总结
-
论文介绍了Virtual Community,用于具身AI研究的生成性社交世界平台。
-
通过结合大规模的真实地理空间数据和先进的生成模型,Virtual Community能够生成无限的场景和扎根的社交智能体社区。
-
论文提出的路线规划和选举活动任务展示了该平台在开放世界和社会挑战中的潜力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









