








-
作者:WENPENG XING, MINGHAO LI, MOHAN LI, and MENG HAN
-
单位:浙江大学
-
论文标题:Towards Robust and Secure Embodied AI: A Survey on Vulnerabilities and Attacks
-
论文链接:https://arxiv.org/pdf/2502.13175
主要贡献
-
论文首次系统地将具身人工智能(Embodied AI)系统的脆弱性分为外源性和内源性两类,并详细分析了这些脆弱性的来源。
-
深入研究了针对具身AI系统的独特对抗攻击范式,特别是对感知、决策和具身交互的影响。
-
探讨了针对语言大模型(LLMs)和视觉-语言大模型(LVLMs)的攻击向量,如越狱攻击和指令误解。
-
提出了多种策略来提高具身AI系统的安全性和可靠性。这些策略包括改进世界对齐、增强多模态集成以及实施鲁棒的控制和适应机制。
1 介绍
-
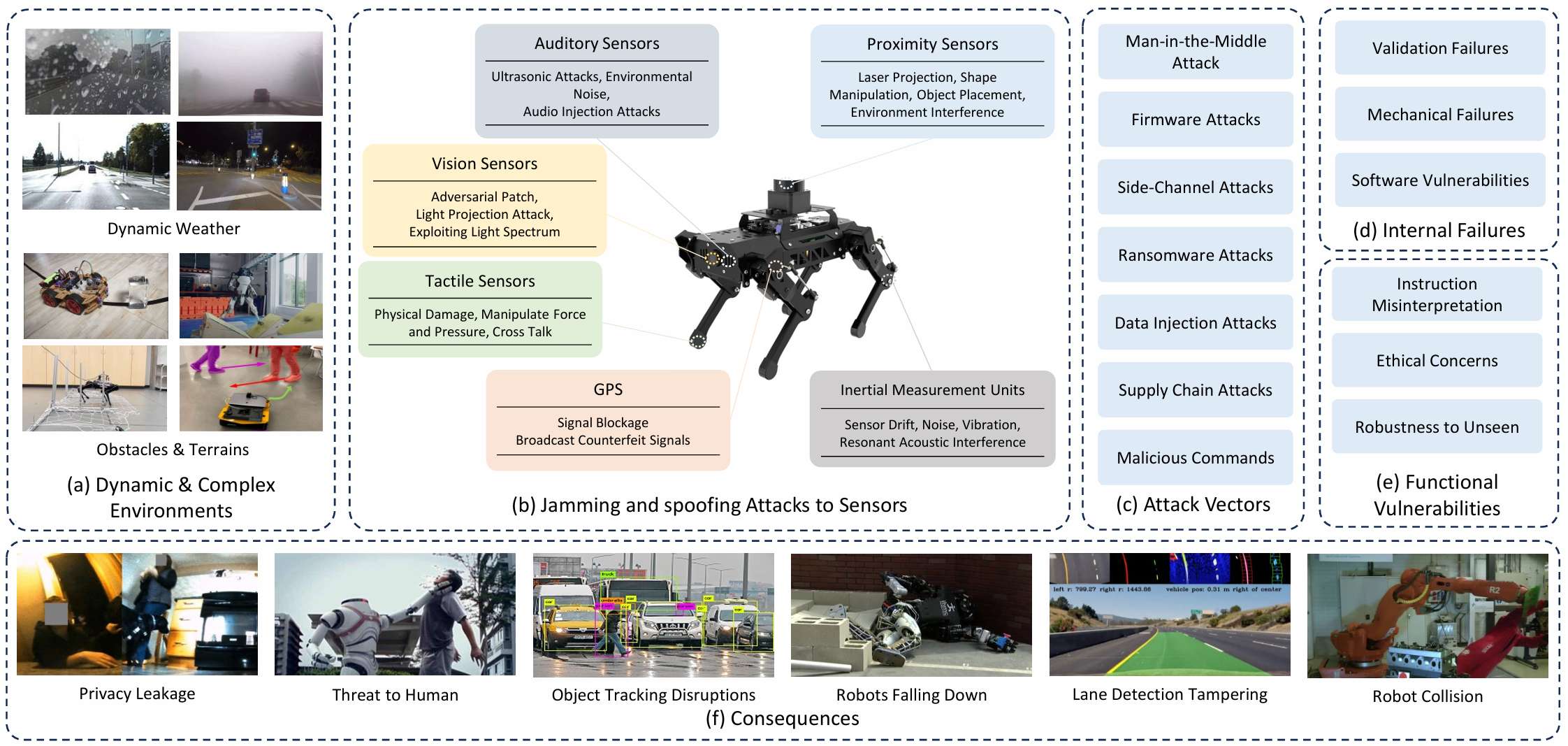
论文指出,AI技术的快速进步使得具身AI成为处理复杂现实任务的关键技术。这些系统结合了感知、决策和执行能力,在多个领域表现出色。
-
尽管具身AI系统在处理复杂任务方面表现出色,但它们也面临着一系列脆弱性。这些脆弱性源于动态和复杂的环境、传感器干扰和欺骗攻击以及系统故障。
- 论文识别并总结了具身系统的三个关键特性:自主性、具身性和认知能力。
-
自主性指的是系统能够做出独立决策的能力;
-
具身性是指系统与物理环境互动的能力;
-
认知能力则涉及系统理解和解释其行为的能力。
-
-
论文强调,这些特性引入了新的安全挑战,例如在复杂环境中做出错误决策的风险,以及在交互过程中被操纵的可能性。
-
论文的目标是提供一个全面的框架,以理解具身AI系统中脆弱性与安全性之间的相互作用,并提出增强系统安全性和可靠性的策略。
2 脆弱性分类
2.1 外源性脆弱性
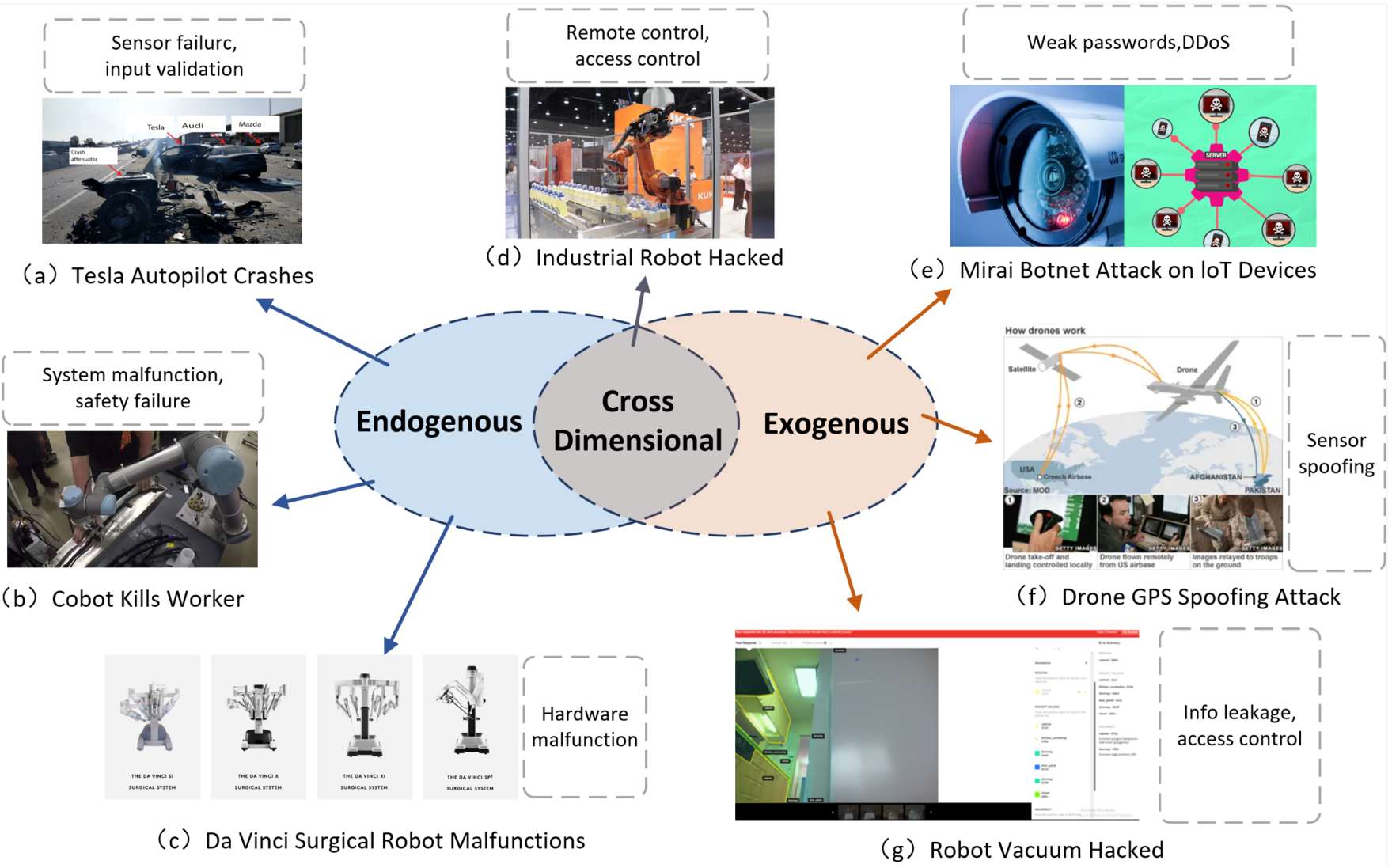
外源性脆弱性源自系统与其环境的交互或外部恶意行为者的攻击。
2.1.1 动态环境因素
-
具身AI系统依赖于传感器数据进行感知和交互。
-
环境变化或对抗性扰动可能导致深度神经网络误判,从而带来安全风险。
-
传感器的失败与误读可能导致严重的安全事故,例如自动驾驶车辆的事故。
2.1.2 物理攻击
-
物理攻击涉及直接硬件篡改,以操纵组件、破坏性能或造成物理损坏。
-
随着工业4.0的发展,攻击面扩大,暴露出新的威胁。
2.1.3 对抗性攻击
-
对抗性攻击通过在输入数据中引入不可察觉的扰动来欺骗深度学习模型。
-
这些攻击在白盒和黑盒设置中均可执行,特别关注安全关键应用中的实时感知和决策。
2.1.4 网络安全威胁(
-
随着具身AI系统与物联网(IoT)和云基础设施的集成,它们面临广泛的网络安全攻击。
-
攻击者可能利用弱的安全配置(如默认密码或不加密的通信)来获取未经授权的访问或破坏系统操作。
2.1.5 人机交互和安全协议失败
-
协作机器人(cobots)和无人机在设计上与人共存,如果其安全协议被破坏,将带来显著的安全风险。
-
人为错误或恶意意图可能加剧这些风险。
2.2 内源性脆弱性
内源性脆弱性源自系统内部的硬件故障、软件漏洞和设计缺陷。这些风险通常更可预测,但如果不加以缓解,仍可能导致严重后果。
2.2.1 传感器和输入验证失败
-
传感器故障或输入验证不当可能导致环境评估错误,从而导致不安全的行动。
-
例如,自动驾驶车辆的传感器故障可能导致事故。
2.2.2 硬件和机械故障
-
机械部件的磨损和故障可能导致系统操作中断,特别是在关键应用中可能导致严重后果。
-
例如,手术机器人的机械故障可能需要紧急干预。
2.2.3 软件漏洞和设计缺陷
-
软件漏洞和设计缺陷可能危及系统的安全性和可靠性。
-
例如,自动驾驶车辆的控制算法设计不当可能导致不安全的驾驶行为。
2.3 跨维度脆弱性
一些风险可能跨越外源性和内源性维度,其中外部因素加剧了内部脆弱性。
2.3.1 指令误解
-
在交互任务中,指令误解可能导致危险的行为或事故。
-
例如,在Talk2Car任务中,指令误解可能导致危险的驾驶行为。
2.3.2 交互智能体的伦理和安全影响
-
在EQA(具身问答)等任务中,智能体提供错误或误导性信息可能产生严重后果。
-
例如,在医疗或自动驾驶等关键应用中,确保智能体透明并能够处理不确定性至关重要。
2.3.3 未见环境中的鲁棒性缺乏
-
许多任务测试智能体在未见环境中的表现,但智能体往往难以泛化到新环境。
-
例如,在导航任务中,智能体可能在未见环境中卡住或导致危险情况。
3 脆弱性攻击
3.1 脆弱性分析
3.1.1 训练和数据限制
-
训练范式:LLMs的训练主要集中在自回归预测下一个词上,这与生成有用、真实和无害响应的目标存在偏差。安全考虑通常不是训练过程的一部分,因此模型可能容易受到对抗性操纵。
-
数据集问题:模型通常在未审查的互联网数据上进行预训练,这可能导致引入偏见和有毒内容。这种数据集的使用增强了模型被对抗性攻击操纵的风险。
-
安全微调:尽管可以使用安全数据集进行微调来缓解某些问题,但这种方法的效果有限。微调通常只能在一定程度上减少模型的攻击面。
3.1.2 神经网络的对抗性脆弱性
-
非线性行为:尽管深度神经网络具有非线性架构,但在高维输入空间中表现出近线性行为,使其容易受到对抗性示例的影响。
-
对抗性示例:小的输入扰动可能导致模型预测的显著偏移。例如,FGSM和Carlini & Wagner(CW)攻击展示了如何通过简单的扰动来欺骗模型。
-
输入空间覆盖:训练期间输入空间的不完整覆盖导致盲点,增加了过拟合和泛化能力下降的风险。
-
梯度问题:在决策边界附近,梯度较大,进一步放大了模型的脆弱性。
-
高频成分敏感性:模型对高频成分高度敏感,这可能导致人类感知和模型行为之间的不匹配,从而被攻击者利用。
3.1.3 攻击面的扩展
-
多模态输入:LVLMs处理多模态输入(如文本和视觉),这增强了模型的能力,但也引入了新的脆弱性。
-
跨模态传播:一个模态中的对抗信号可以传播到其他模态,放大其影响。例如,视觉信号的操纵可能会干扰文本推理。
-
应用扩展:随着LVLMs在具身AI和传感器驱动系统中的应用越来越广泛,攻击面也随之扩大。Zhang等人展示了对抗性攻击在自动驾驶中的风险。
3.1.4 从文本到动作的转换
-
传统攻击不适用:传统的越狱攻击可能不完全适用于具身系统,因为这些系统不仅需要生成文本,还需要规划和执行物理世界的动作。
-
新攻击范式:具身LLMs必须生成文本并规划和执行动作,这要求一种新的攻击范式,考虑到具身系统在动作规划和执行方面的独特挑战。
-
结构化输出:攻击者可以利用结构化输出(如JSON或YAML)来操纵系统的行为,导致不安全或意外的动作。
3.2 对抗性威胁模型
3.2.1 攻击者能力
攻击者的能力决定了他们能够对系统施加何种类型的攻击。根据攻击者对系统的了解和控制程度,攻击能力可以分为以下几类:
白盒攻击
-
定义:攻击者拥有系统的完整访问权限,包括系统的架构、参数和API。
-
常见方法:包括FGSM(Fast Gradient Sign Method)、PGD(Projected Gradient Descent)、APGD(Accelerated Projected Gradient Descent)和CW(Carlini & Wagner)攻击。
-
特点:由于攻击者完全了解系统,他们可以创建高度针对性和复杂的攻击。
灰盒攻击
-
定义:攻击者具有部分访问权限,通常通过高层API或外部接口进行交互,但不控制底层组件。
-
常见方法:攻击者可能利用外部输入(如传感器数据或用户命令)中的漏洞。
-
特点:灰盒攻击介于白盒和黑盒之间,攻击者需要在不完全了解系统的情况下进行攻击。
黑盒攻击
-
定义:攻击者没有系统的内部知识,只能通过与系统的输入查询进行交互。
-
常见方法:攻击者通过输入查询来操纵系统,而不需要了解系统的内部结构。
-
特点:尽管攻击者无法直接访问系统内部,但他们仍然可以通过外部输入来造成损害。
3.2.2 攻击目标
攻击目标取决于攻击者的具体目标和系统的特性。在具身AI系统中,常见的攻击目标包括:
感知系统
-
目标:攻击者可能针对传感器(如摄像头、LiDAR和GPS)进行攻击,以干扰系统的环境感知能力。
-
后果:传感器欺骗可能导致系统误判环境,从而做出错误的决策。例如,自动驾驶车辆可能因传感器欺骗而未能检测到障碍物。
控制系统
-
目标:攻击者可能针对系统的控制算法进行攻击,以诱导不安全的动作。
-
后果:控制系统被操纵可能导致系统执行危险的动作,如失控或违反安全协议。
通信通道
-
目标:攻击者可能针对系统的无线通信进行攻击,以干扰系统的协调和控制。
-
后果:通信通道被干扰可能导致系统无法接收关键更新或命令,从而影响其正常运行。
3.3 攻击类型

3.3.1 外源性脆弱性中心攻击
-
数据为中心的攻击
-
数据中毒:攻击者在训练集中注入恶意数据,导致模型学习错误的关联。这种攻击可能导致安全关键应用(如自动驾驶或机器人手术)中的失败。
-
-
输入操纵攻击
-
对抗性攻击:对抗性攻击通过对输入数据进行微小扰动来欺骗机器学习模型,导致错误的模型预测。这些攻击在感知系统中尤为危险。
-
传感器欺骗攻击:攻击者通过操纵传感器数据来误导系统,这些攻击发生在物理域中,直接操纵环境或传感器信号。
-
命令注入:在基于自然语言处理(NLP)的系统中,攻击者通过语音或文本输入注入恶意命令,触发意外动作。
-
越狱攻击:攻击者通过精心设计的Prompt绕过模型的安全机制,引发安全风险。越狱攻击包括Prompt注入和对抗性Prompt生成。
-
-
系统和基础设施攻击
-
API操纵:攻击者利用暴露的API发送恶意命令,导致系统行为异常。
-
拒绝服务攻击:攻击者通过大量输入查询使系统过载,导致系统响应缓慢或无响应。
-
中间人攻击:攻击者利用无线通信中的漏洞截获和操纵数据,威胁系统的安全性。
-
3.3.2 内源性脆弱性中心攻击
-
模型为中心的攻击
-
模型提取攻击:攻击者通过逆向工程或查询基提取方法复制模型的功能或发现漏洞。
-
-
系统和基础设施攻击
-
供应链攻击:攻击者通过开发或部署阶段的目标漏洞插入恶意代码。
-
侧信道(Side-Channel)攻击:攻击者利用间接数据泄露(如时序或功耗)来推断敏感信息。
-
固件攻击:攻击者利用低级软件来获得持久控制,绕过高级安全机制。
-
3.3.3 跨维度脆弱性中心攻击
- 复杂和协调的攻击
-
高级持续性威胁:攻击者具有资源和专业知识,能够长期、隐蔽地进行攻击。
-
勒索软件攻击:攻击者加密关键文件或锁定控制软件,使系统无法操作,直到支付赎金。
-
3.4 网络安全威胁
3.4.1 中间人攻击
-
定义:MitM攻击利用系统对实时通信的依赖,尤其是在无线协议上的通信,来截获和操纵数据。
-
目标:攻击者可以在系统与外部服务(如云服务器或远程控制单元)交换数据时进行拦截和修改。
-
后果:在自动驾驶系统中,MitM攻击可能导致导航或传感器数据被篡改,从而引发不安全的重定向或环境误判。在机器人系统中,攻击者可能篡改控制命令,导致任务失败或物理伤害。
-
防御措施:使用强加密协议(如TLS或IPsec)和保护实时入侵检测系统(IDS)可以帮助减轻MitM攻击的风险。
3.4.2 传感器到模型攻击
-
定义:这类攻击针对传感器数据的完整性,传感器数据是具身AI系统感知和决策的基础。
-
目标:攻击者通过注入虚假或恶意数据来操纵系统对环境的理解。
-
后果:在自动驾驶中,攻击者可能注入伪造的LiDAR或摄像头数据,导致车辆误判障碍物,引发不必要的规避动作或碰撞。在工业机器人中,攻击者可能操纵传感器数据,导致生产错误或安全风险。
-
防御措施:使用鲁棒的传感器融合算法和异常检测技术可以帮助识别不一致的传感器读数,从而抵御数据操纵。
3.4.3 固件攻击
-
定义:固件攻击针对嵌入式系统的低级软件,这些软件控制硬件组件的功能。
-
目标:攻击者通过篡改关键组件(如传感器或执行器)的固件来获得持久控制权。
-
后果:在自动驾驶无人机中,恶意固件更新可能导致飞行控制参数改变,引发不稳定或危险行为。
-
防御措施:采用安全启动过程和运行时固件验证技术可以防止未经授权的固件加载和篡改。
3.4.4 Side-Channel Attacks
-
定义:这类攻击利用系统的物理特性(如功耗、电磁辐射或时序信息)来提取敏感数据。
-
目标:攻击者通过监控系统的物理特性来推断加密密钥或其他敏感信息。
-
后果:在具身系统中,攻击者可能通过监控电源消耗模式来破解加密通信,从而破坏系统的保密性。
-
防御措施:使用抗侧信道攻击的加密算法可以确保关键操作的完整性和隐私。
3.4.5 勒索软件攻击
-
定义:勒索软件攻击通过加密关键系统文件或锁定控制软件来使系统无法操作。
-
目标:攻击者要求支付赎金以恢复系统功能。
-
后果:在工业和运营环境中,勒索软件攻击可能导致整个工作流程的中断,造成重大运营和财务损失。
-
防御措施:实施强大的备份和恢复系统,以及主动检测机制,可以帮助减轻勒索软件的影响。
3.4.6 供应链攻击
-
定义:这类攻击利用现代硬件和软件供应链的复杂性,在制造或开发过程中引入恶意组件或代码。
-
目标:攻击者可能在第三方硬件或软件中植入后门或恶意代码。
-
后果:在具身系统中,攻击者可能通过硬件后门进行远程控制或监视。
-
防御措施:采用硬件验证技术和安全的软件开发生命周期(SDL)实践可以帮助防止供应链攻击。
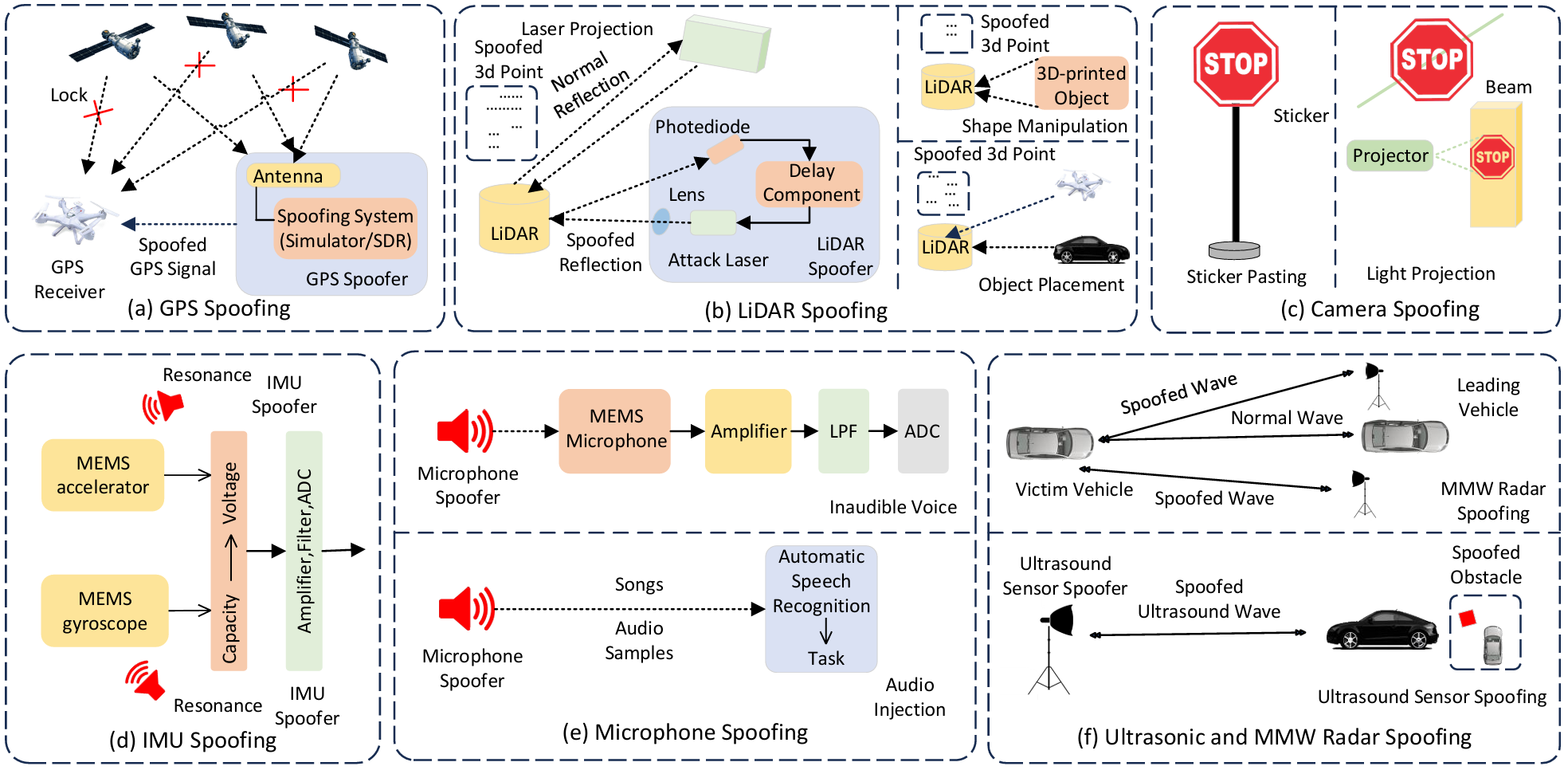
3.5 传感器欺骗攻击
3.5.1 攻击触觉传感器
-
触觉传感器用于测量力、扭矩或压力分布,使机器人能够感知和响应物理交互。
-
这些传感器在需要精确操作的场景中至关重要,如抓取易碎物体或进行工具操作。
- 然而,触觉传感器容易受到物理磨损和对抗性攻击的影响:
-
物理磨损:特别是电阻式传感器,容易因物理磨损而影响耐用性和准确性。
-
对抗性攻击:攻击者可以通过篡改嵌入式传感器来干扰感知,导致机器人做出错误的反应。例如,攻击者可以通过干扰力或压力的读数来破坏决策过程。
-
3.5.2 攻击视觉传感器
-
视觉传感器(如RGB、RGB-D和立体相机)在机器人系统中用于感知和交互环境。
-
这些传感器提供丰富的视觉数据,使机器人能够执行复杂的任务,如对象识别、导航和操作。
- 然而,视觉传感器特别容易受到对抗性攻击的影响:
-
对抗性贴纸:通过在物体上放置视觉异常的贴纸,攻击者可以欺骗视觉系统做出错误的分类。
-
光投影攻击:使用激光指针或投影仪在真实世界的表面上投射对抗性图像。
-
光谱利用:通过利用人眼不可见的电磁波谱部分(如红外光)来操纵相机传感器。
-
3.5.3 攻击接近传感器
-
接近传感器(如超声波、红外和LiDAR)用于检测障碍物、测量距离和确保机器人的安全导航。
-
这些传感器在机器人系统中用于避障和定位。
- 然而,它们的工作原理使得它们容易受到信号干扰和欺骗攻击的影响:
-
信号干扰和操纵:攻击者可以通过操纵传输或接收的信号来创建虚假对象或扭曲实际障碍物的位置。
-
环境因素:多路径反射、表面反射率的变化或恶劣天气(如雨、雾或雪)会降低传感器的性能。
-
3.5.4 IMU欺骗攻击
-
惯性测量单元(IMU)提供关于方向、速度和加速度的关键数据,用于动态环境中的运动跟踪、导航和控制。
-
IMU通常与其他传感器(如GPS、气压计或视觉系统)结合使用,以提高精度和补偿漂移等问题。
- 然而,IMU容易受到噪声和攻击者的干扰:
-
噪声和攻击:攻击者可以通过引入噪声或操纵校准来导致不准确的传感器读数,从而影响系统的行为。
-
3.5.5 GPS欺骗攻击
-
全球定位系统(GPS)广泛用于室外环境的定位、速度和时间估计。
- 然而,GPS信号容易受到阻塞、干扰和欺骗攻击的影响:
-
信号干扰:攻击者可以使用GPS欺骗器广播比合法卫星更强的信号来中断受害者的连接。
-
位置操纵:一旦受害者锁定到欺骗信号,攻击者可以通过改变伪距值和修改导航消息来操纵感知位置。
-
3.5.6 听觉欺骗攻击
-
听觉传感器(如MEMS麦克风)在语音控制界面中用于机器人系统中,使机器人能够解释和执行用户命令。
- 然而,这些传感器容易受到超声波攻击的影响:
-
不可听声音攻击:攻击者可以将高频超声波信号转换为不可听范围,注入恶意命令。
-
音频注入攻击:恶意命令可以嵌入看似正常的音频信号中,使其难以与合法输入区分开来。
-
3.6 LLMs与LVLMs的对抗攻击
3.6.1 基于Logits的攻击
-
基于Logits的攻击主要针对解码过程,通过影响token选择来产生有害或误导的内容。
-
这些方法通过迭代调整Logits来对齐token分布,以符合攻击者的目标。
- 尽管这些方法非常有效,但它们可能会牺牲生成文本的自然性和连贯性。最近的方法包括:
-
COLD-Attack:Guo等人提出了一种受控文本生成框架,用于自动化和优化Jailbreak Prompt的创建。COLD-Attack展示了在ChatGPT、Llama-2和Mistral等模型上的高成功率。
-
Logit-Based Watermarking:Wong等人提出了一种Logits扰动方法,用于在LLM生成的文本中嵌入水印,以提高检测鲁棒性和文本质量。然而,这种方法容易受到攻击者移除或更改水印的威胁。
-
VT-Attack:Wang等人提出了一种针对LVLMs的攻击方法,通过在编码的视觉token上创建对抗性示例来导致视觉感知的误解,从而产生错误或有害的输出。
-
3.6.2 基于微调的攻击
-
基于微调的攻击涉及使用恶意或精心设计的训练数据集重新训练目标模型,从而增加其对对抗性输入的敏感性。
- 最近的进展包括:
-
Minimal Fine-tuning:Qi等人展示了使用少量有害样本来微调LLMs可以显著降低其安全性。即使在主要由良性数据组成的数据集中,微调过程也可能无意中降低模型的安全性。
-
Oracle-based Fine-tuning:Yang等人提出通过查询一个Oracle LLM来构建微调数据集。在这些数据集上微调的模型对Jailbreak尝试表现出更高的脆弱性。
-
3.6.3 对抗性Prompt生成
该部分分类了对抗性Prompt生成的关键技术,包括前缀/后缀攻击、Prompt重写、模板完成、LLM生成攻击、文本嵌入微调和基于RAG的Jailbreak。
- 前缀/后缀攻击:利用梯度生成对抗性前缀或后缀,引导模型产生有害输出。这些攻击类似于文本生成任务中的对抗性示例。
-
Greedy Coordinate Gradient:Zou等人提出的GCG是一种基于梯度的Jailbreak攻击,通过计算基于梯度的替换来优化离散的对抗性后缀。
-
Adversarial Suffix Embedding Translation Framework:Wang等人提出优化连续的对抗性后缀,并将其翻译成人类可读的形式。
-
AutoDAN:Zhu等人提出的AutoDAN是一种可解释的基于梯度的Jailbreak攻击,使用单令牌优化算法生成语义上有意义的后缀。
-
- Prompt重写攻击:通过修改Prompt来利用模型在未充分代表的场景中的脆弱性。这些方法包括加密策略、语言策略和遗传策略。
-
Cryptographic Strategies:Yuan等人提出使用加密Prompt来绕过内容审核。
-
Linguistic Strategies:Deng等人展示了将不安全Prompt翻译成低资源语言以绕过LLM的安全机制。
-
Genetic Strategies:Liu等人开发了一个层次化的遗传算法来生成隐秘的Jailbreak Prompt。
-
- 模板攻击:设计复杂的模板来利用模型的固有能力,如角色扮演、上下文理解和代码执行,以绕过其安全机制。
-
Scenario Nesting:通过将恶意意图嵌入看似无害的上下文中,攻击者可以设计欺骗性场景来操纵模型执行受限动作。
-
Contextual Learning:将对抗性输入无缝嵌入上下文中,影响模型生成意外或有害的输出。
-
Code Injection:引入恶意代码片段以利用模型的编程和执行能力。
-
- LLM生成攻击:利用LLMs的生成能力来模拟攻击者,自动化和高效地创建对抗性Prompt。
-
Persuasive Adversarial Prompts:Zeng等人训练LLMs生成有说服力的对抗性Prompt。
-
Prompt Automatic Iterative Refinement:Chao等人提出了一个协作框架,其中多个LLMs迭代优化Jailbreak Prompt。
-
-
文本嵌入微调攻击:Ma等人通过计算反义词嵌入的差异来生成对抗性概念嵌入。
-
基于RAG的Jailbreak:PANDORA引入了一种间接攻击LLMs的方法,通过用精心制作的内容毒化外部知识库来实现Jailbreak。
3.6.4 跨模态攻击
跨模态Jailbreaks将攻击从文本、图像和音频模态转移。这些方法利用LVLMs的多模态特性来绕过过滤器并生成有害内容。
-
Text-Image Joint Prompt Optimization Strategy:联合优化文本和视觉Prompt以解决单一模态攻击的限制。
-
Text-Embedded Adversarial Image Generation:FigStep利用LVLMs理解嵌入图像中的文本指令的能力。
-
Fictional Storytelling for Text-to-Voice Jailbreaking:VoiceJailbreak利用虚构故事的原则来“人性化”GPT-4o。
-
Visual-RolePlay:VRP利用LVLM的漏洞通过生成高风险角色描述来诱导恶意输出。
3.6.5 攻击可迁移性
攻击可迁移性是大语言模型和视觉-语言大模型对抗研究中的一个关键问题。研究表明,攻击的可迁移性在不同模型之间可能有限,但在某些情况下仍然存在。
3.6.6 评估策略
评估LLMs和LVLMs需要综合策略。最近的研究提出了新的框架和基准数据集来评估模型的安全性。
3.6.7 安全缓解
确保LLMs和LVLMs的安全性至关重要。研究提出了各种缓解策略,包括防御性训练和模型优化、内容过滤和检测、输入扰动和预测聚合等。
4 挑战与失败模式
4.1 AI核心算法
4.1.1 视觉-语言大模型
视觉-语言推理
LVLMs通过结合视觉和语言处理能力,显著提升了机器人在复杂环境中的感知、理解和交互能力。这些模型在以下方面表现出色:
-
多模态集成:LVLMs能够整合来自视觉和语言的输入,增强了对环境的理解。
-
任务执行:通过高级的多模态推理,LVLMs能够在任务执行中表现出色,如对象识别、导航和交互。
-
实时应用:低延迟的LVLMs适用于动态环境,能够快速响应变化。
技术优势
-
模型多样性:LVLMs如CLIP、BLIP-2和GPT-4 Vision在视觉-语言推理任务中表现出色。
-
模型优化:模型如mPLUG和LLaVA针对动态环境进行了优化,提供了低延迟的响应。
-
伦理和安全性:封闭源模型如Claude 3 Vision和PaLM-E注重安全性和伦理,减少了有害输出。
面临的挑战
-
鲁棒性:尽管LVLMs在任务执行中表现出色,但在动态和复杂环境中仍需提高鲁棒性。
-
噪声处理:模型在处理噪声或不完整数据时仍需改进,以确保在现实世界中的可靠性。
-
泛化能力:模型在处理新环境或输入时表现不佳,可能需要进一步优化以提高泛化能力。
4.1.2 语言大模型
自然语言处理
LLMs在自然语言处理任务中表现出色,广泛应用于机器人系统中的认知和决策过程。以下是LLMs的主要应用和挑战:
-
多任务处理:LLMs能够处理多种自然语言处理任务,如机器翻译、摘要、问答和内容生成。
-
交互能力:在机器人系统中,LLMs作为认知核心,处理多模态输入并生成适当的响应或动作。
面临的挑战
-
物理世界对齐不足:LLMs在处理现实世界的感官数据时存在困难,可能导致生成错误的指令或导航信息。
-
对抗性攻击:模型容易受到对抗性攻击的影响,可能导致生成有害或误导性的输出。
-
偏见和公平性:模型可能继承训练数据中的偏见,导致不公平或有害的结果。
-
鲁棒性和泛化能力:模型在处理新环境或输入时表现不佳,可能导致错误的决策。
-
可解释性:模型的“黑箱”特性使得在安全关键应用中难以进行错误诊断和调试。
-
计算资源需求:模型的高计算需求限制了其在资源受限环境中的应用。
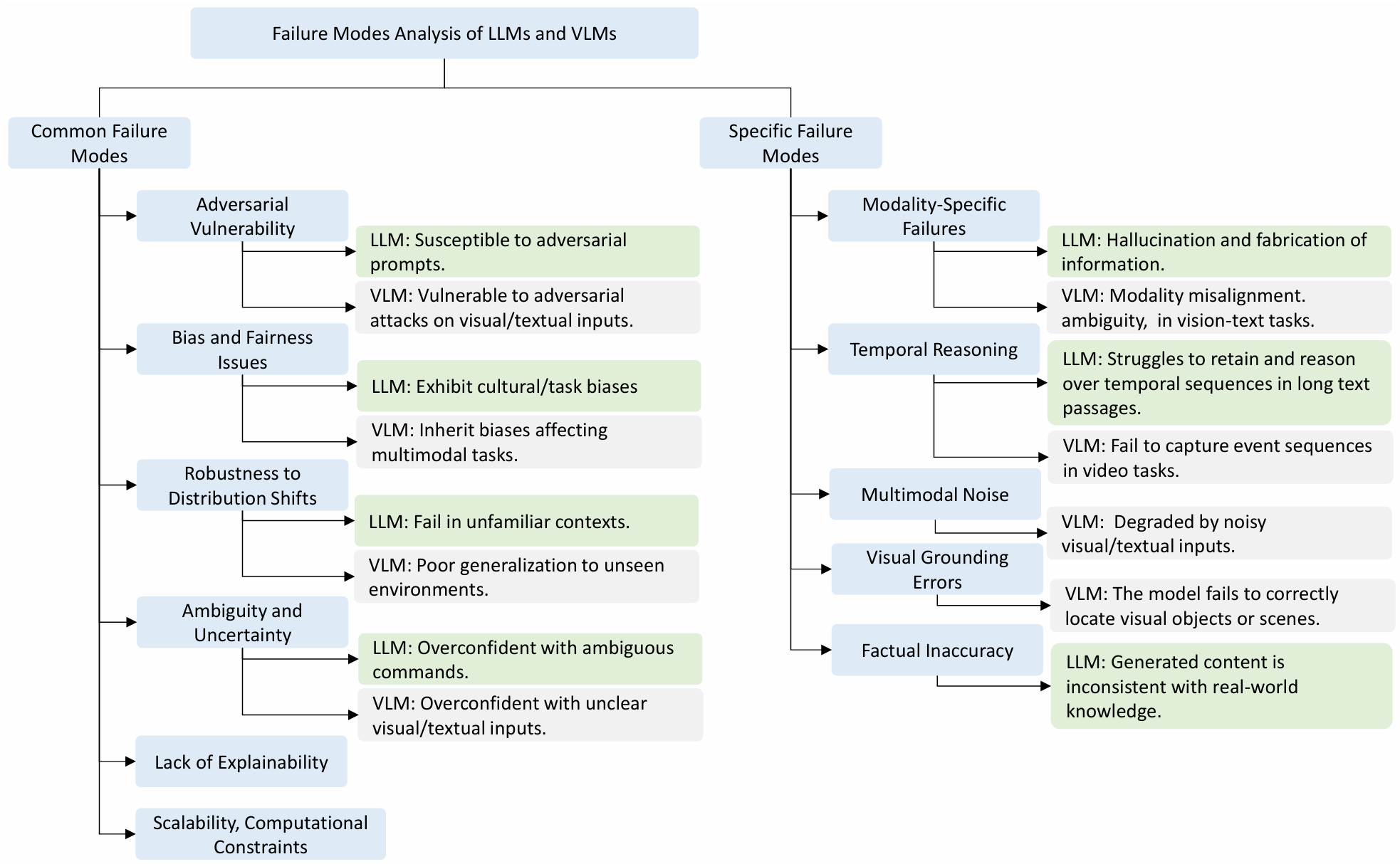
4.2 常见的失败模式
4.2.1 对抗性脆弱性
-
LLMs:LLMs容易受到对抗性攻击的影响,尤其是对抗性Prompt攻击。攻击者可以通过精心设计的输入来诱使模型生成有害、误导或不可靠的输出。
-
LVLMs:LVLMs在视觉和文本领域都面临对抗性威胁。小的、往往不可察觉的输入扰动可能导致模型在对象识别或生成准确描述时出现错误。
4.2.2 偏见和公平性问题
-
LLMs:模型容易继承训练数据中的偏见,这可能导致在人机交互中出现不公平或有害的结果。例如,模型可能在某些任务中对特定群体表现出偏见。
-
LVLMs:模型在训练数据中反映的偏见可能导致在图像描述或多模态推理中出现偏差。这可能影响模型在多样化和敏感环境中的表现。
4.2.3 分布偏移的鲁棒性
-
LLMs:模型在处理与训练数据不同的环境或输入时表现不佳,可能导致错误解释或不良决策。这在处理不熟悉的领域或语言时尤为明显。
-
LVLMs:模型在动态或多样化的现实世界环境中难以有效泛化。输入与训练数据显著偏离时,模型可能无法正确执行任务。
4.2.4 不确定性和模糊性
-
LLMs:模型在处理模糊或不确定的输入时表现不佳,可能导致过度自信的输出。这在高风险的场景中可能带来安全隐患。
-
LVLMs:模型在处理不完整或模糊的输入时,可能产生高置信度的预测,即使视觉或文本数据缺乏清晰度或上下文。
4.2.5 缺乏可解释性
-
LLMs:模型被视为“黑箱”,难以追踪或理解其输出背后的推理过程。这在安全关键应用中增加了错误诊断和调试的难度。
-
LVLMs:模型在决策过程中缺乏透明度,难以解释其预测或识别失败的根本原因。
4.2.6 可扩展性和计算约束
-
LLMs:模型需要大量的计算资源,可能导致在实时或资源受限的环境中表现不佳。
-
LVLMs:由于其大规模架构,模型在设备计算能力有限或需要实时响应的系统中难以部署。
4.3 特定算法的失败模式
4.3.1 特定模态失败
LLMs的特定模态失败
-
物理世界对齐不足:LLMs在处理现实世界的感官数据时存在困难。由于缺乏与物理世界的直接交互,模型可能生成与实际情况不符的指令或信息,导致机器人执行错误的操作。
-
偏见传播:模型可能继承训练数据中的偏见,导致在处理特定任务时产生歧视性或不符合伦理的决策。
-
生成误导性信息:LLMs可能生成虚假或误导性的信息,特别是在处理复杂或模糊的任务时。
-
隐私泄露:模型可能无意中记忆和再现敏感信息,导致用户数据或操作保密性的泄露。
-
心理操纵:对抗性输入可能利用系统的漏洞或欺骗用户,导致不恰当的交互。
LVLMs的特定模态失败
-
模态不对齐:LVLMs在处理视觉和语言数据时,可能出现模态不对齐的问题。模型可能错误地将视觉特征与文本描述关联起来,导致在零样本图像分类等任务中出现错误。
-
视觉对齐失败:模型在链接语言到具体视觉区域时遇到困难,如在对象检测或指代表达理解任务中识别相关对象失败。
4.3.2 时间推理
-
LVLMs的时间推理挑战:在处理视频或动态场景时,LVLMs可能难以理解事件顺序和长期依赖关系。这可能导致在烹饪视频等任务中无法正确链接早期动作到后期步骤,从而产生错误的解释。
-
LLMs的时间推理:虽然LLMs可以处理序列数据(如文本),但它们在视觉上下文中处理时间推理时通常不如专门的视觉模型。
4.3.3 对抗性多模态噪声
-
LVLMs的噪声处理:在现实世界环境中,噪声或不完整的视觉和语言输入可能严重影响LVLMs的性能。模型可能对细微的视觉输入变化非常敏感,导致分类错误或生成错误输出。
-
LLMs的噪声处理:LLMs在处理噪声的文本输入时也会遇到挑战,但通常不像LVLMs那样在视觉数据中面临同样的问题。
5 数据集分类
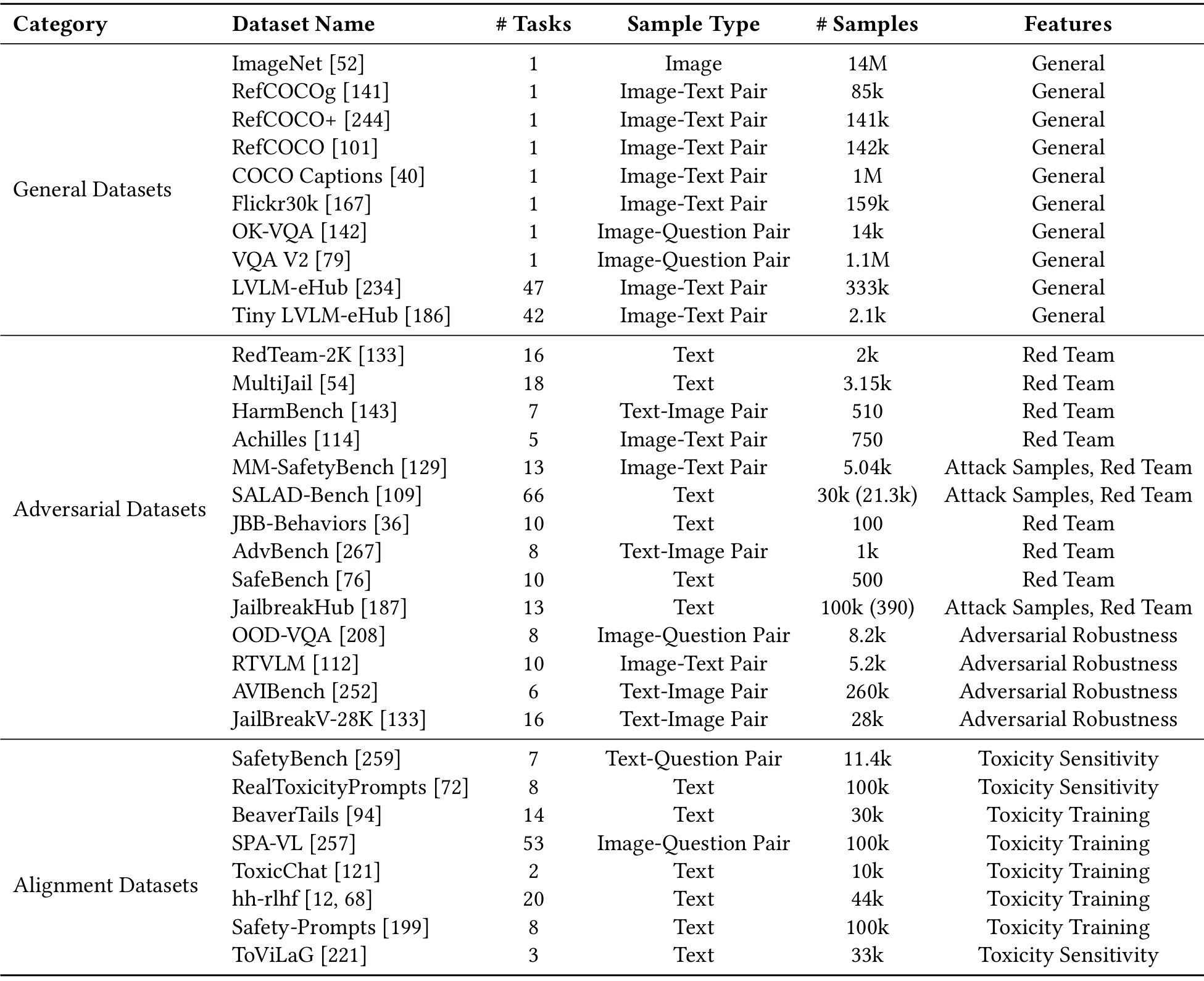
-
通用数据集:
-
这类数据集主要用于评估模型的核心多模态能力,如图像分类、字幕生成、视觉问答(VQA)等。
-
目标是测试模型在视觉理解、推理和语言生成方面的能力。
-
常见的基准数据集包括ImageNet、COCO Captions、RefCOCO和VQA V2。
-
这些数据集也可以通过引入细微扰动来模拟认知偏差,用于鲁棒性测试。
-
-
对抗性数据集:对抗性数据集专门用于对模型进行压力测试,分为两类:
-
Red Team数据集:这些数据集针对明显的有害内容,如暴力、色情或其他违反政策的内容。它们用于评估模型对恶意查询的鲁棒性,确保伦理合规,并模拟越狱场景。例如,RedTeam-2K、MultiJail和SALAD-Bench。
-
鲁棒性评估数据集:这些数据集评估模型对对抗性攻击、模糊查询和边缘情况的鲁棒性。它们通过暴露处理细微或对抗性输入时的脆弱性来进行测试。子类别包括对抗性攻击样本和对有害或误解输入的敏感性测试。例如,AVIBench和RoCOCO。
-
-
对齐数据集:
-
对齐数据集对于微调LVLMs至关重要,确保它们在有用性和无害性之间取得平衡。
-
常用于强化学习从人类反馈(RLHF)管道或偏好模型训练中。
-
这些数据集对齐模型与伦理标准,减少有害输出,同时保持实用性。例如,SafetyBench和Toxicity Sensitivity数据集。
-
总结
-
论文全面概述了具身AI系统面临的漏洞和攻击向量,特别是集成LVLMs和LLMs所面临的独特挑战。
-
通过将漏洞分类为外生漏洞、内生漏洞和跨维度漏洞,系统分析了对抗性攻击范式,研究了针对LLMs和LVLMs的攻击向量,评估了感知、决策和任务规划中算法的鲁棒性挑战,并提出了增强具身AI系统安全和可靠性的针对性策略。
-
该论文提供了一个综合框架,用于理解具身AI系统中漏洞与安全性之间的相互作用。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









