









本篇为迁移学习系列第九篇论文,清华大学助理教授Mingsheng Long (龙明盛)发表在国际机器学习顶级会议Neural2018上提出的新的Domain Adaptation的条件对抗网络。
Abstract
对抗性学习已被嵌入到深层网络中,用于学习解纠缠和可转移的领域适应表示。在分类问题中,现有的对抗性域自适应方法可能无法有效地对齐多模态分布的不同域。在本文中,我们提出了一个条件对抗性域适应的原则框架,该框架对分类器预测中所传递的判别信息建立了对抗性适应模型。条件域对抗性网络(CDANs)采用了两种新的条件调节策略:多线性条件调节和熵条件调节。前者通过捕获特征表示与分类器预测之间的交叉方差来提高分类器的识别率,后者通过控制分类器预测的不确定性来保证分类器的可移植性。有了理论保证和几行代码,这种方法在5个数据集上已经超过了最先进的结果。
1 Introduction
深度网络大大改善了各种机器学习问题和应用的现状。当对大规模数据集进行训练时,深度网络学习表示,这些表示通常在各种任务中都有用[36,11,54]。然而,深度网络在将学到的知识泛化到新的数据集或环境方面可能很弱。即使是训练域的细微变化也会导致深层网络对目标域做出虚假的预测[54,36]。虽然在许多实际应用中,需要将一个深度网络从有足够训练数据的源域传输到只有未标记数据可用的目标域,但是这种传输学习范式受到跨域[39]的数据分布变化的阻碍。
学习一个减少训练和测试分布之间数据集转移的模型被称为领域适应[38]。以往的浅层域自适应方法要么通过学习不变特征表示来架起源和目标之间的桥梁,要么通过标记源数据和未标记目标数据估计实例重要性[24,37,15]。深度域自适应方法的最新进展是利用深度网络,通过在深度架构中嵌入自适应模块来学习可转移的表示,同时分离数据背后变化的解释因素和跨域的匹配特征分布[12,13,29,52,31,30,51]。
对抗性领域适应[12,52,51]将对抗性学习和领域适应集成到一个双人博弈中,类似于生成对抗性网络(GANs)[17]。通过最小化区分源域和目标域的分类误差来学习领域鉴别器,而深度分类模型学习领域鉴别器无法区分的可转移表示。与这些特征级方法相同,生成像素级自适应模型在原始像素空间中执行分布对齐,使用图像到图像的翻译技术将源数据转换为目标域的样式[56,28,22,43]。另一组作品使用不同的领域鉴别器分别对齐特性和类的分布[23,8,50]。
尽管这些对抗性领域自适应方法在分类[12,51,28]到分割[43,50,22]等各种任务中普遍有效,但它们仍然可能受到两个瓶颈的制约。首先,当数据分布包含复杂的多模态结构时,对抗性自适应方法可能无法捕捉到这样的多模态结构,从而在没有模式不匹配的情况下实现分布的判别对齐。这样的风险来自于对抗式学习的均衡挑战,因为即使判别器完全混淆,我们也不能保证两个分布完全相似。注意,这种风险不能通过像[23,8,50]那样通过单独的域鉴别器将特征和类的分布对齐来解决,因为多模态结构只能通过特征和类之间的交叉协方差依赖性来充分捕获[47,44]。其次,当区域鉴别器的识别信息是不确定的时,对其进行条件设置是有风险的。
在本文中,我们通过形式化一个有条件的对抗性领域适应框架来解决上述两个挑战。条件生成对抗网络(CGANs)的最新研究进展[34,35]揭示了通过使生成器和鉴别器对鉴别信息进行调节,可以使真实图像和生成图像的分布变得相似。基于条件作用的观点,本文提出了条件域对抗性网络(CDANs),利用分类器预测中所传递的判别信息来辅助对抗性适应。CDAN模型的关键是一种基于领域特定特征表示和分类器预测的交叉方差的条件域鉴别器。我们进一步将区域判别器设定为分类器预测的不确定性条件,并将判别器的优先级设置为易于转移的例子。整个系统可以通过反向传播在线性时间内求解。基于领域自适应理论[4],给出了泛化误差界的理论保证。实验表明,我们的模型在五个基准数据集上超过了最先进的结果。
2 Related Work
域适应[38,39]通过匹配边缘分布[49,37,15]或条件分布[55,10],将学习者概括为跨不同分布域的学习者。它在计算机视觉[42,18,16,21]和自然语言处理[9,14]中有着广泛的应用。除了上述的浅层架构外,最近的研究表明,深层网络学习到更多的可转移表示,能够解开数据[6]背后的变异解释因素,并显示出不同种群背后的不变因素[14,36]。由于深度表示只能减少而不能消除跨域分布差异[54],最近关于深度域适应的研究进一步将适应模块嵌入到深度网络中,使用了两种主要的分布匹配技术:矩匹配[29,31,30]和对抗性训练[12,52,13,51]。
由生成竞争网络(GANs)[17]提出的对抗性学习方法已成功地应用于生成建模。GANs在一个双人游戏中构成两个网络:一个捕获数据分布的生成器和一个区分生成的样本和真实数据的鉴别器。这些网络在极大极小范式下训练,这样,当鉴别器努力不被愚弄时,生成器就学会了欺骗鉴别器。GANs的一些困难已经得到了解决,例如改进的训练[2,1]和模式崩溃[34,7,35],但其他困难仍然存在,例如无法匹配两个分布[3]。对于领域适应的对抗性学习,无条件学习得到了充分利用,而条件学习仍处于探索阶段。
共享条件GANs[3]的一些精神,另一行作品使用独立的域鉴别器匹配特性和类。Hoffman等人的[23]通过学习特征来欺骗域鉴别器来实现全局域对齐,通过最小化约束的多实例丢失来实现特定于类别的适应。特别是用于特征表示的对抗性模块不依赖于具有类信息的类适应模块。Chen等。[8]在分类器层上执行类对齐;即。多域判别器只以源分类器的软最大概率作为输入,而不以类信息为条件。Tsai等人的[50]在特征层和类层上强加了两个独立的域鉴别器。这些方法没有在统一的条件域鉴别器中研究特性和类之间的依赖关系,这对于捕获底层数据分布的多模态结构非常重要。
本文通过定义基于特征的领域鉴别器,并将条件对抗机制扩展到基于类信息的领域鉴别器,从而实现了领域的鉴别和可转移自适应。在控制分类器预测的不确定性的同时,设计了两种新的条件策略来捕获特征表示与类预测之间的交叉协方差依赖关系。这与单独对齐特性和类不同[23,8,50]。
3 Conditional Adversarial Domain Adaptation
在无监督域自适应中,给出了一个源域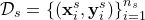 ,有
,有 个被标签的样例,目标域
个被标签的样例,目标域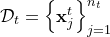 ,有
,有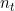 个没有被标签的样例。从联合分布
个没有被标签的样例。从联合分布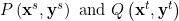 中分别抽取源域和目标域,假设
中分别抽取源域和目标域,假设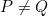 。本文的目标是设计一个深度网络
。本文的目标是设计一个深度网络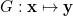 ,这在形式上减少了跨域数据分布的转移,从而降低了目标风险
,这在形式上减少了跨域数据分布的转移,从而降低了目标风险![\epsilon_{t}(G)=\mathbb{E}_{\left(\mathbf{x}^{t}, \mathbf{y}^{t}\right) \sim Q}\left[G\left(\mathbf{x}^{t}\right) \neq \mathbf{y}^{t}\right]](https://i-blog.csdnimg.cn/blog_migrate/60998d8426d1b150cb3729f6175b0063.gif) 可以被源风险
可以被源风险![\epsilon_{s}(G)=\mathbb{E}_{\left(\mathbf{x}^{s}, \mathbf{y}^{s}\right) \sim P}\left[G\left(\mathbf{x}^{s}\right) \neq \mathbf{y}^{s}\right]](https://i-blog.csdnimg.cn/blog_migrate/36abb5a818705468d8be5a85e09326d9.gif) 所限制,加上分布差异
所限制,加上分布差异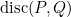 用一种新的条件域判别器进行量化。
用一种新的条件域判别器进行量化。
对抗性学习是生成对抗性网络(GANs)[17]的关键思想,已经成功地探索到如何将跨域差异最小化[13,51]。用f = f (x)表示特征表示,用g = G (x)表示深度网络G。域对抗神经网络(DANN)[13]生成的分类器预测。第一个是域判别器D训练区分源域和目标域和第二个是F训练同时混淆特性表示域判别器D域鉴别器对应的误差函数之间的差异特性分布P (F)和Q(F)[12],在领域适应理论[4]限制目标风险是关键。
3.1 Conditional Discriminator
我们进一步从两个方向改进了现有的对抗性域适应方法[12,52,51]。首先,当特征与类的联合分布,即,跨域不相同,仅适应特征表示f可能不够。由于定量研究[54],表示最终过渡深大网络,从一般到具体的可转移性明显降低特定于域的特征层f和分类器层g。第二,多通道特性分布时,这是一个真实的场景由于多层次的性质分类,只适应对抗的网络特性,表示可能是一个挑战。最近的研究[17,2,7,1]揭示了仅将不同分布下的部分组件与对抗性网络匹配失败的高风险。即使鉴别器完全混淆,我们也不能从理论上保证两个不同的分布是相同的[3]。
本文通过形式化一个条件对抗性领域适应框架来解决上述两个问题。条件生成对抗网络(CGANs)[34]的最新进展发现,通过对生成器和鉴别器设置相关信息(如关联标签和关联模式)的条件,可以更好地匹配不同的分布。条件GANs[25, 35]从具有高可变性和多模态分布的数据集中生成全局一致的图像。在条件GANs的激励下,我们观察到分类器预测g在逆向域自适应中传递的判别信息潜在地揭示了多模态结构,该多模态结构在自适应特征表示f时可以作为条件。通过条件作用,可以同时对特征表示f和分类器预测g的域方差进行建模。
将条件域对抗性网络(CDAN)定义为具有两个竞争误差项的极小极大优化问题:(a) E(G)在源分类器G上,为保证较低的源风险而最小化;(b) E (D;G)源分类器G和域鉴别器D跨源域和目标域,在D上最小化,在f = f (x)和G = G(x)上最大化。
![\begin{array}{c}{\mathcal{E}(G)=\mathbb{E}_{\left(\mathbf{x}_{i}^{s}, \mathbf{y}_{i}^{s}\right) \sim \mathcal{D}_{s}} L\left(G\left(\mathbf{x}_{i}^{s}\right), \mathbf{y}_{i}^{s}\right)} \\ {\mathcal{E}(D, G)=-\mathbb{E}_{\mathbf{x}_{i}^{s} \sim \mathcal{D}_{s}} \log \left[D\left(\mathbf{f}_{i}^{s}, \mathbf{g}_{i}^{s}\right)\right]-\mathbb{E}_{\mathbf{x}_{j}^{t} \sim \mathcal{D}_{t}} \log \left[1-D\left(\mathbf{f}_{j}^{t}, \mathbf{g}_{j}^{t}\right)\right]}\end{array}](https://i-blog.csdnimg.cn/blog_migrate/3cc46f071a4b416c3516c958077b4485.gif)
在L (·;·)为交叉熵损失,h = (f;g)为特征表示f与分类器预测g的联合变量,条件域对抗网络(CDAN)的极小极大对策为
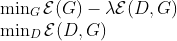
λ是hyper-parameter两个目标之间的权衡风险和来源域的对手。
通过联合变量h = (f,g),这个条件域鉴别器可以潜在地解决对抗领域适应前面提到的两个挑战。D的一个简单条件是D(f g),我们将向量f g中的特征表示和分类器预测连接起来,并将其提供给条件域判别器D。这种条件条件策略被现有的条件GANs广泛采用[34,25,35]。然而,在串联策略下,f和g是相互独立的,因此不能完全捕捉到特征表示和分类器预测之间的乘法交互,而这对于域自适应是至关重要的。因此,分类器预测中所传递的多模态信息不能完全用于匹配复杂域[47]的多模态分布。
3.3 Conditional Domain Adversarial Network
我们使条件对抗的领域适应f在特定领域的特征表示和分类器预测g。我们共同减少(1)w.r.t.来源分类器g和f特征提取器,减少(2)w.r.t.域鉴别器D, f和最大化(2)w.r.t.特征提取器和源分类器g .这个收益率条件的极大极小问题域对抗网络(CDAN)
![\begin{array}{l}{\min _{G} \mathbb{E}_{\left(\mathbf{x}_{i}^{s}, y_{i}^{s}\right) \sim \mathcal{D}_{s}} L\left(G\left(\mathbf{x}_{i}^{s}\right), \mathbf{y}_{i}^{s}\right)} \\ {\quad+\lambda\left(\mathbb{E}_{\mathbf{x}_{i}^{s} \sim \mathcal{D}_{s}} \log \left[D\left(T\left(\mathbf{h}_{i}^{s}\right)\right)\right]+\mathbb{E}_{\mathbf{x}_{j}^{t} \sim \mathcal{D}_{t}} \log \left[1-D\left(T\left(\mathbf{h}_{j}^{t}\right)\right)\right]\right)} \\ {\max _{D} \mathbb{E}_{\mathbf{x}_{i}^{s} \sim \mathcal{D}_{s}} \log \left[D\left(T\left(\mathbf{h}_{i}^{s}\right)\right)\right]+\mathbb{E}_{\mathbf{x}_{j}^{t} \sim \mathcal{D}_{t}} \log \left[1-D\left(T\left(\mathbf{h}_{j}^{t}\right)\right)\right]}\end{array}](https://i-blog.csdnimg.cn/blog_migrate/01f8547d26bf6c45460d068114c01d0c.gif)
λ是hyper-parameter源标识符和条件域之间的鉴别器,和注意,h = (f;g)为领域特定特征表示f与分类器预测g的联合变量,用于对抗性适应。根据经验,我们可以安全地将f设置为最后一个特征层表示,将g设置为分类器层预测。在底层特征不可转移的情况下,如像素级的自适应任务[25,22],我们可以将f转换为底层表示。

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









