







全文翻译如下:
Abstract
对抗学习已被嵌入到深度网络中,用于学习用于域适应的解纠缠和可迁移表示。现有的对抗域适应方法可能无法有效地对分类问题中固有的多模态分布的不同域进行对齐。在本文中,我们提出了条件对抗域适应,这是一个原则性的框架,它将对抗适应模型的条件限制在分类器预测中传递的判别信息上。条件域对抗网络( Conditional Domain Adversarial Networks,CDANs )设计了两种新颖的条件化策略:多线性条件化捕获特征表示与分类器预测之间的互协方差以提高判别性,熵条件化控制分类器预测的不确定性以保证可迁移性。在理论保证和几行代码的情况下,该方法在五个数据集上超过了最先进的结果。
Introduction
深度网络显著提升了不同机器学习问题和应用的研究水平。当在大规模数据集上进行训练时,深度网络学习在各种任务[ 36、11、54]中通用有用的表示。然而,深度网络在将学习到的知识泛化到新的数据集或环境中的能力较弱。即使来自训练域的细微变化也会导致深度网络在目标域[ 54、36]上做出虚假预测。然而在许多实际应用中,需要将一个深度网络从一个有足够训练数据的源域迁移到一个只有未标记数据可用的目标域,这种迁移学习范式会受到数据分布跨域转移的阻碍[ 39 ]。
学习一个能够减少数据集在训练和测试分布之间转换的模型称为领域适应[ 38 ]。以往的浅层域适应方法要么通过学习不变特征表示来桥接源域和目标域,要么利用有标签的源域数据和无标签的目标域数据[ 24、37、15]来估计实例重要性。深度域自适应方法的最新进展通过在深度架构中嵌入自适应模块,利用深度网络学习可迁移的表示,同时消除数据背后变化的解释因素并匹配跨域[ 12、13、29、52、31、30、51]的特征分布。
对抗域适应[ 12、52、51]类似于生成对抗网络( Generative Adversarial Networks,GANs ) [ 17 ],将对抗学习和域适应集成在一个两人博弈中。领域判别器通过最小化区分源域和目标域的分类误差来学习,而深度分类模型则学习领域判别器无法区分的可迁移表示。与这些特征级方法相比,生成式像素级自适应模型在原始像素空间中执行分布对齐,通过使用Image to Image翻译技术[ 56、28、22、43]将源数据转换为目标域的样式。另一行工作使用不同的领域判别器[ 23、8、50]分别对齐特征和类的分布。
尽管这些对抗域自适应方法对从分类[ 12、51、28]到分割[ 43、50、22]的各种任务都有普遍的效果,但这些对抗域自适应方法仍然可能受到两个瓶颈的制约。首先,当数据分布包含复杂的多模态结构时,对抗自适应方法可能无法捕获这样的多模态结构,从而在不发生模态失配的情况下对分布进行判别性对齐。这种风险来自对抗学习的均衡挑战,即即使判别器完全混淆,也不能保证两个分布足够相似[ 3 ]。值得注意的是,这种风险无法通过将特征和类的分布通过单独的域判别器[ 23、8、50]对齐来解决,因为多模态结构只能通过特征和类[ 47、44]之间的互协方差依赖来充分捕获。其次,在不确定的情况下,将域判别器限定在判别信息上是有风险的。
在本文中,我们通过形式化一个条件对抗域适应框架来解决上述两个挑战。条件生成对抗网络( Conditional Generative Adversarial Networks,CGANs ) [ 34、35]的最新进展表明,通过将生成器和判别器对判别信息进行条件化,可以使真实图像和生成图像的分布相似。受条件洞察力的启发,本文提出了条件域对抗网络( Conditional Domain Adversarial Networks,CDANs )来利用分类器预测中传递的判别信息来辅助对抗适应。CDAN模型的关键是基于特定领域特征表示和分类器预测的互协方差的条件域判别器。我们进一步将领域判别器限定在分类器预测的不确定性上,优先考虑易于迁移的样本。整个系统可以通过反向传播在线性时间内求解。基于域适应理论[ 4 ],我们给出了泛化误差界的理论保证。实验表明,我们的模型在五个基准数据集上超过了最新的结果。
2 Related Work
领域自适应[ 38、39]通过匹配边缘分布[ 49、37、15]或条件分布[ 55、10],将学习者泛化到不同分布的不同领域。在计算机视觉[ 42、18、16、21]和自然语言处理[ 9、14]中有广泛的应用。除了上述浅层架构外,最近的研究表明,深层网络学习到更多的可迁移表示,这些表示可以解开数据背后变异的解释因素[ 6 ],并显示不同种群[ 14、36]背后的不变因素。由于深度表示只能减少而不能消除跨域分布差异[ 54 ],最近的深度域自适应研究进一步在深度网络中嵌入自适应模块,使用两种主要的技术进行分布匹配:矩匹配[ 29、31、30]和对抗训练[ 12、52、13、51]。
由生成式对抗网络( Generative Adversarial Networks,GANs ) [ 17 ]首创的对抗学习已成功用于生成式建模。GANs在一个两人博弈中构成两个网络:捕获数据分布的生成器和区分生成样本和真实数据的判别器。网络以minimax范式进行训练,使生成器学习欺骗判别器,而判别器努力不被欺骗。GANs的一些困难已经被解决,如改进的训练[ 2 , 1]和模式崩溃[ 34,7,35],但其他困难仍然存在,如两个分布匹配失败[ 3 ]。在面向领域适应的对抗学习中,无条件的对抗学习已经被利用,而有条件的对抗学习仍处于探索阶段。
另一类工作分享了条件GAN的一些精神[ 3 ],使用单独的域判别器来匹配特征和类。Hoffman等[ 23 ]通过学习特征进行全局领域对齐来欺骗领域判别器,通过最小化一个受约束的多示例损失进行特定类别的自适应。特别地,特征表示的对抗模块不受带有类别信息的类适应模块的限制。Chen等[ 8 ]在分类器层上进行类对齐;即多个域判别器仅将源分类器的softmax概率作为输入,而不是以类别信息为条件。Tsai等[ 50 ]在特征层和类层上施加两个独立的领域判别器。这些方法没有在一个统一的条件域判别器中探索特征和类之间的依赖关系,这对于捕获数据分布背后的多模态结构非常重要。
本文扩展了条件对抗机制,通过在特征上定义域判别器,同时在类信息上对其进行条件化,从而实现具有判别性和可迁移的域适应。设计了两种新颖的条件化策略,在控制分类器预测不确定性的同时,捕获特征表示与类别预测之间的互协方差依赖关系。这不同于将特征和类分别对齐[ 23、8、50]。
3 Conditional Adversarial Domain Adaptation
在无监督域适应中,给定
n
s
n_s
ns个有标签样本的源域
D
s
=
{
(
x
i
s
,
y
i
s
)
}
i
=
1
n
s
\mathcal{D}_s=\left\{\left(\mathbf{x}_i^s, \mathbf{y}_i^s\right)\right\}_{i=1}^{n_s}
Ds={(xis,yis)}i=1ns 和
n
t
n_t
nt个无标签样本的目标域
D
t
=
{
x
j
t
}
j
=
1
n
t
\mathcal{D}_t=\left\{\mathrm{x}_j^t\right\}_{j=1}^{n_t}
Dt={xjt}j=1nt。源域和目标域分别从联合分布
P
(
x
s
,
y
s
)
P\left(\mathrm{x}^s, \mathbf{y}^s\right)
P(xs,ys)和
Q
(
x
t
,
y
t
)
Q\left(\mathbf{x}^t, \mathbf{y}^t\right)
Q(xt,yt)中采样,违反i . i . d .假设为
P
≠
Q
P \neq Q
P=Q。本文的目标是设计一个深度网络
G
:
x
↦
y
G: \mathrm{x} \mapsto \mathrm{y}
G:x↦y,形式化地减少数据分布在域间的偏移,使得目标风险
ϵ
t
(
G
)
=
\epsilon_t(G)=
ϵt(G)=
E
(
x
t
,
y
t
)
∼
Q
[
G
(
x
t
)
≠
y
t
]
\mathbb{E}_{\left(\mathbf{x}^t, \mathbf{y}^t\right) \sim Q}\left[G\left(\mathbf{x}^t\right) \neq \mathbf{y}^t\right]
E(xt,yt)∼Q[G(xt)=yt]可以被源风险
ϵ
s
(
G
)
=
E
(
x
s
,
y
s
)
∼
P
[
G
(
x
s
)
≠
y
s
]
\epsilon_s(G)=\mathbb{E}_{\left(\mathbf{x}^s, \mathbf{y}^s\right) \sim P}\left[G\left(\mathbf{x}^s\right) \neq \mathbf{y}^s\right]
ϵs(G)=E(xs,ys)∼P[G(xs)=ys] 加上一个新颖的条件域判别器量化的分布差异
disc
(
P
,
Q
)
\operatorname{disc}(P, Q)
disc(P,Q)所约束。
对抗学习作为生成对抗网络( Generative Adversarial Networks,GANs ) [ 17 ]的核心思想,已被成功探索用于最小化跨域差异[ 13、51]。用
f
=
F
(
x
)
\mathrm{f}=F(\mathrm{x})
f=F(x)表示特征表示,用
g
=
G
(
x
)
\mathrm{g}=G(\mathrm{x})
g=G(x) 表示由深度网络
G
G
G生成的分类器预测。领域对抗神经网络( Domain Adversarial Neural Network,DANN ) [ 13 ]是一个两人博弈:第一个玩家是训练好的领域判别器
D
D
D,用于区分源域和目标域;第二个玩家是同时训练好的特征表示
F
F
F,用于混淆领域判别器
D
D
D。领域判别器的误差函数很好地对应了领域适应理论中约束目标风险的特征分布
P
(
f
)
P(\mathbf{f})
P(f)和
Q
(
f
)
Q(\mathbf{f})
Q(f)之间的差异[ 12 ]。
3.1 Conditional Discriminator
我们从两个方向进一步改进现有的对抗域适应方法[ 12、52、51]。首先,当特征和类的联合分布,即
P
(
x
s
,
y
s
)
P\left(\mathbf{x}^s, \mathbf{y}^s\right)
P(xs,ys) and
Q
(
x
t
,
y
t
)
Q\left(\mathbf{x}^t, \mathbf{y}^t\right)
Q(xt,yt)是跨域不一致的,仅适应特征表示
f
\mathrm{f}
f可能是不够的。由于定量研究[ 54 ],深度表示最终沿着深度网络从一般到特定过渡,在领域特定的特征层
f
\mathrm{f}
f和分类器层
g
\mathrm{g}
g中,可迁移性显著下降。其次,当特征分布为多模态时,由于多类分类的性质,这是一个真实的场景,仅采用特征表示可能对对抗网络具有挑战性。最近的工作[ 17 , 2 , 7 , 1]揭示了仅将不同分布下的部分组件与对抗网络匹配失败的高风险。即使完全混淆了判别器,我们也没有理论保证两个不同的分布是相同的[ 3 ]。
本文通过形式化一个条件对抗域适应框架来解决上述两个挑战。条件生成对抗网络( Conditional Generative Adversarial Networks,CGANs ) [ 34 ]的最新进展发现,通过将生成器和判别器对相关信息(如关联标签和附属模态)进行条件化,可以更好地匹配不同的分布。条件GANs [ 25、35]从具有高变异性和多模态分布的数据集中生成全局一致的图像。受条件生成对抗网络的启发,我们观察到在对抗域适应中,分类器预测
g
\mathrm{g}
g传递了潜在揭示多模态结构的判别信息,在适应特征表示
f
\mathrm{f}
f时可以对其进行条件化。通过条件化,特征表示
f
\mathrm{f}
f和分类器预测
g
\mathrm{g}
g中的域方差可以同时建模。
我们将条件域对抗网络( Conditional Domain Adversarial Network,CDAN )建模为一个具有两个竞争性误差项的极小极大优化问题:( a )源分类器
G
G
G上的
E
(
G
)
\mathcal{E}(G)
E(G),最小化该误差项以保证较低的源风险;( b )
E
(
D
,
G
)
\mathcal{E}(D, G)
E(D,G)在源分类器
G
G
G和域判别器
D
D
D 上跨源域和目标域,在
D
D
D上最小化,在
f
=
F
(
x
)
\mathrm{f}=F(\mathrm{x})
f=F(x)和
g
=
G
(
x
)
\mathrm{g}=G(\mathrm{x})
g=G(x)上最大化:
E
(
G
)
=
E
(
x
i
s
,
y
i
s
)
∼
D
s
L
(
G
(
x
i
s
)
,
y
i
s
)
,
E
(
D
,
G
)
=
−
E
x
i
s
∼
D
s
log
[
D
(
f
i
s
,
g
i
s
)
]
−
E
x
j
t
∼
D
t
log
[
1
−
D
(
f
j
t
,
g
j
t
)
]
\begin{gathered} \mathcal{E}(G)=\mathbb{E}_{\left(\mathbf{x}_i^s, \mathbf{y}_i^s\right) \sim \mathcal{D}_s} L\left(G\left(\mathbf{x}_i^s\right), \mathbf{y}_i^s\right), \\ \mathcal{E}(D, G)=-\mathbb{E}_{\mathbf{x}_i^s \sim \mathcal{D}_s} \log \left[D\left(\mathbf{f}_i^s, \mathbf{g}_i^s\right)\right]-\mathbb{E}_{\mathbf{x}_j^t \sim \mathcal{D}_t} \log \left[1-D\left(\mathbf{f}_j^t, \mathbf{g}_j^t\right)\right] \end{gathered}
E(G)=E(xis,yis)∼DsL(G(xis),yis),E(D,G)=−Exis∼Dslog[D(fis,gis)]−Exjt∼Dtlog[1−D(fjt,gjt)]
其中
L
(
⋅
,
⋅
)
L(\cdot, \cdot)
L(⋅,⋅) 为交叉熵损失,
h
=
(
f
,
g
)
\mathbf{h}=(\mathbf{f}, \mathbf{g})
h=(f,g)为特征表示
f
\mathbf{f}
f和分类器预测
g
g
g的联合变量。条件域对抗网络( CDAN )的极小极大博弈是
min
G
E
(
G
)
−
λ
E
(
D
,
G
)
min
D
E
(
D
,
G
)
\begin{aligned} & \min _G \mathcal{E}(G)-\lambda \mathcal{E}(D, G) \\ & \min _D \mathcal{E}(D, G) \end{aligned}
GminE(G)−λE(D,G)DminE(D,G)
其中
λ
\lambda
λ是两个目标之间的超参数,用于权衡源风险和域敌手。通过联合变量
h
=
(
f
,
g
)
\mathbf{h}=(\mathrm{f}, \mathrm{g})
h=(f,g),将域判别器
D
D
D限定在分类器预测
g
\mathrm{g}
g上。这种条件域判别器可以潜在地解决上述两个对抗域适应的挑战。
D
D
D的一个简单的条件化是
D
(
f
⊕
g
)
D(\mathbf{f} \oplus \mathbf{g})
D(f⊕g),将向量
f
⊕
g
\mathbf{f} \oplus \mathbf{g}
f⊕g中的特征表示和分类器预测串联,并反馈给条件域判别器
D
D
D。然而,在级联策略下,f和
g
\mathrm{g}
g是相互独立的,因此无法完全捕获特征表示和分类器预测之间的乘法交互,而这些交互对域适应至关重要。因此,无法充分利用分类器预测中传递的多模态信息来匹配复杂域的多模态分布[ 47 ]。
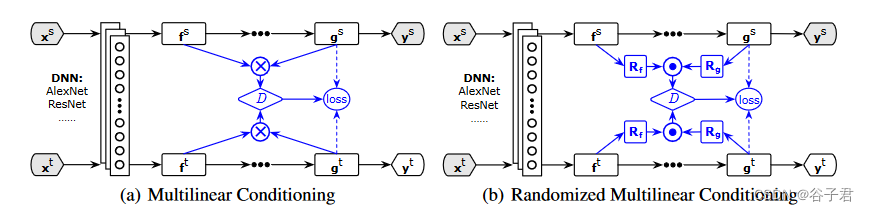
图1:面向领域自适应的条件域对抗网络( Conditional Domain Adversarial Networks,CDAN )体系结构,其中域特定的特征表示 f \mathrm{f} f和分类器预测 g \mathrm{g} g体现了由条件域判别器 D D D联合减少的跨域间隙。( a )多重线性的( M ) Conditioning,适用于低维场景,其中 D D D通过多重线性的映射 f ⊗ g \mathrm{f} \otimes \mathrm{g} f⊗g限制在分类器预测 g \mathrm{g} g上;( b )随机多重线性的( RM )条件化,适用于更高维的场景,其中 D D D 通过随机多重线性的映射 1 d ( R f f ) ⊙ ( R g g ) \frac{1}{\sqrt{d}}\left(\mathbf{R}_{\mathbf{f}} \mathbf{f}\right) \odot\left(\mathbf{R}_{\mathbf{g}} \mathbf{g}\right) d1(Rff)⊙(Rgg)对分类器预测 g \mathbf{g} g进行条件化。熵条件化(虚线)导致CDAN + E将 D D D优先放在易于迁移的例子上。
3.2 Multilinear Conditioning
多线性映射定义为多个随机向量的外积。无限维非线性特征映射的多线性映射已成功应用于将联合分布或条件分布嵌入到再生核希尔伯特空间[ 47、44、45、30]中。给定两个随机向量
x
\mathrm{x}
x和
y
\mathrm{y}
y,联合分布
P
(
x
,
y
)
P(\mathrm{x}, \mathrm{y})
P(x,y) 可以用互协方差
E
x
y
[
ϕ
(
x
)
⊗
ϕ
(
y
)
]
\mathbb{E}_{\mathbf{x y}}[\phi(\mathbf{x}) \otimes \phi(\mathbf{y})]
Exy[ϕ(x)⊗ϕ(y)]建模,其中
ϕ
\phi
ϕ是由某个再生核诱导的特征映射。这样的核嵌入可以操纵多个随机变量之间的乘法交互。
除了多线性映射
x
⊗
y
\mathrm{x} \otimes \mathbf{y}
x⊗y相对于级联映射
x
⊕
y
\mathrm{x} \oplus \mathrm{y}
x⊕y[ 47、46]的理论优势外,我们进一步直观地解释了其优越性。假设
C
C
C类中的线性映射
ϕ
(
x
)
=
x
\phi(\mathrm{x})=\mathrm{x}
ϕ(x)=x和one - hot标签向量
y
\mathrm{y}
y。可以证明,均值映射
E
x
y
[
x
⊕
y
]
=
E
x
[
x
]
⊕
E
y
[
y
]
\mathbb{E}_{\mathbf{x y}}[\mathbf{x} \oplus \mathbf{y}]=\mathbb{E}_{\mathbf{x}}[\mathbf{x}] \oplus \mathbb{E}_{\mathbf{y}}[\mathbf{y}]
Exy[x⊕y]=Ex[x]⊕Ey[y]独立计算
x
\mathbf{x}
x and
y
\mathrm{y}
y的均值。相反,均值映射
E
x
y
[
x
⊗
y
]
=
E
x
[
x
∣
y
=
1
]
⊕
…
⊕
E
x
[
x
∣
y
=
C
]
\mathbb{E}_{\mathbf{x y}}[\mathrm{x} \otimes \mathbf{y}]=\mathbb{E}_{\mathbf{x}}[\mathbf{x} \mid y=1] \oplus \ldots \oplus \mathbb{E}_{\mathbf{x}}[\mathbf{x} \mid y=C]
Exy[x⊗y]=Ex[x∣y=1]⊕…⊕Ex[x∣y=C] 计算每个
C
C
C类条件分布
P
(
x
∣
y
)
P(\mathbf{x} \mid y)
P(x∣y)的均值。相比于串联,多线性映射
x
⊗
y
\mathrm{x} \otimes \mathrm{y}
x⊗y可以充分捕捉复杂数据分布背后的多模态结构。利用多线性映射的优势,本文利用多线性映射对
g
\mathrm{g}
g上的
D
D
D进行条件化
T
⊗
(
f
,
g
)
=
f
⊗
g
T_{\otimes}(\mathbf{f}, \mathbf{g})=\mathbf{f} \otimes \mathbf{g}
T⊗(f,g)=f⊗g
式中:
T
⊗
T_{\otimes}
T⊗为多线性映射,
D
(
f
,
g
)
=
D
(
f
⊗
g
)
D(\mathbf{f}, \mathbf{g})=D(\mathbf{f} \otimes \mathbf{g})
D(f,g)=D(f⊗g)。因此,条件域判别器成功地建模了
f
\mathrm{f}
f and
g
\mathrm{g}
g 的多模态信息和联合分布。同时,多元线性回归可以容纳不同基数和大小的随机向量
f
\mathrm{f}
f and
g
\mathrm{g}
g 。
多线性映射的一个缺点是维度爆炸。用
d
f
d_f
df and
d
g
d_g
dg分别表示向量
f
\mathrm{f}
f and
g
\mathrm{g}
g 的维数,多线性映射
f
⊗
g
\mathrm{f} \otimes \mathrm{g}
f⊗g的维数为
d
f
×
d
g
d_f \times d_g
df×dg,往往维数太高,无法嵌入到深度网络中而不会引起参数爆炸。本文采用[ 40、26]随机化方法解决维度爆炸问题。注意,多线性映射成立
⟨
T
⊗
(
f
,
g
)
,
T
⊗
(
f
′
,
g
′
)
⟩
=
⟨
f
⊗
g
,
f
′
⊗
g
′
⟩
=
⟨
f
,
f
′
⟩
⟨
g
,
g
′
⟩
≈
⟨
T
⊙
(
f
,
g
)
,
T
⊙
(
f
′
,
g
′
)
⟩
,
\begin{aligned} \left\langle T_{\otimes}(\mathbf{f}, \mathbf{g}), T_{\otimes}\left(\mathbf{f}^{\prime}, \mathbf{g}^{\prime}\right)\right\rangle & =\left\langle\mathbf{f} \otimes \mathbf{g}, \mathbf{f}^{\prime} \otimes \mathbf{g}^{\prime}\right\rangle \\ & =\left\langle\mathbf{f}, \mathbf{f}^{\prime}\right\rangle\left\langle\mathbf{g}, \mathbf{g}^{\prime}\right\rangle \\ & \approx\left\langle T_{\odot}(\mathbf{f}, \mathbf{g}), T_{\odot}\left(\mathbf{f}^{\prime}, \mathbf{g}^{\prime}\right)\right\rangle, \end{aligned}
⟨T⊗(f,g),T⊗(f′,g′)⟩=⟨f⊗g,f′⊗g′⟩=⟨f,f′⟩⟨g,g′⟩≈⟨T⊙(f,g),T⊙(f′,g′)⟩,
其中
T
⊙
(
f
,
g
)
T_{\odot}(\mathbf{f}, \mathbf{g})
T⊙(f,g) 是维数为
d
≪
d
f
×
d
g
d \ll d_f \times d_g
d≪df×dg的显式随机多线性映射.我们定义
T
⊙
(
f
,
g
)
=
1
d
(
R
f
f
)
⊙
(
R
g
g
)
T_{\odot}(\mathbf{f}, \mathbf{g})=\frac{1}{\sqrt{d}}\left(\mathbf{R}_{\mathbf{f}} \mathbf{f}\right) \odot\left(\mathbf{R}_{\mathbf{g}} \mathbf{g}\right)
T⊙(f,g)=d1(Rff)⊙(Rgg)
其中
⊙
\odot
⊙是元素乘积,
R
f
\mathbf{R}_{\mathbf{f}}
Rf 和
R
g
\mathbf{R}_{\mathbf{g}}
Rg是只采样一次且在训练中固定的随机矩阵,每个元素
R
i
j
R_{i j}
Rij服从单变量的对称分布,即
E
[
R
i
j
]
=
\mathbb{E}\left[R_{i j}\right]=
E[Rij]=
0
,
E
[
R
i
j
2
]
=
1
0, \mathbb{E}\left[R_{i j}^2\right]=1
0,E[Rij2]=1。适用的分布包括高斯分布和均匀分布。由于
T
⊗
T_{\otimes}
T⊗ 上的内积可以被
T
⊙
T_{\odot}
T⊙上的内积精确逼近,为了计算效率,我们可以直接采用
T
⊙
(
f
,
g
)
T_{\odot}(\mathbf{f}, \mathbf{g})
T⊙(f,g) 。我们通过一个定理来保证这样的逼近质量。
定理1。利用
T
⊙
(
f
,
g
)
T_{\odot}(\mathbf{f}, \mathbf{g})
T⊙(f,g) ( 6 )逼近
T
⊗
(
f
,
g
)
T_{\otimes}(\mathbf{f}, \mathrm{g})
T⊗(f,g)( 4 )的期望和方差满足
E
[
⟨
T
⊙
(
f
,
g
)
,
T
⊙
(
f
′
,
g
′
)
⟩
]
=
⟨
f
,
f
′
⟩
⟨
g
,
g
′
⟩
,
var
[
⟨
T
⊙
(
f
,
g
)
,
T
⊙
(
f
′
,
g
′
)
⟩
]
=
∑
i
=
1
d
β
(
R
i
f
,
f
)
β
(
R
i
g
,
g
)
+
C
,
\begin{gathered} \mathbb{E}\left[\left\langle T_{\odot}(\mathbf{f}, \mathbf{g}), T_{\odot}\left(\mathbf{f}^{\prime}, \mathbf{g}^{\prime}\right)\right\rangle\right]=\left\langle\mathbf{f}, \mathbf{f}^{\prime}\right\rangle\left\langle\mathbf{g}, \mathbf{g}^{\prime}\right\rangle, \\ \operatorname{var}\left[\left\langle T_{\odot}(\mathbf{f}, \mathbf{g}), T_{\odot}\left(\mathbf{f}^{\prime}, \mathbf{g}^{\prime}\right)\right\rangle\right]=\sum_{i=1}^d \beta\left(\mathbf{R}_i^{\mathbf{f}}, \mathbf{f}\right) \beta\left(\mathbf{R}_i^{\mathbf{g}}, \mathbf{g}\right)+C, \end{gathered}
E[⟨T⊙(f,g),T⊙(f′,g′)⟩]=⟨f,f′⟩⟨g,g′⟩,var[⟨T⊙(f,g),T⊙(f′,g′)⟩]=i=1∑dβ(Rif,f)β(Rig,g)+C,
其中
β
(
R
i
f
,
f
)
=
1
d
∑
j
=
1
d
f
[
f
j
2
f
j
′
2
E
[
(
R
i
j
f
)
4
]
+
C
′
]
\beta\left(\mathbf{R}_i^{\mathbf{f}}, \mathbf{f}\right)=\frac{1}{d} \sum_{j=1}^{d_f}\left[f_j^2 f_j^{\prime 2} \mathbb{E}\left[\left(R_{i j}^f\right)^4\right]+C^{\prime}\right]
β(Rif,f)=d1∑j=1df[fj2fj′2E[(Rijf)4]+C′] 和
β
(
R
i
g
,
g
)
,
C
,
C
′
\beta\left(\mathbf{R}_i^{\mathbf{g}}, \mathbf{g}\right), C, C^{\prime}
β(Rig,g),C,C′ 类似,
β
(
R
i
g
,
g
)
,
C
,
C
′
\beta\left(\mathbf{R}_i^{\mathbf{g}}, \mathbf{g}\right), C, C^{\prime}
β(Rig,g),C,C′ 为常数.证明。证明在补充材料中给出。
这验证了
T
⊙
T_{\odot}
T⊙是
T
⊗
T_{\otimes}
T⊗内积项的无偏估计,其估计方差只取决于四阶矩
E
[
(
R
i
j
f
)
4
]
\mathbb{E}\left[\left(R_{i j}^f\right)^4\right]
E[(Rijf)4] 和
E
[
(
R
i
j
g
)
4
]
\mathbb{E}\left[\left(R_{i j}^g\right)^4\right]
E[(Rijg)4],这两个矩对于许多具有单变量的对称分布,包括高斯分布和均匀分布,都是常数。该界表明,通过对特征进行归一化,可以进一步最小化逼近误差。为了简单起见,我们定义条件域判别器
D
D
D使用的条件策略为
T
(
h
)
=
{
T
⊗
(
f
,
g
)
if
d
f
×
d
g
⩽
4096
T
⊙
(
f
,
g
)
otherwise
T(\mathbf{h})= \begin{cases}T_{\otimes}(\mathbf{f}, \mathbf{g}) & \text { if } d_f \times d_g \leqslant 4096 \\ T_{\odot}(\mathbf{f}, \mathbf{g}) & \text { otherwise }\end{cases}
T(h)={T⊗(f,g)T⊙(f,g) if df×dg⩽4096 otherwise
其中,4096是典型深度网络中数量最多的单元(例如:AlexNet ),若多线性映射
T
⊗
T_{\otimes}
T⊗的维数大于4096,则选择随机多线性映射
T
⊙
T_{\odot}
T⊙。
3.3 Conditional Domain Adversarial Network
我们对特定领域的特征表示
f
\mathrm{f}
f和分类器预测g进行条件对抗域适应。联合最小化( 1 ) w.r.t.源分类器
G
G
G和特征提取器
F
F
F,最小化( 2 ) w.r.t.域判别器
D
D
D,最大化( 2 ) w.r.t.特征提取器
F
F
F和源分类器
G
G
G,得到条件域对抗网络( Conditional Domain Adversarial Network,CDAN )的minimax问题:
min
G
E
(
x
i
s
,
y
i
s
)
∼
D
s
L
(
G
(
x
i
s
)
,
y
i
s
)
+
λ
(
E
x
i
s
∼
D
s
log
[
D
(
T
(
h
i
s
)
)
]
+
E
x
j
t
∼
D
t
log
[
1
−
D
(
T
(
h
j
t
)
)
]
)
max
D
E
x
i
s
∼
D
s
log
[
D
(
T
(
h
i
s
)
)
]
+
E
x
j
t
∼
D
t
log
[
1
−
D
(
T
(
h
j
t
)
)
]
,
\begin{aligned} & \min _G \mathbb{E}_{\left(\mathbf{x}_i^s, \mathbf{y}_i^s\right) \sim \mathcal{D}_s} L\left(G\left(\mathbf{x}_i^s\right), \mathbf{y}_i^s\right) \\ & \quad+\lambda\left(\mathbb{E}_{\mathbf{x}_i^s \sim \mathcal{D}_s} \log \left[D\left(T\left(\mathbf{h}_i^s\right)\right)\right]+\mathbb{E}_{\mathbf{x}_j^t \sim \mathcal{D}_t} \log \left[1-D\left(T\left(\mathbf{h}_j^t\right)\right)\right]\right) \\ & \max _D \mathbb{E}_{\mathbf{x}_i^s \sim \mathcal{D}_s} \log \left[D\left(T\left(\mathbf{h}_i^s\right)\right)\right]+\mathbb{E}_{\mathbf{x}_j^t \sim \mathcal{D}_t} \log \left[1-D\left(T\left(\mathbf{h}_j^t\right)\right)\right], \end{aligned}
GminE(xis,yis)∼DsL(G(xis),yis)+λ(Exis∼Dslog[D(T(his))]+Exjt∼Dtlog[1−D(T(hjt))])DmaxExis∼Dslog[D(T(his))]+Exjt∼Dtlog[1−D(T(hjt))],
其中
λ
\lambda
λ 是源分类器和条件域判别器之间的超参数,并且注意到
h
=
(
f
,
g
)
\mathbf{h}=(\mathbf{f}, \mathbf{g})
h=(f,g)是对抗自适应领域特征表示
f
\mathbf{f}
f和分类器预测
g
\mathrm{g}
g的联合变量。作为经验法则,我们可以安全地设置f为最后一个特征层表示,
g
\mathrm{g}
g为分类器层预测。在底层特征不能像像素级自适应任务[ 25,22]那样迁移的情况下,我们可以将
f
\mathbf{f}
f改为底层表示。
熵条件化条件域判别器( 9 )的极小极大问题对不同的示例具有同等的重要性,而具有不确定预测的难迁移示例可能会恶化条件对抗自适应过程。为了实现安全迁移,我们通过熵准则
H
(
g
)
=
−
∑
c
=
1
C
g
c
log
g
c
H(\mathrm{~g})=-\sum_{c=1}^C g_c \log g_c
H( g)=−∑c=1Cgcloggc来量化分类器预测的不确定性,其中
C
C
C是类的个数,
g
c
g_c
gc 是预测一个实例到类
c
c
c的概率。我们通过一个熵感知权重
w
(
H
(
g
)
)
=
1
+
e
−
H
(
g
)
w(H(\mathbf{g}))=1+e^{-H(\mathbf{g})}
w(H(g))=1+e−H(g)对条件域判别器的每个训练示例进行重加权,将判别器优先放在那些具有一定预测的易于迁移的示例上。为了提高可传递性,提出了CDAN的熵调节变量(CDAN+E)
min
G
E
(
x
i
s
,
y
i
s
)
∼
D
s
L
(
G
(
x
i
s
)
,
y
i
s
)
+
λ
(
E
x
i
s
∼
D
s
w
(
H
(
g
i
s
)
)
log
[
D
(
T
(
h
i
s
)
)
]
+
E
x
j
t
∼
D
t
w
(
H
(
g
j
t
)
)
log
[
1
−
D
(
T
(
h
j
t
)
)
]
)
max
D
E
x
i
s
∼
D
s
w
(
H
(
g
i
s
)
)
log
[
D
(
T
(
h
i
s
)
)
]
+
E
x
j
t
∼
D
t
w
(
H
(
g
j
t
)
)
log
[
1
−
D
(
T
(
h
j
t
)
)
]
.
\begin{aligned} & \min _G \mathbb{E}_{\left(\mathbf{x}_i^s, \mathbf{y}_i^s\right) \sim \mathcal{D}_s} L\left(G\left(\mathbf{x}_i^s\right), \mathbf{y}_i^s\right) \\ & \quad+\lambda\left(\mathbb{E}_{\mathbf{x}_i^s \sim \mathcal{D}_s} w\left(H\left(\mathbf{g}_i^s\right)\right) \log \left[D\left(T\left(\mathbf{h}_i^s\right)\right)\right]+\mathbb{E}_{\mathbf{x}_j^t \sim \mathcal{D}_t} w\left(H\left(\mathbf{g}_j^t\right)\right) \log \left[1-D\left(T\left(\mathbf{h}_j^t\right)\right)\right]\right) \\ & \max _D \mathbb{E}_{\mathbf{x}_i^s \sim \mathcal{D}_s} w\left(H\left(\mathbf{g}_i^s\right)\right) \log \left[D\left(T\left(\mathbf{h}_i^s\right)\right)\right]+\mathbb{E}_{\mathbf{x}_j^t \sim \mathcal{D}_t} w\left(H\left(\mathbf{g}_j^t\right)\right) \log \left[1-D\left(T\left(\mathbf{h}_j^t\right)\right)\right] . \end{aligned}
GminE(xis,yis)∼DsL(G(xis),yis)+λ(Exis∼Dsw(H(gis))log[D(T(his))]+Exjt∼Dtw(H(gjt))log[1−D(T(hjt))])DmaxExis∼Dsw(H(gis))log[D(T(his))]+Exjt∼Dtw(H(gjt))log[1−D(T(hjt))].
领域判别器赋予熵最小化原则[ 19 ],鼓励一定的预测,使CDAN + E能够进一步对未标记的目标数据进行半监督学习。
3.4 Generalization Error Analysis
我们采用类似领域适应理论[ 5、4]的形式对CDAN方法进行分析。首先考虑固定表示空间
f
=
F
(
x
)
\mathrm{f}=F(\mathrm{x})
f=F(x)上的源域和目标域,以及假设空间
H
\mathcal{H}
H中的一族源分类器
G
G
G [ 13 ]。令
ϵ
P
(
G
)
=
E
(
f
,
y
)
∼
P
[
G
(
f
)
≠
y
]
\epsilon_P(G)=\mathbb{E}_{(\mathbf{f}, \mathbf{y}) \sim P}[G(\mathbf{f}) \neq \mathbf{y}]
ϵP(G)=E(f,y)∼P[G(f)=y]表示假设
G
∈
H
G \in \mathcal{H}
G∈H 的风险分布
P
P
P,
ϵ
P
(
G
1
,
G
2
)
=
E
(
f
,
y
)
∼
P
[
G
1
(
f
)
≠
G
2
(
f
)
]
\epsilon_P\left(G_1, G_2\right)=\mathbb{E}_{(\mathbf{f}, \mathbf{y}) \sim P}\left[G_1(\mathbf{f}) \neq G_2(\mathbf{f})\right]
ϵP(G1,G2)=E(f,y)∼P[G1(f)=G2(f)]表示假设
G
1
,
G
2
∈
H
G_1, G_2 \in \mathcal{H}
G1,G2∈H之间的分歧.令
G
∗
=
arg
min
G
ϵ
P
(
G
)
+
ϵ
Q
(
G
)
G^*=\arg \min _G \epsilon_P(G)+\epsilon_Q(G)
G∗=argminGϵP(G)+ϵQ(G)是明确体现适应性概念的理想假设.假设
G
G
G的目标风险
ϵ
Q
(
G
)
\epsilon_Q(G)
ϵQ(G)的概率界[ 4 ]由源风险
ϵ
P
(
G
)
\epsilon_P(G)
ϵP(G)加上分布差异给出
ϵ
Q
(
G
)
⩽
ϵ
P
(
G
)
+
[
ϵ
P
(
G
∗
)
+
ϵ
Q
(
G
∗
)
]
+
∣
ϵ
P
(
G
,
G
∗
)
−
ϵ
Q
(
G
,
G
∗
)
∣
\epsilon_Q(G) \leqslant \epsilon_P(G)+\left[\epsilon_P\left(G^*\right)+\epsilon_Q\left(G^*\right)\right]+\left|\epsilon_P\left(G, G^*\right)-\epsilon_Q\left(G, G^*\right)\right|
ϵQ(G)⩽ϵP(G)+[ϵP(G∗)+ϵQ(G∗)]+∣ϵP(G,G∗)−ϵQ(G,G∗)∣
域适应的目标是减少分布差异
∣
ϵ
P
(
G
,
G
∗
)
−
ϵ
Q
(
G
,
G
∗
)
∣
\left|\epsilon_P\left(G, G^*\right)-\epsilon_Q\left(G, G^*\right)\right|
∣ϵP(G,G∗)−ϵQ(G,G∗)∣.
根据定义,
ϵ
P
(
G
,
G
∗
)
=
E
(
f
,
y
)
∼
P
[
G
(
f
)
≠
G
∗
(
f
)
]
=
E
(
f
,
g
)
∼
P
G
[
g
≠
G
∗
(
f
)
]
=
ϵ
P
G
(
G
∗
)
\epsilon_P\left(G, G^*\right)=\mathbb{E}_{(\mathbf{f}, \mathbf{y}) \sim P}\left[G(\mathbf{f}) \neq G^*(\mathbf{f})\right]=\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim P_G}\left[\mathbf{g} \neq G^*(\mathbf{f})\right]=\epsilon_{P_G}\left(G^*\right)
ϵP(G,G∗)=E(f,y)∼P[G(f)=G∗(f)]=E(f,g)∼PG[g=G∗(f)]=ϵPG(G∗), 同理,
ϵ
Q
(
G
,
G
∗
)
=
ϵ
Q
G
(
G
∗
)
\epsilon_Q\left(G, G^*\right)=\epsilon_{Q_G}\left(G^*\right)
ϵQ(G,G∗)=ϵQG(G∗).注意到,
P
G
=
(
f
,
G
(
f
)
)
f
∼
P
(
f
)
P_G=(\mathbf{f}, G(\mathbf{f}))_{\mathbf{f} \sim P(\mathbf{f})}
PG=(f,G(f))f∼P(f) and
Q
G
=
(
f
,
G
(
f
)
)
f
∼
Q
(
f
)
Q_G=(\mathbf{f}, G(\mathbf{f}))_{\mathbf{f} \sim Q(\mathbf{f})}
QG=(f,G(f))f∼Q(f) 分别是联合分布
P
(
f
,
y
)
P(\mathbf{f}, \mathbf{y})
P(f,y) and
Q
(
f
,
y
)
Q(\mathbf{f}, \mathbf{y})
Q(f,y), 的代理[ 10 ]. 基于代理,,
∣
ϵ
P
(
G
,
G
∗
)
−
ϵ
Q
(
G
,
G
∗
)
∣
=
∣
ϵ
P
G
(
G
∗
)
−
ϵ
Q
G
(
G
∗
)
∣
\left|\epsilon_P\left(G, G^*\right)-\epsilon_Q\left(G, G^*\right)\right|=\left|\epsilon_{P_G}\left(G^*\right)-\epsilon_{Q_G}\left(G^*\right)\right|
∣ϵP(G,G∗)−ϵQ(G,G∗)∣=∣ϵPG(G∗)−ϵQG(G∗)∣. 定义联合变量 (f, g)上的(损失)差分假设空间
Δ
≜
{
δ
=
∣
g
−
G
∗
(
f
)
∣
:
G
∗
∈
H
}
\Delta \triangleq\left\{\delta=\left|\mathbf{g}-G^*(\mathbf{f})\right|: G^* \in \mathcal{H}\right\}
Δ≜{δ=∣g−G∗(f)∣:G∗∈H} , ,其中
δ
:
(
f
,
g
)
↦
{
0
,
1
}
\delta:(\mathbf{f}, \mathbf{g}) \mapsto\{0,1\}
δ:(f,g)↦{0,1} 输出
G
∗
∈
H
G^* \in \mathcal{H}
G∗∈H的损失。基于上述差分假设空间
Δ
\Delta
Δ, 我们定义
Δ
−
\Delta-
Δ− 距离为
d
Δ
(
P
G
,
Q
G
)
≜
sup
δ
∈
Δ
∣
E
(
f
,
g
)
∼
P
G
[
δ
(
f
,
g
)
≠
0
]
−
E
(
f
,
g
)
∼
Q
G
[
δ
(
f
,
g
)
≠
0
]
∣
=
sup
G
∗
∈
H
∣
E
(
f
,
g
)
∼
P
G
[
∣
g
−
G
∗
(
f
)
∣
≠
0
]
−
E
(
f
,
g
)
∼
Q
G
[
∣
g
−
G
∗
(
f
)
∣
≠
0
]
∣
⩾
∣
E
(
f
,
g
)
∼
P
G
[
g
≠
G
∗
(
f
)
]
−
E
(
f
,
g
)
∼
Q
G
[
g
≠
G
∗
(
f
)
]
∣
=
∣
ϵ
P
G
(
G
∗
)
−
ϵ
Q
G
(
G
∗
)
∣
\begin{aligned} d_{\Delta}\left(P_G, Q_G\right) & \triangleq \sup _{\delta \in \Delta}\left|\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim P_G}[\delta(\mathbf{f}, \mathbf{g}) \neq 0]-\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim Q_G}[\delta(\mathbf{f}, \mathbf{g}) \neq 0]\right| \\ & =\sup _{G^* \in \mathcal{H}}\left|\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim P_G}\left[\left|\mathbf{g}-G^*(\mathbf{f})\right| \neq 0\right]-\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim Q_G}\left[\left|\mathbf{g}-G^*(\mathbf{f})\right| \neq 0\right]\right| \\ & \geqslant\left|\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim P_G}\left[\mathbf{g} \neq G^*(\mathbf{f})\right]-\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim Q_G}\left[\mathbf{g} \neq G^*(\mathbf{f})\right]\right|=\left|\epsilon_{P_G}\left(G^*\right)-\epsilon_{Q_G}\left(G^*\right)\right| \end{aligned}
dΔ(PG,QG)≜δ∈Δsup
E(f,g)∼PG[δ(f,g)=0]−E(f,g)∼QG[δ(f,g)=0]
=G∗∈Hsup
E(f,g)∼PG[∣g−G∗(f)∣=0]−E(f,g)∼QG[∣g−G∗(f)∣=0]
⩾
E(f,g)∼PG[g=G∗(f)]−E(f,g)∼QG[g=G∗(f)]
=∣ϵPG(G∗)−ϵQG(G∗)∣
因此,域偏差
∣
ϵ
P
(
G
,
G
∗
)
−
ϵ
Q
(
G
,
G
∗
)
∣
\left|\epsilon_P\left(G, G^*\right)-\epsilon_Q\left(G, G^*\right)\right|
∣ϵP(G,G∗)−ϵQ(G,G∗)∣ 可以通过
Δ
\Delta
Δ-距离上界。由于差分假设空间
Δ
\Delta
Δ是连续函数类,假设域判别器
H
D
\mathcal{H}_D
HD的族足够丰富,可以包含
Δ
,
Δ
⊂
H
D
\Delta, \Delta \subset \mathcal{H}_D
Δ,Δ⊂HD。这样的假设并不是不现实的,因为我们有选择
H
D
\mathcal{H}_D
HD的自由,例如,可以拟合任何函数的多层感知器。在这些假设下,我们证明训练域判别器
D
D
D与
d
Δ
(
P
G
,
Q
G
)
d_{\Delta}\left(P_G, Q_G\right)
dΔ(PG,QG)有关:
d
Δ
(
P
G
,
Q
G
)
⩽
sup
D
∈
H
D
∣
E
(
f
,
g
)
∼
P
G
[
D
(
f
,
g
)
≠
0
]
−
E
(
f
,
g
)
∼
Q
G
[
D
(
f
,
g
)
≠
0
]
∣
⩽
sup
D
∈
H
D
∣
E
(
f
,
g
)
∼
P
G
[
D
(
f
,
g
)
=
1
]
+
E
(
f
,
g
)
∼
Q
G
[
D
(
f
,
g
)
=
0
]
∣
.
\begin{aligned} d_{\Delta}\left(P_G, Q_G\right) & \leqslant \sup _{D \in \mathcal{H}_D}\left|\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim P_G}[D(\mathbf{f}, \mathbf{g}) \neq 0]-\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim Q_G}[D(\mathbf{f}, \mathbf{g}) \neq 0]\right| \\ & \leqslant \sup _{D \in \mathcal{H}_D}\left|\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim P_G}[D(\mathbf{f}, \mathbf{g})=1]+\mathbb{E}_{(\mathbf{f}, \mathbf{g}) \sim Q_G}[D(\mathbf{f}, \mathbf{g})=0]\right| . \end{aligned}
dΔ(PG,QG)⩽D∈HDsup
E(f,g)∼PG[D(f,g)=0]−E(f,g)∼QG[D(f,g)=0]
⩽D∈HDsup
E(f,g)∼PG[D(f,g)=1]+E(f,g)∼QG[D(f,g)=0]
.
该上确界是在CDAN训练最优判别器
D
D
D的过程中实现的,给出了
d
Δ
(
P
G
,
Q
G
)
d_{\Delta}\left(P_G, Q_G\right)
dΔ(PG,QG)的上界。同时,我们学习表示
f
\mathrm{f}
f 来最小化
d
Δ
(
P
G
,
Q
G
)
d_{\Delta}\left(P_G, Q_G\right)
dΔ(PG,QG),使得
ϵ
Q
(
G
)
\epsilon_Q(G)
ϵQ(G)被
ϵ
P
(
G
)
\epsilon_P(G)
ϵP(G) 更好地近似,从而在minimax范式中约束目标风险。
4 Experiments
我们用许多先进的迁移学习和深度学习方法来评估所提出的条件域对抗网络。http://github.com/thuml/CDAN.
4.1 Setup
Office-31 [ 42 ]是目前应用最广泛的视觉域自适应数据集,从Amazon ( A )、Webcam ( W )和DSLR ( D ) 3个不同的域收集了4 652张图像和31个类别。我们在六个迁移任务A→W,D→W,W→D,A→D,D→A和W→A上对所有方法进行了评估。
ImageCLEF - DA1是由加州理工学院- 256 ( C ),ImageNet ILSVRC 2012 ( I )和Pascal VOC 2012 ( P )三个公开数据集(域)共享的12个公共类组成的数据集。我们对三个域进行置换,构建了六个迁移任务:I→P,P→I,I→C,C→I,C→P,P→C。
Office-Home [ 53 ]是一个比Office - 31更好组织但更困难的数据集,该数据集由办公室和家庭环境中65个对象类的15500张图像组成,形成了四个截然不同的领域:Artistic Image ( Ar )、Clip Art ( Cl )、Product Image ( Pr )和Real - World Image ( Rw )。
Digits We调查了三位数的数据集:MNIST、USPS和街景房号( SVHN )。采用Cy CADA [ 22 ]的评估协议,有3个迁移任务:USPS到MNIST ( U→M),MNIST到USPS ( M→U),SVHN到MNIST ( S→M)。我们使用训练集:MNIST ( 6万),USPS ( 7 291),标准SVHN train ( 73257)来训练我们的模型。在标准测试集MNIST (万),USPS ( 2,007) (括号内为图像的数量)上进行评估。
VisDA - 20172是一个具有挑战性的模拟到真实的数据集,有两个非常独特的领域:合成,从不同角度和不同闪电条件的三维模型渲染;真实、自然的图像。它在训练域、验证域和测试域中包含超过280K幅图像,跨越12个类别。
我们将条件域对抗网络( CDAN )与当前最先进的域适应方法:深度适应网络( DAN ) [ 29 ]、残差迁移网络( RTN ) [ 31 ]、域对抗神经网络( DANN ) [ 13 ]、对抗判别域适应( ADDA ) [ 51 ]、联合适应网络( JAN ) [ 30 ]、无监督图像到图像转换( UNIT ) [ 28 ]、生成适应( GTA ) [ 43 ]、循环一致域适应( CyCADA ) [ 22 ]进行比较。
我们遵循无监督域适应[ 12、30]的标准协议。我们使用所有有标签的源示例和所有无标签的目标示例,基于3次随机实验比较平均分类准确率。我们使用重要性加权交叉验证( IWCV ) [ 48 ]来选择所有方法的超参数。由于CDAN在不同参数下表现稳定,我们固定λ = 1进行所有实验。对于基于MMD的方法( TCA、DAN、RTN、JAN),我们在训练数据上使用带宽设置为成对距离中值的高斯核[ 29 ]。我们采用AlexNet [ 27 ]和ResNet - 50 [ 20 ]作为基础网络,所有方法仅在判别器上有所区别。
我们在Caffe中实现了基于AlexNet的方法,在PyTorch中实现了基于ResNet的方法。我们从ImageNet预训练的模型中微调[ 41 ],除了我们从头开始训练模型的数字数据集。我们通过反向传播来训练新层和分类器层,其中分类器从头开始训练,学习速率是下层的10倍。我们采用动量为0.9的小批量SGD和学习率退火策略[ 13 ]:学习率由
η
p
=
η
0
(
1
+
α
p
)
−
β
\eta_p=\eta_0(1+\alpha p)^{-\beta}
ηp=η0(1+αp)−β调节,其中
p
p
p是训练进度从0到1的变化,
η
0
=
0.01
,
α
=
10
\eta_0=0.01, \alpha=10
η0=0.01,α=10,
β
=
0.75
\beta=0.75
β=0.75通过重要性加权交叉验证优化[ 48 ]。我们对判别器采用渐进式的训练策略,通过乘以
1
−
exp
(
−
δ
p
)
1
+
exp
(
−
δ
p
)
,
δ
=
10
\frac{1-\exp (-\delta p)}{1+\exp (-\delta p)}, \delta=10
1+exp(−δp)1−exp(−δp),δ=10将
λ
\lambda
λ从0增加到1。
4.2结果
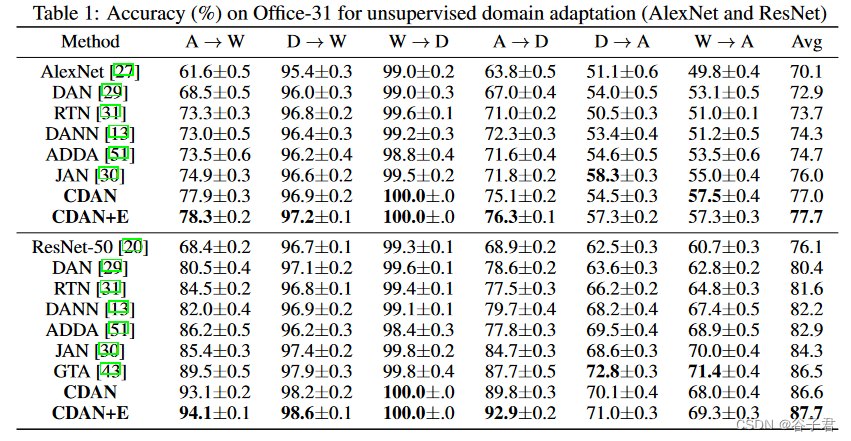
基于AlexNet和ResNet的Office - 31的结果报告在表1中,如果协议相同,基线的结果直接从原始论文中报告。在大多数迁移任务上,CDAN模型显著优于所有对比方法,其中CDAN + E表现最好,CDAN表现稍差。我们希望CDAN在硬迁移任务上能够显著提高分类准确率。A→W和A→D,其中源域和目标域有本质区别[ 42 ]。值得注意的是,CDAN + E甚至优于生成式像素级域适应方法GTA,后者在架构和目标上都有非常复杂的设计。
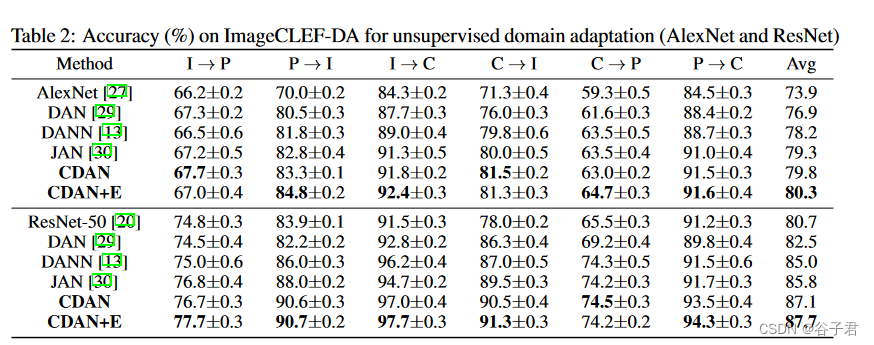
在ImageCLEF - DA数据集上的实验结果如表2所示。CDAN模型在大多数迁移任务上优于对比方法,但改进空间较小。这是合理的,因为ImageCLEF - DA中的三个域大小相等,在每个类别中平衡,并且在视觉上比Office - 31更相似,使得前者的数据集更容易进行域适应。
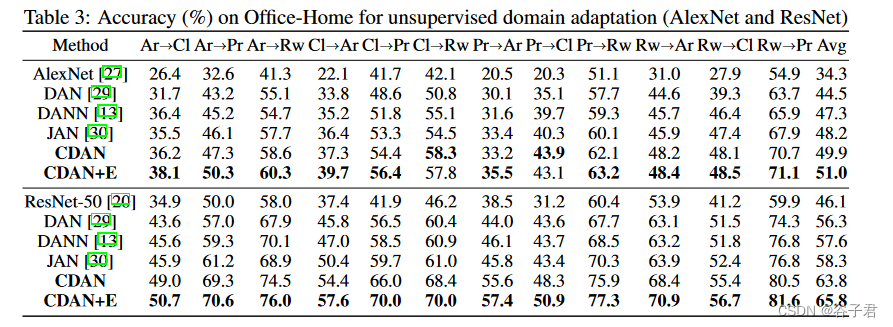
Office - Home上的结果报告在表3中。CDAN模型在大多数迁移任务上都明显优于对比方法,且具有较大的改进空间。一种解释是Office - Home中的四个域具有更多的类别,它们在视觉上更不相似,并且在每个域中都很困难,域内分类精度较低[ 53 ]。由于在先前的工作中,域对齐是类别无关的,因此有可能在存在大量类别的情况下,对齐的域不具有分类友好性。CDAN模型有望在这类困难的域适应任务上获得更大的提升,这突出了通过在分类器预测中利用复杂的多模态结构进行对抗域适应的力量。
在数字数据集和合成真实数据集上也取得了很好的效果,如表4所示。值得注意的是,生成式像素级自适应方法UNIT、CyCADA和GTA是专门针对数字量定制的,并合成到真实的自适应任务中。这就解释了为什么之前的特征级自适应方法JAN表现相当弱。据我们所知,CDAN + E是唯一一个在所有5个数据集上都能正常工作的方法,并且仍然是一个简单的判别模型。

4.3 Analysis
消融研究我们研究了方程( 6 )中随机矩阵的采样策略。我们证明了CDAN + E ( w /高斯采样)和CDAN + E ( w /均匀采样),它们的随机矩阵只从高斯分布和均匀分布中采样一次。由表5可知,CDAN + E ( w / o随机抽样)表现最好,CDAN + E ( w /均匀采样)表现最好。表1⋅4显示CDAN + E优于CDAN,证明了熵条件化可以优先处理易于迁移的示例并鼓励某些预测。
条件化策略除了多线性条件化外,我们还研究了DANN - [ f , g]和DANN - f以及DANN - g。DANN - [ f , g]和DANN - g分别是在特征层f和分类器层g中插入域判别器。图2 ( a )展示了基于ResNet - 50的A→W和A→D的准确率。级联策略并不成功,因为它无法捕获对域适应至关重要的特征和类之间的交叉协方差[ 10 ]。从图2 ( b )可以看出,熵权e - H ( g )与预测正确性有很好的对应关系:预测正确时熵权≈1,预测不正确(不确定)时熵权远小于1。这揭示了熵条件化对保证样例可迁移性的力量。
分布差异度A距离是分布差异度[ 4、33]的度量,定义为distA = 2( 1-2 ),其中是训练好的分类器判别源目标的测试误差。图2 ( c )展示了在ResNet、DANN和CDAN特征的任务A→W、W→D上的distA。我们观察到CDAN特征上的dist A小于ResNet和DANN特征上的dist A,说明CDAN特征能更有效地缩小域间隙。由于W和D相似,任务W→D的distA小于任务A→W的distA,表明其正确率更高。
收敛性我们验证了Res Net、DANN和CDANs的收敛性,在任务A→W上的测试误差如图2 ( d )所示。CDAN比DANN收敛快,而CDAN ( M )比CDAN ( RM )收敛快。注意,CDAN ( M )构成高维多线性映射,其成本略高于CDAN ( RM ),而CDAN ( RM )的成本与DANN相当。
可视化我们通过t - SNE [ 32 ]在图3 ( a ) ~ 3 ( d )中可视化Res Net、DANN、CDAN - f和CDAN - fg对任务A→W ( 31类)的表示。源和目标与ResNet没有很好的对齐,与DANN有较好的对齐但类别没有很好的区分。CDAN - f比CDAN - f对齐更好,类别区分更好,而CDAN - fg明显优于CDAN - f。这说明了条件对抗适应对判别性预测的益处。

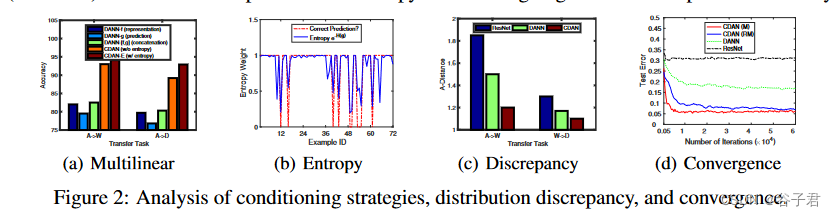
图二 条件化策略、分布差异和收敛性分析。

5结论
本文提出了条件域对抗网络( CDANs ),多模态分布的域适应新方法。与以往的对抗自适应方法仅匹配跨域的特征表示容易出现低匹配的问题不同,所提出的方法进一步将对抗域适应限定在判别信息上,以实现多模态分布的对齐。实验验证了所提方法的有效性。














 777
777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









