






VADER(Valence Aware Dictionary and sEntiment Reasoner)是专门为社交媒体进行情感分析的工具,目前仅支持英文文本,大邓在这里推荐给大家使用。大家可以结合大邓的教程
,自己采集数据自己进行分析。
VADER情感信息会考虑:
否定表达(如,"not good")
能表达情感信息和强度的标点符号 (如, "Good!!!")
大小写等形式带来的强调,(如,"FUNNY.")
情感强度(强度增强,如"very" ;强度减弱如, "kind of")
表达情感信息的俚语 (如, 'sux')
能修饰俚语情感强度的词语 ('uber'、'friggin'、'kinda')
表情符号 :) and :D
utf-8编码中的emoj情感表情 ( ? and ? and ?)
首字母缩略语(如,'lol') ...
VADER目前只支持英文文本,如果有符合VADER形式的中文词典,也能使用VADER对中文进行分析。
安装VADER
pip3 install vaderSentiment使用方法
VADER会对文本分析,得到的结果是一个字典信息,包含
pos,文本中正面信息得分
neg,文本中负面信息得分
neu,文本中中性信息得分
compound,文本综合情感得分
文本情感分类
依据compound综合得分对文本进行分类的标准
正面:compound score >= 0.05
中性: -0.05 < compound score < 0.05
负面: compound score <= -0.05
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
test = "VADER is smart, handsome, and funny."
analyzer.polarity_scores(test)运行
{'neg': 0.0, 'neu': 0.254, 'pos': 0.746, 'compound': 0.8316}这里我们只使用 compound 得分,用更多的例子让大家看到感叹号、俚语、emoji、强调等不同方式对得分的影响。为了方便,我们想将结果以dataframe方式展示
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
import pandas as pd
analyzer = SentimentIntensityAnalyzer()
sentences = ["VADER is smart, handsome, and funny.",
"VADER is smart, handsome, and funny!", #带感叹号
"VADER is very smart, handsome, and funny.",
"VADER is VERY SMART, handsome, and FUNNY.", #FUNNY.强调
"VADER is VERY SMART, handsome, and FUNNY!!!",
"VADER is VERY SMART, uber handsome, and FRIGGIN FUNNY!!!",
"VADER is not smart, handsome, nor funny.",
"The book was good.",
"At least it isn't a horrible book.",
"The book was only kind of good.",
"The plot was good, but the characters are uncompelling and the dialog is not great.",
"Today SUX!",
"Today only kinda sux! But I'll get by, lol", #lol缩略语
"Make sure you :) or :D today!",
"Catch utf-8 emoji such as such as ? and ? and ?", #emoji
"Not bad at all"
]
def senti(text):
return analyzer.polarity_scores(text)['compound']
df = pd.DataFrame(sentences)
df.columns = ['text']
#对text列使用senti函数进行批处理,得到的得分赋值给sentiment列
df['sentiment'] = df.agg({'text':[senti]})
df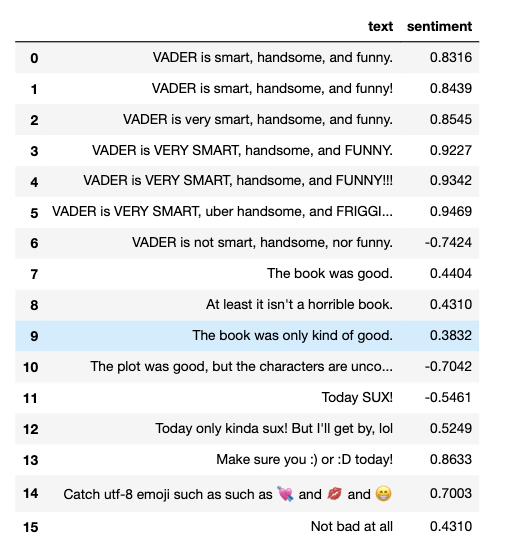
更多
VADER目前只支持英文文本,如果想要对中文文本进行分析,需要做两大方面改动。
对于初学者来说有难度,建议大家不着急的话可以系统学完python基础语法,大概学习使用python数周就能自己更改库的源代码。
首先要将库中的vaderSentiment.py中相应的英文词语改为中文词语
# (empirically derived mean sentiment intensity rating increase for booster words)
B_INCR = 0.293
B_DECR = -0.293
# (empirically derived mean sentiment intensity rating increase for using ALLCAPs to emphasize a word)
C_INCR = 0.733
N_SCALAR = -0.74
#否定词
NEGATE = \
["aint", "arent", "cannot", "cant", "couldnt", "darent", "didnt", "doesnt",
"ain't", "aren't", "can't", "couldn't", "daren't", "didn't", "doesn't",
"dont", "hadnt", "hasnt", "havent", "isnt", "mightnt", "mustnt", "neither",
"don't", "hadn't", "hasn't", "haven't", "isn't", "mightn't", "mustn't",
"neednt", "needn't", "never", "none", "nope", "nor", "not", "nothing", "nowhere",
"oughtnt", "shant", "shouldnt", "uhuh", "wasnt", "werent",
"oughtn't", "shan't", "shouldn't", "uh-uh", "wasn't", "weren't",
"without", "wont", "wouldnt", "won't", "wouldn't", "rarely", "seldom", "despite"]
# booster/dampener 'intensifiers' or 'degree adverbs'
# http://en.wiktionary.org/wiki/Category:English_degree_adverbs
# 情感强度 副词
BOOSTER_DICT = \
{"absolutely": B_INCR, "amazingly": B_INCR, "awfully": B_INCR,
"completely": B_INCR, "considerable": B_INCR, "considerably": B_INCR,
"decidedly": B_INCR, "deeply": B_INCR, "effing": B_INCR, "enormous": B_INCR, "enormously": B_INCR,
......
"thoroughly": B_INCR, "total": B_INCR, "totally": B_INCR, "tremendous": B_INCR, "tremendously": B_INCR,
"uber": B_INCR, "unbelievably": B_INCR, "unusually": B_INCR, "utter": B_INCR, "utterly": B_INCR,
"very": B_INCR,
"almost": B_DECR, "barely": B_DECR, "hardly": B_DECR, "just enough": B_DECR,
"kind of": B_DECR, "kinda": B_DECR, "kindof": B_DECR, "kind-of": B_DECR,
"less": B_DECR, "little": B_DECR, "marginal": B_DECR, "marginally": B_DECR,
"occasional": B_DECR, "occasionally": B_DECR, "partly": B_DECR,
"scarce": B_DECR, "scarcely": B_DECR, "slight": B_DECR, "slightly": B_DECR, "somewhat": B_DECR,
"sort of": B_DECR, "sorta": B_DECR, "sortof": B_DECR, "sort-of": B_DECR}
# 不再情感形容词词典中,但包含情感信息的俚语表达(目前英文方面也未完成)
SENTIMENT_LADEN_IDIOMS = {"cut the mustard": 2, "hand to mouth": -2,
"back handed": -2, "blow smoke": -2, "blowing smoke": -2,
"upper hand": 1, "break a leg": 2,
"cooking with gas": 2, "in the black": 2, "in the red": -2,
"on the ball": 2, "under the weather": -2}
# 包含词典单词的特殊情况俚语
SPECIAL_CASE_IDIOMS = {"the shit": 3, "the bomb": 3, "bad ass": 1.5, "badass": 1.5,
"yeah right": -2, "kiss of death": -1.5, "to die for": 3}然后还要将英文词典 vaderlexicon.txt改为对应格式的中文词典。vaderlexicon.txt格式
TOKEN, MEAN-SENTIMENT-RATING, STANDARD DEVIATION, and RAW-HUMAN-SENTIMENT-RATINGS引用信息
如果使用VADER词典、代码、或者分析方法发表学术文章,请注明出处,格式如下
Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.
Refactoring for Python 3 compatibility, improved modularity, and incorporation into [NLTK] ...many thanks to Ewan & Pierpaolo.推荐阅读
Handout库:能将python脚本转化为html展示文件
pandas_profiling:生成动态交互的数据探索报告
cufflinks: 让pandas拥有plotly的炫酷的动态可视化能力
使用Pandas、Jinja和WeasyPrint制作pdf报告














 2982
2982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









