







背景
我们在代码开发的过程中,由于各种各样的原因,难免存在代码质量或者代码安全的问题。这些问题有可能在生产环境中引发严重的事故从而造成业务上的损失。为了将风险降到最低,我们一般会在上线之前进行多梯次,多维度、多轮的测试来保障产品质量,使上线的产品功能达到一个比较理想的状态。
在这个过程中,我们的测试有代码的自动扫描,也有针对功能的单测和E2E(端到端)测试。下面就详细的介绍一下我建设的全链路质量保障体系
面临的问题
在做方案之前,先梳理一下面临哪些问题,然后针对这些特定的问题看看有没有什么解决方案,这些解决方案和现在公司内的技术生态聚合在一起能否形成一个完整的功能闭环。
梳理之后,总结遇到的问题如下所列:
- 代码质量差
- npm包依赖的问题
- 代码的安全问题
- 关键数据的依赖查询问题
- 标准统一与流程固定的问题
- 产品与组件的功能
- 页面性能问题
- 埋点与监控
代码质量差
主要体现在
- 代码中有很多重复的代码,没有很好的复用逻辑,沉淀一些可复用的组件
- 代码的复杂度标高,使用代码扫描检测工具可以发现代码的逻辑复杂度很高,有的文件中代码有好几千行
- 代码不规范,eslint的规则不统一
npm包依赖
我们知道项目中不可避免的需要引入各种各样的npm包,有时也会依赖公司内部封装的npm包。而包的使用者和包的维护者有时因为业务的复杂,公司的组织结构等原因,不能很好的做到信息同步。具体体现在以下两点:
- 包的提供者:不清楚自己的包会被那些团队中的哪些应用使用,如果更新版本或者hotfix不清楚需要通知到谁,只能无奈的在一个大群里面通知一下,但这种通知是不能定位到具体的人的,在流程上也没有很强的约束力。即有可能使用了这个包但因为群里信息“噪音”太大,导致这种关键性的消息被“淹没”了。又或者知道后又把这种“带伤”的npm包发布到线上去了
- 包的使用者:所使用的版本是否是有问题,并不清楚。什么时候发布了新的版本也不清楚,而且一些开源的
npm的质量可能有隐患但自己可能没有在社区关注。
代码的安全问题
在2023年网络安全问题已近被各个公司所重视,安全是一个很大的话题,包括网络安全、产品安全、前后端安全…这里具体到前端应用的安全我按照代码的分类将其分为两类
- 业务代码的安全:常见的比如
XSS、CSRF... - 项目依赖的安全:常见的比如
NPM、CDN依赖…
关键数据的查询
比如我们包的提供者需要知道自己的包在哪些应用中被使用,并且使用的版本是多少,各个版本的分布如何?
站在企业资产管理的视角也要统计出每个资产的负责人、发布的版本数量、等信息
站在测试的视角需要知道,如果某个公司内部的功能包或者是社区的npm包有问题的话,能否及时发现并阻断。就像java之前出现的log4j事件一样,或者前端antd的圣诞节事件一样,我们能否在几百甚至上千个前端应用中及时发现。并在现有的流程中设置质量门禁
标准统一与流程固定
公司的团队很多,以应用技术大约600+分散在各个部门中的各个产品团队中,这些应用的代码规范都不统一,并且在现有的流程中没有能力设置一个有效的“卡点”。
产品与组件功能
开发完之后,比较依赖测试的手工测试来发现问题,但发现很多测试的内容都是手工重复的,典型的就是一次迭代在开发、测试、release、预发、生产5个环境都需要测试至少2遍。那也就意味着一个功能在5个环境中验证2次,那至少也是10次的重复量了,其中有些比较复杂的模块以及测试发现问题的模块,就需要验证更多次数了,这些都是重复的工作
页面的性能
在早起2B相对2C可能没有那么重视性能,都是比较重视产品的稳定性,但随着产品的不断发展,用户对页面的性能诉求越来越高。所以就需要把页面的性能也提升
埋点与监控
之前的问题都可以在上线之前通过各种手段发现&修复,但有些问题在发布之前可能没有发现,此时就需要有线上的埋点和监控的手段来发现和定位
解决方案
上面梳理了我们面临的各种各样的问题,这些问题按照迭代流程的视角看:
开发时的问题(开发阶段)-> 测试时的问题(测试阶段,冒烟测试 + 集成测试 + 边界测试 + 压测…)-> 线上的问题(线上埋点与监控)
按照领域划分,有质量问题,有性能问题,也有流程和标准问题。我们先单点分析,看看针对上面的这特定的问题点有哪些针对性的解决方案。
从表面看我们面临的这些问题各种各样,有大有小,但我想这些问题至少反映出了我们两个问题
- 对内:我们的测试流程的不完善,就像上面提到的不仅是开发的标准与流程,在对内的测试流程也不完善,很多功能都是欠缺的
- 对外:不完善的流程日积月累之后自然会导致各种各样的产品问题,久而久之,这些问题都会通过各个现象(线上故障)暴露出来导致我们的产品稳定性不够
代码质量
对应的方案有:
- 从工程化角度统一脚手架,在脚手架中统一
eslint的规范和代码风格 - 进行代码的静态扫描,分析一些能反映出代码质量的指标,比如代码复杂度、代码规范、代码重复度、代码的npm依赖检查,而针对不同的扫描可以在不同的阶段进行检查,具体如下:
2.1CLI命令行检查:这是最贴近开发的一种扫描,比如eslint就可以在开发时就检测看看代码有没有符合规范,我们除了eslint之外,还在用户的终端启动服务时检测NPM的检测,看看项目的依赖是否有问题
2.2Gitlab流水线:对于一些任务比较重的指标,比如代码的复杂度,重复度,我们可以在代码提交时,自动的在Gitlab中建立流水线扫描,如果有问题再通知提交代码的开发,这个也是比较贴近开发的一种扫描方法,可以尽早的发现&修复发现的问题
2.3 发布时的扫描:不管公司大小,一般都会有一个发布系统,负责把我们开发完成的代码发布到各个环境中,我们可以在这个发布系统中进行检测,如果有问题就不能上线,做一个“卡点”的作用,这主要是给测试同学使用 UI自动化测试:如之前所说,在测试中很多功能都是重复的,我们可以使用Cypress编写自动化测试用例,来检测产品功能和组件
关于gitlab流水线也是从0到1建设起来的,主要分这几步骤:
- 注册
gitlab runner - 应用中使用
gitlab-ci.yml文件编写流水线 - 代码提交时,自动触发流水线扫描,将扫描的结果收集到
node服务中进行分析,如果有问题再推送给代码的提交者。
关于gitlab流水线,我专门写了一个专栏Gitlab 流水线专栏
发布时的扫描则是使用了jenkins集群来扫描的,前端的jenkins服务集群也是使用了node从0到1建设出这一套jenkins服务的,也写了一个关于建设jenkins的专栏jenkins建设
npm包依赖
主要分下面几步骤:
- 内部
npm:通过扫描公司内部nrm源仓库中的代码分析后可以拿到公司内发布的所有npm的名称以及版本 - 项目
yarn.lock:公司脚手架统一使用yarn,所以这里分析的是应用的yarn.lock文件(使用npm就分析package-lock.json)可以得到该应用的所有依赖图谱 - 开源
npm依赖:第二步得到的数据与第一步得到的数据做去除处理就能得到应用依赖的开源npm依赖 - 建立依赖风险管理库:如果发现内部
npm有问题登记之后,通过之前的扫描能定位到某个具体的应用是否使用了有问题的npm包的版本。如果是开源npm包有质量问题,在社区发现之后统一收集在风险管理库中,管理库主要有两方面作用
4.1. 扫描所有master(即线上代码)看看线上有哪些应用依赖了有问题的npm包,要及时的评估是否需要上hotfix
4.2. 在开发时的代码(开发中 + 测试中)的应用扫描看看有哪些应用依赖了有问题的npm包及时通知并在发布系统中设置卡点
代码的安全问题
根据代码的分析,我们在代码扫描时,分为代码扫描(针对业务代码的扫描)以及依赖扫描(正对NPM包的扫描)
关于代码扫描,我调研过虽然有一些开源的工具可以扫,但如果达到更好效果的话,还是需要商业化的代码扫描。
关于依赖扫描,我们可以使用npm audit来检测依赖,但因为源的问题,会导致速度比较慢,而且可能会失败,所以我们可以通过github上的开源漏洞通过open api来获取开源的漏洞,并与应用中的yarn.lock做比较来分析项目的依赖安全
关于怎么拉取漏洞数据可以参考node拉取Github开源漏洞
关键数据的查询
比较关键的数据有以下几点
- 发布者的npm的版本
- 使用者使用了那些npm依赖
- 发布者可以统计自己的npm的使用分布情况
- 测试也需要知道当前的应用依赖健康状况
- 公司视角也需要知道总体内部的二方库的数量,以及整体应用依赖了那些开源的npm包,便于后期做安全的评估
标准统一与流程固定
我们通过统一的脚手架,来统一各个应用中的eslint规则和代码风格。而上述的代码扫描以及UI自动化我们会和gitlab、测试团队的测试系统以及发布系统打通,数据互通有无,比如当前在开发阶段,在启动服务时,会通过CLI来检测npm包的依赖是否健康,在代码提交时,会自动建立gitlab流水线,来检测代码是否正常,在发布系统中点击“进入测试阶段”会自动调用前端的node扫描服务来进行扫描,然后返回一份检测报告给测试。让测试知道当前应用的质量状况
产品与组件功能
这部分主要是通过Cypess + Jenkins + Node来落地的端到端自动化测试来避免重复的手工测试
页面性能
这部分是通过lighthouse + node来实现页面性能检测功能,先制定出符合我们业务特点的性能模型然后在上线之前都进行性能检测,如果性能不达标就针对某个特定的指标来进行优化
详细的可以见我是怎么从0到1搭建性能门禁系统的
总结
我在年终给老板们汇报时画了这一张图来表示我们建设的全链路质量保障系统:
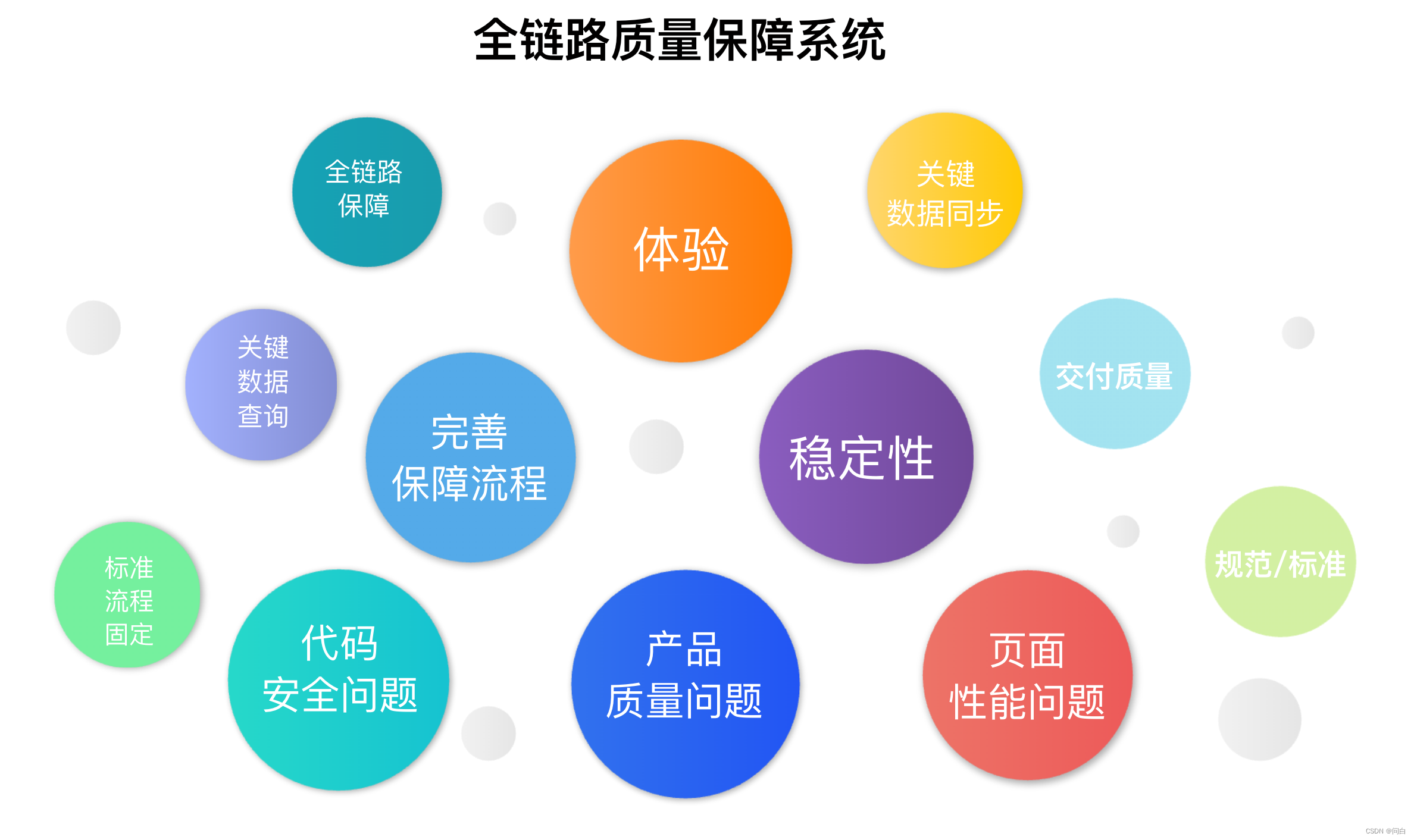
圈越大表示越重要,中间是一个三角形,下面的三个大问题分别是:安全、质量、性能问题需要解决。这三个问题如果能够得到解决或者是有效的控制,那就是一个三角形的底座,进而保障我们产品对外的稳定性,对内也表明我们现在的保障流程是有效的。再进一步也就提高了我们产品的整体体验
整个这一套方案按照也可以按照下面这样进行分层表示:
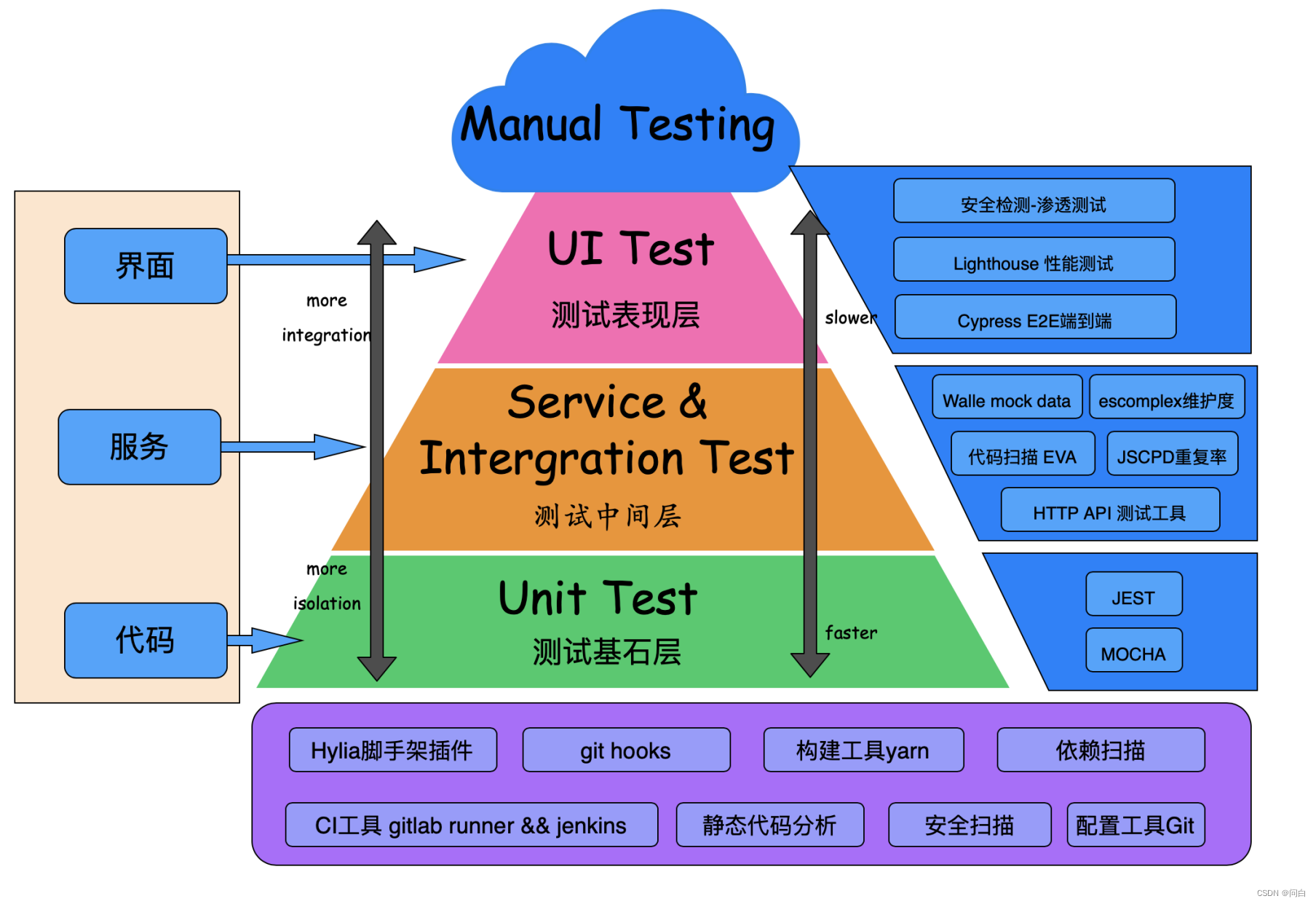
整体解决方案
何为“全链路”
通过上面的问题分析我们知道了各个具体的问题,以及针对每个特定问题的解决方案。
那这里为啥要称之为“全链路”呢?就像上面所说的一样,这些质量、安全、性能问题按照研发流程分类可能出现在任何一个流程中。
而我们要解决这些问题,也需要在全流程开发阶段(代码编写 + 代码提交 + 开发环境自测) + 测试(测试环境 + release环境 + pre环境) + 线上监控(线上)中的每个阶段去解决这些问题。
按照职能的视角看,各个职能不管是业务开发者视角还是基础模块提供者视角、还是测试、产品或者是团队的负责人都需要知道不同维度不同层面的质量数据。我们就需要在一个迭代中按照各个职能的不同来收集不同维度的数据,比如开发应该需要的是能精确到行的消息告警,而测试则是这一次提交的总体质量概览到了产品和负责人那边则是上线之后的整体质量趋势的表现
综上两个原因,我将其称之为“全链路”,其全景图如下:
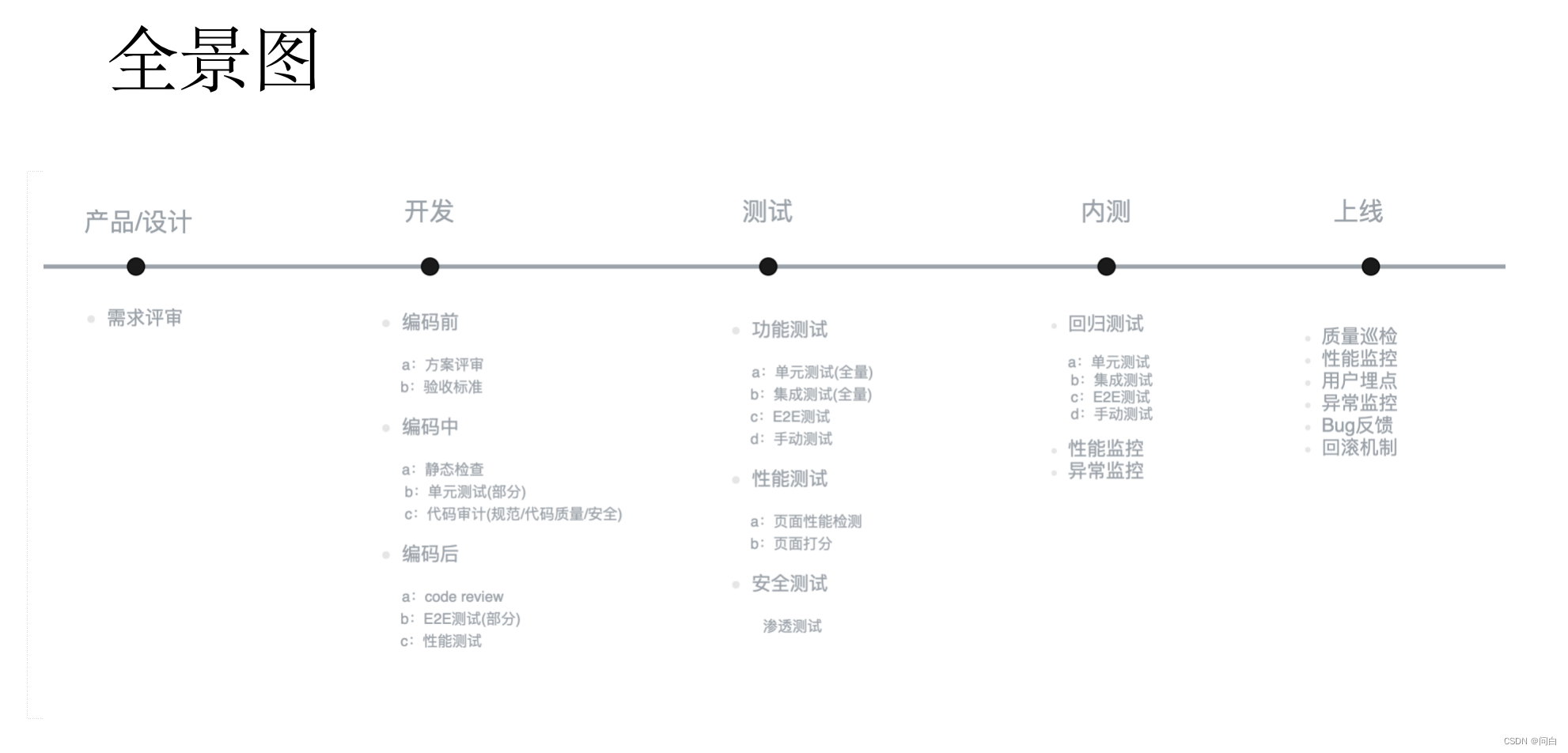
整体阶段划分
在“全链路”中我有将其分为三个阶段,每个阶段有每个阶段不同的策略:
- 事前以预防为主
- 事中以线上止血和线下设置卡点为主
- 事后以监控和巡检为主
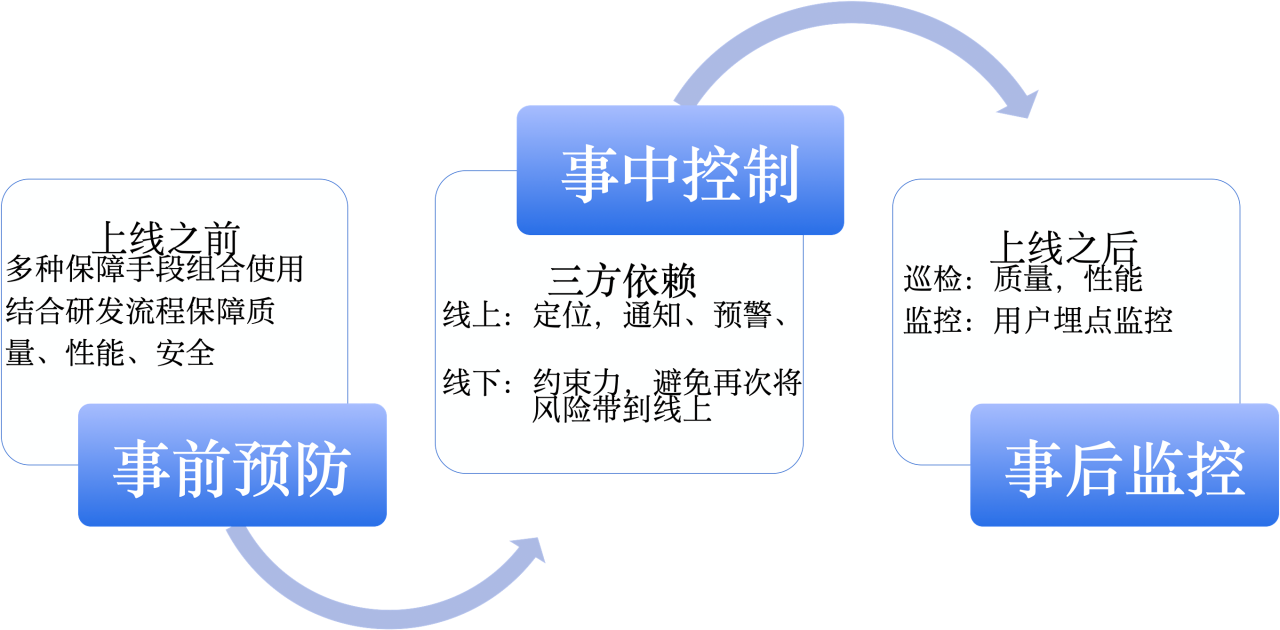
整体流程图
在实际落地中,我们结合了公司内的其他产品,典型的就是发布系统设置质量门禁来一起落地“全链路质量保障系统”,整体流程图如下所示:

整体技术架构图
产品中所用到的各个核心功能模块如下:
细节展示
有些数据比较敏感,就选择性的展示一些产品细节:
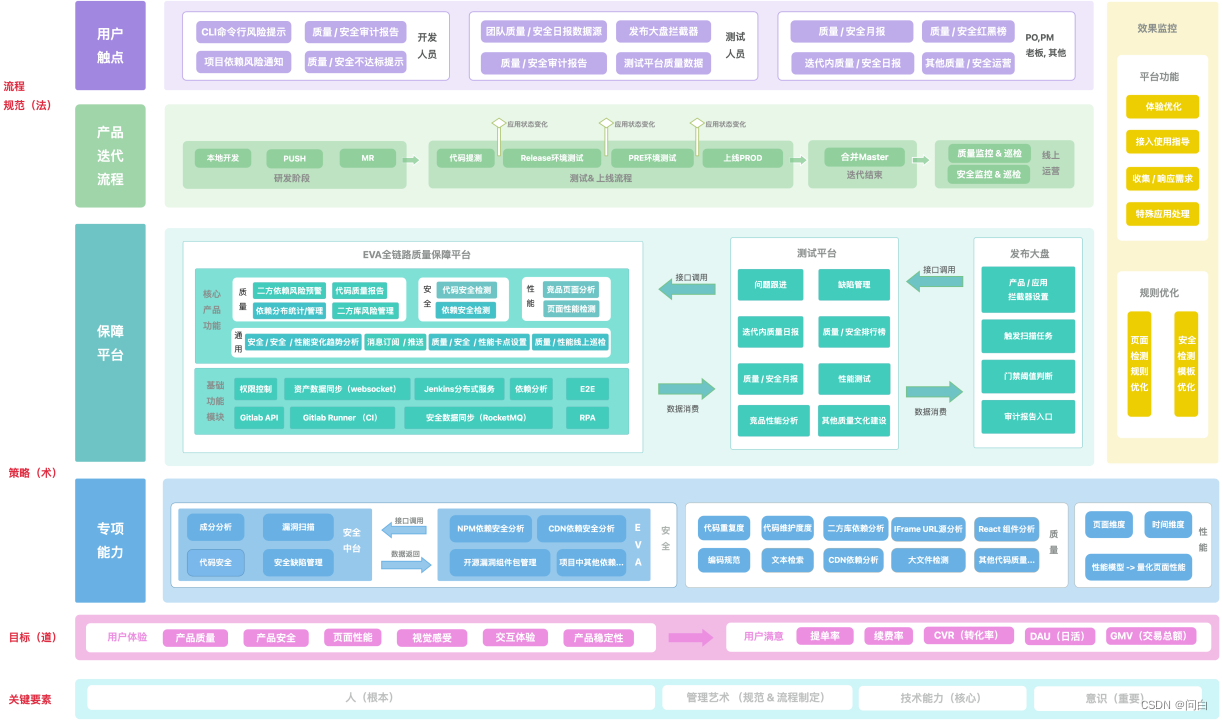
这是前端扫描系统分别在用户终端命令行中、gitlab流水线、发布系统jenkins构建时调用的扫描结果展示:

这是对eslint检测后的结果分析汇总之后展示出来的效果:
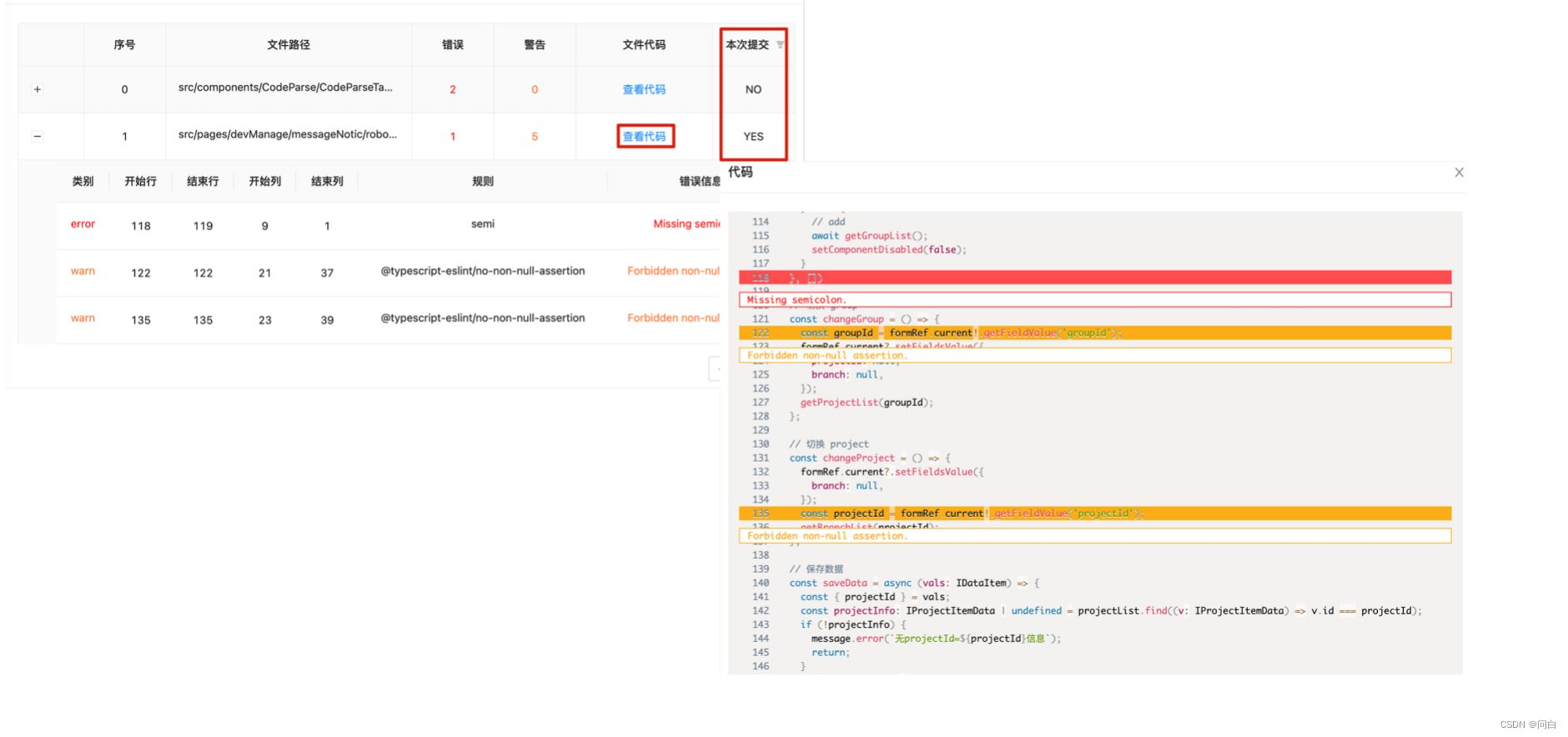
这是对应用的依赖分析之后的结果,表明了当前的应用依赖的npm的健康状况,在前期可以重点关注高风险的依赖,也可以针对性的设置一些卡点。

这是通过扫描之后得出的质量报告(部分),对于测试而言只需要看概览部分就可以了。而开发可以根据后面每一项指标的细节来定位到代码行

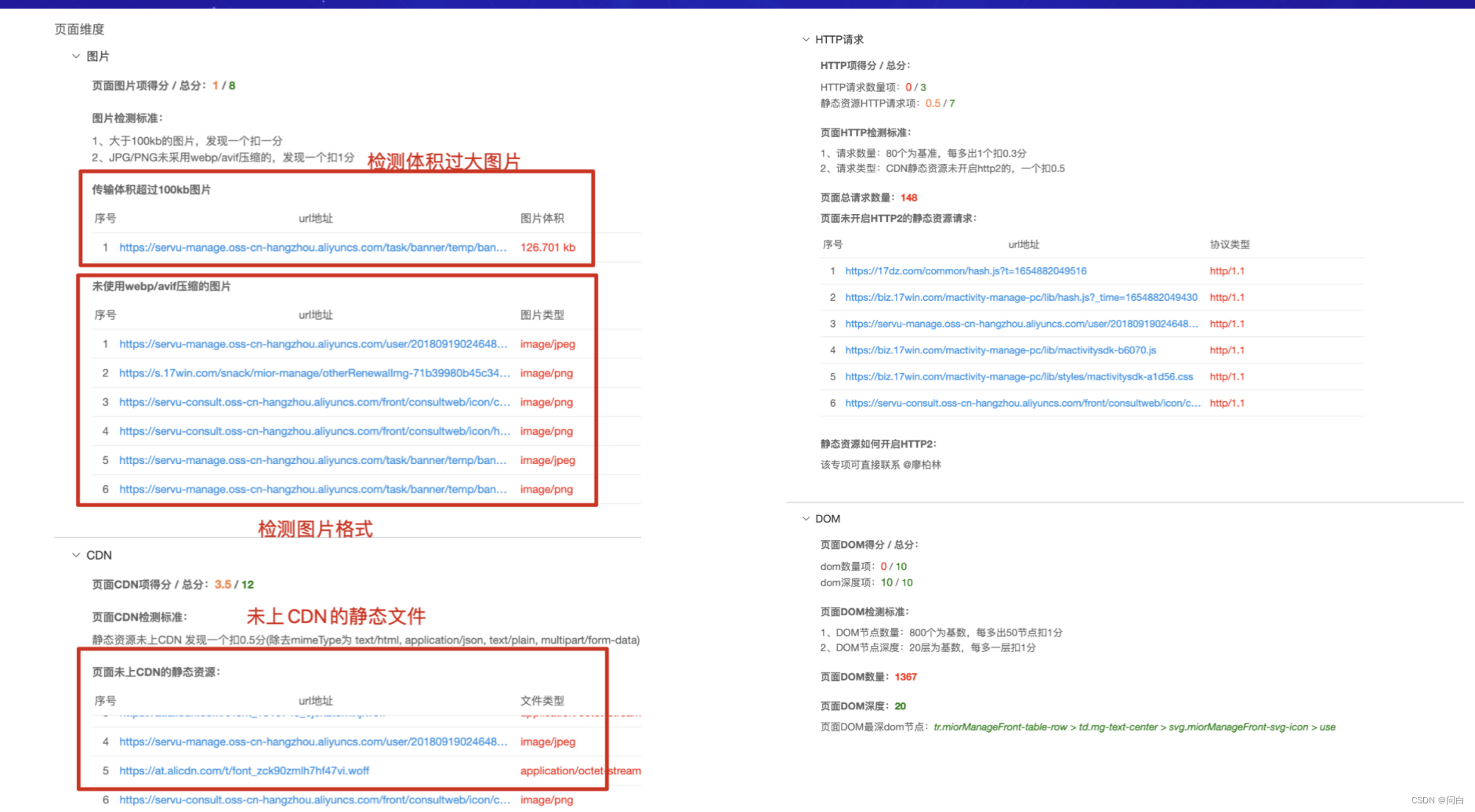
这是性能检测报告,我们可以在上线之前检测页面,看看上线的页面性能是否符合预期:

具体指标的详细分析:
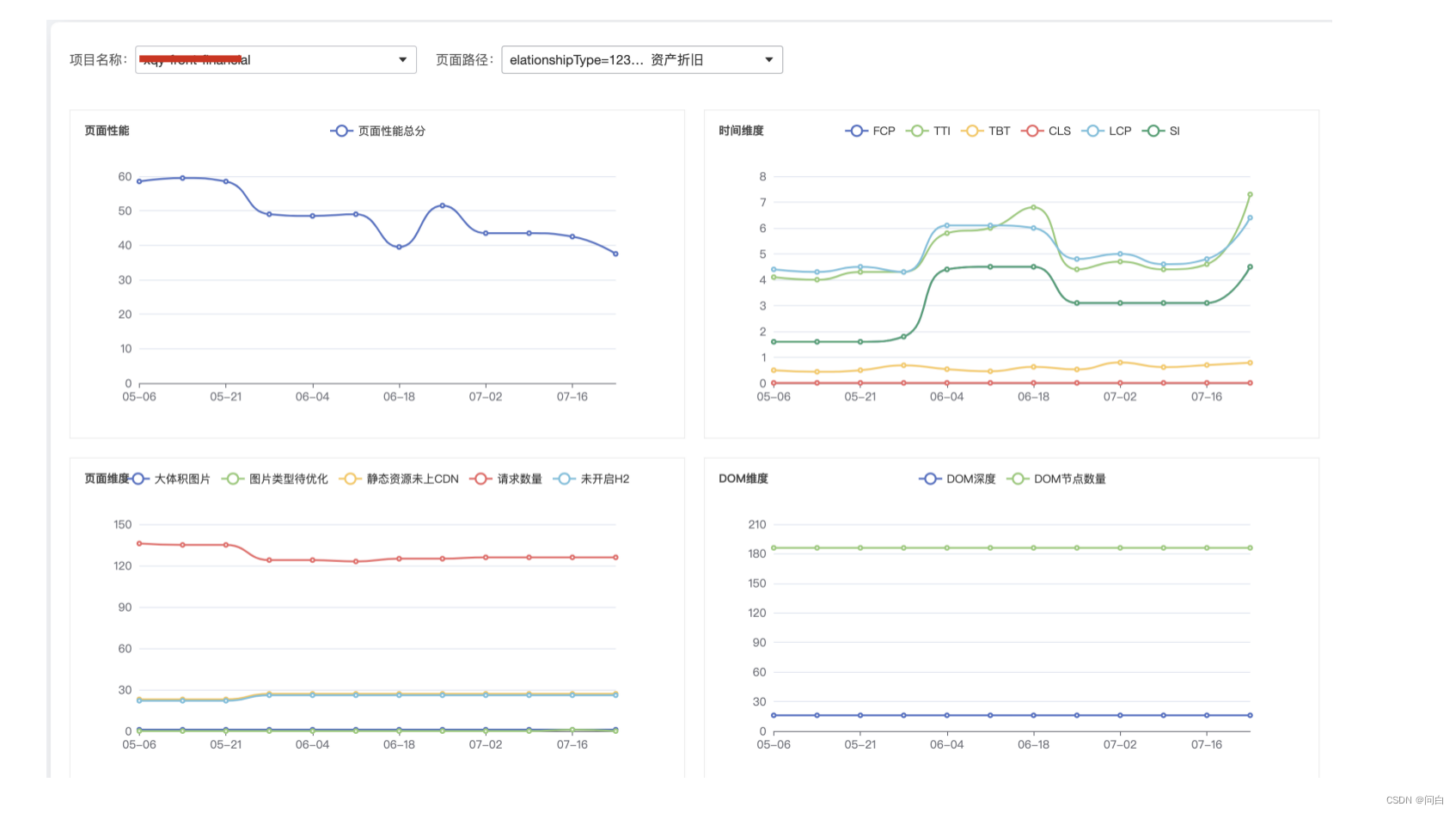
某个页面的性能趋势:
总结
目前所在的公司算是比较传统类型的公司,各个基础设置都比较欠缺,很多基建或者是基建的基建都需要自己去建设。对应的问题的方案也需要自己去思考落地,这相比于传统的“开发”角色无疑要难上很多,是一个 PM + 产品 + 前端开发 + 后端开发 + 运维 + 设计的多角色,但通过这一次的项目落地之后也的确极大的拓展了自己的综合能力
落地之后有一些结果数据比较敏感这里就不罗列了。


















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











