







接下来我们简单讲讲,Unicode 的原理,例如,Unicode 的设计思路,Unicode 和 UTF 的关系等。
简单的字符编码模型
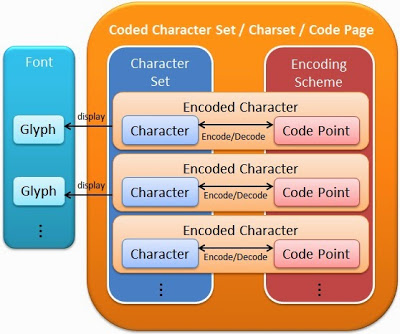
一个字符,在计算机中如何存储,是涉及到很多部分的。例如,一个字符集有多少个字符、如何编号和转成几个字节存储(也就是如何编码)等等,我们称这套机制为:字符编码模型(Character Encoding Model)。
前面我们说过 ASCII 这种简单字符集的编码思路:就是列出所有字符后,编号,然后编号的二进制数就是编码。即使是后面出现的 GB 系列编码,或者其他 ANSI 编码系列,其编码思路都是比较简单的。
换句话说,在传统的字符编码模型中,基本上都是将字符集里的字符进行编号(字符编号转化为二进制数后一般不超过一个字节),然后该字符编号就是字符的编码。字符集和字符编码可以认为是等价的,并不需要进行严格区分。示意图:
Unicode 的设计思路
Unicode 等现代字符编码模型,并没有采用 ANSI 这种简单字符集的思路,采用了一个全新的思路。这个思路讲字符集和字符编码的概念,细致的分解为如下几个方面:
- 一套字符集有什么字符
- 这些字符的编号是什么
- 这些编号的规则
- 这些编号如何转为字节序列
- 在某些特殊的传输环境中(例如 Email),如何将字节序列进行适应性编码处理
现代字符编码模型之所以要分解为这么几个方面,其核心思想是创建一个能够用不同方式来编码的通用字符集。
这意味着,同一个字符集,可以通用于不同的编码方式;也就是说,可以采用不同的编码方式来对同一个字符集进行编码。字符集与编码方式之间的关系可以是一对多的关系(而 ANSI 的字符集中,字符集和编码方式是唯一的)
更进一步而言,在传统字符编码模型中,字符编码方式与字符集是紧密结合在一起的;
而在现代字符编码模型中,字符编码方式与字符集脱钩了。用软件工程的专业术语来说,就是将之前紧密耦合在一起的字符编码方式与字符集解耦了。
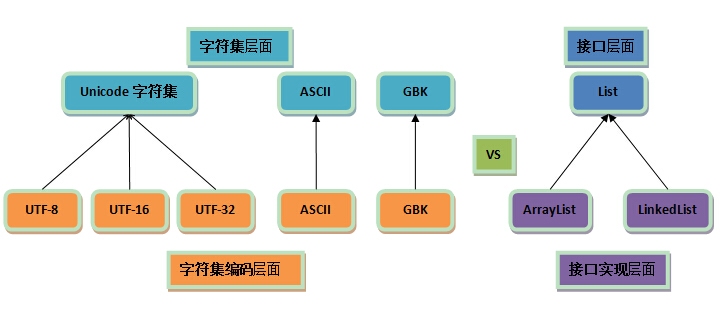
可以把字符集和编码,跟接口及接口实现做个对比:
从这里可以很清楚地看到:
- 编码是依赖于字符集的,就像代码中的接口实现依赖于接口一样
- 一个字符集可以有多个编码实现,就像一个接口可以有多个实现类一样
现代字符编码模型
在 Unicode Technical Report (UTR 统一码技术报告)《UNICODE CHARACTER ENCODING MODEL》中,现代字符编码模型分为了五个层次,我们这里做个简单的介绍:
- 第 1 层 抽象字符表 ACR(Abstract Character Repertoire 抽象字符清单):明确字符的范围,即确定支持哪些字符,可以简单理解为无序的字符集合。
- 第 2 层 编号字符集 CCS(Coded Character Set):用数字给抽象字符表 ACR 中的字符进行编号。
- 第 3 层 字符编码方式 CEF(Character Encoding Form 字符编码形式、字符编码格式、字符编码规则):这一层主要是决定用几个字节存储字符,也就是如何将数字编号转为二进制。在之前简单的字符编码模型中,直接将数字编号转为二进制,UTF8 等就属于这一层;但这样有缺点,我们后续展开。
- 第 4 层 字符编码模式 CES(Character Encoding Scheme):可以简单理解为如何将多个字节存储到计算机中。因为我们用了多个字节,计算机如何知道几个字节代表一个字符呢?各个字符之间如何分隔、各个字节之间的先后顺序怎么定。
- 第 5 层 传输编码语法 TES(Transfer Encoding Syntax):将字节序列作进一步的适应性编码处理。例如,在网络中的一些协议如何传输、如何压缩等等。
补充知识点:
-
对于第一层来说,字符表可以是封闭的(即字符范围是固定的),即除非创建一个新的标准,否则不允许添加新的字符,比如 ASCII 字符表和 ISO/IEC 8859 系列都是这样的例子;
字符表也可以是开放的(即字符范围是不固定的),即允许不断添加新的字符,比如 Unicode 字符表,目前有很多字符源源不断的加进来。
-
对于第二层来说,举个例子,汉字“严”的 Unicode 是十六进制数 4E25,转换成二进制数足足有 15 位(0100 1110 0010 0101),也就是说这个符号的表示至少需要 2 个字节。表示其他更大的符号,可能需要 3 个字节或者 4 个字节,甚至更多。
-
对于第三层来说,汉字“严” 到底是用几个字节来存储呢?
-
对于第四层,汉字“严”的字节应该怎么排序?大端还是小端?字符之间如何分隔开?计算机如何知道 3 个字节表示一个字符,而不是 1 个,4 个字节表示一个字符?
-
如果要在网络中传输汉字“严”(例如 email),这么多个字节怎么传送、怎么压缩等,就是属于 TES 层
如果读者不清楚大端和小端的概念,请先看看阮一峰老师的博客:字节序探析:大端与小端的比较 - 阮一峰的网络日志,讲的非常透彻。
Unicode 的编码方案
前面我们说过,在现代字符编码模型中,可以采用不同的编码方式来对同一个字符集进行编码。而 Unicode 就有多种编码方式,称为 UTF,全称 Unicode Transformation Formats。
UTF 系列编码方案有 UTF-8、UTF-16、UTF-32,均是由 Unicode 编码方案衍变而来,以适应不同的数据存储或传递(例如有的要用 2 字节存储,有的要用 3 字节存储,有的则要 4 字节存储,此外还有大端小端的区别)。
换句话说,UTF8,UTF16 和 UTF32 都是 Unicode 的实现,可以理解为将某个具体的 Unicode 字符,转为具体的某种格式(例如 3 个字节存储的格式,4 个字节存储的格式)
例如汉字“严”的 Unicode 是十六进制数 4E25, 在各种编码方式下的编码方案为:
| 编码 | hex | dec (bytes) | dec | binary |
|---|---|---|---|---|
| UTF-8 | E4 B8 A5 | 228 184 165 | 14989477 | 11100100 10111000 10100101 |
| UTF-16BE | 4E 25 | 78 37 | 20005 | 01001110 00100101 |
| UTF-16LE | 25 4E | 37 78 | 9550 | 00100101 01001110 |
| UTF-32BE | 00 00 4E 25 | 0 0 78 37 | 20005 | 00000000 00000000 01001110 00100101 |
| UTF-32LE | 25 4E 00 00 | 37 78 0 0 | 625868800 | 00100101 01001110 00000000 00000000 |
以上编码方式参考:严 - 中日韩象形文字: U+4E25 - Unicode 字符百科
补充:
- 在 Unicode 标准中,码点采用了十六进制书写,并加上前缀 U+,例如 U+0041 就是拉丁字母 A 的码点。
- 码点(Code Point)在 Unicode 字符集中,每个字符映射成一个数字,这个数字被称为相应字符的码点。例如“严”字在 Unicode 中对应的码点是 U+0x4E25。
- 码元(Code Unit)是指一个已编码的文本中具有最短的比特组合的单元。对于 UTF-8 来说,码元是 8 比特长;对于 UTF-16 来说,码元是 16 比特长。换一种说法就是 UTF-8 的是以一个字节为最小单位的,UTF-16 是以两个字节为最小单位的。
- UTF-16BE 指的是大端序,UTF-16LE 指的是小端序,后续的 UTF32 同理
下面我们简单介绍下 UTF32 和 UTF8
UTF-32
在本系列第一篇文章我们说过,UCS-4 字符集使用 4 个字节存储一个字符。
UTF-32 是最好理解的一个了,其编码始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换,提高了效率,固定的长度也能让计算机知道每个字符的截断范围,但浪费了空间。
UTF-8
在 1992 年,UTF8 编码出现了,针对不同字符,其可以用不同的字节数来存储,解决了存储空间浪费的问题。
UTF8 则灵活的多,根据需要来决定使用多少个字节来存储字符,节省了很多空间。
UTF-8 的编码规则很简单,只有 2 个:
- 对于一个字节就能存储的符号,和 ASCII 的符号表一样(字节的第一位是 0,后面 7 位为这个符号的 Unicode 码)
- 对于需要多字节存储的符号,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
举个莉子:
- 0xxxxxxx:单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的;
- 110xxxxx 10xxxxxx:双字节编码形式(第一个字节有两个连续的 1);
- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(第一个字节有三个连续的 1);
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(第一个字节有四个连续的 1)
这里的 x 就是对应 Unicode 码点的二进制,如果一个字符的 Unicode 码点可以用 2 个字节存储,那么就会用第 2 种方式编码;如果要用 3 个字节,那么就用第 3 种方式编码。
由此我们可以得到下表:
| 十进制 | Unicode 符号范围(十六进制) | UTF-8 编码方式(二进制) |
|---|---|---|
| 0-127 | 0000 0000-0000 007F | 0xxx xxxx |
| 128-2047 | 0000 0080-0000 07FF | 110x xxxx 10xx xxxx |
| 2048-65535 | 0000 0800-0000 FFFF | 1110 xxxx 10xx xxxx 10xx xxxx |
| 65536-1114111 | 0001 0000-0010 FFFF | 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx |
那么一个 Unicode 符号如何转为 UTF8 呢?步骤如下:
- 首先将 16 进制的码点,通过进制转换为十进制
- 然后使用十进制的数字查找上述表格处于哪个范围中,得出编码规则
- 然后将码点转换为 2 进制,从低位到高位替换 x 即可得到字二进制的原码
- 将二进制的原码转换为补码存储
举个例子,汉字“严”的 Unicode 是十六进制数 4E25,十进制为 20005,也就是上表的第 3 行,需要 3 个字节,二进制数为(0100 1110 0010 0101)。
我们分别将这 15 个二进制,填充到 1110 xxxx 10xx xxxx 10xx xxxx 中的 x 中(不足的补 0),得到的结果:
1110 xxxx 10xx xxxx 10xx xxxx
0100 11 1000 10 0101
1110 0100 1011 1000 1010 0101
对三个字节分别求补码(计算机中以补码存储),得到:
原码:11100100 10111000 10100101
取反:00011011 01000111 01011010
加一:00011100 01001000 01011011
这几个分别是-28,-72,-91 的补码。
我们在 Java 中验证下:
byte[] b2 = "严".getBytes("utf-8");
for (int i = 0; i < b2.length; i++) {
System.out.println(b2[i]);
}
输出了-28,-72,-91。
我们可以顺便打印下其二进制:
byte[] b2 = "严".getBytes("utf-8");
for (int i = 0; i < b2.length; i++) {
System.out.print(b2[i]);
System.out.print(" ");
System.out.println(Integer.toBinaryString(b2[i]));
}
运行结果:
-28 11111111111111111111111111100100
-72 11111111111111111111111110111000
-91 11111111111111111111111110100101
GBK 同理。“赵”的 GBK 码点为:D5D4 ,转换为二进制:11010101 11010100
原码:11010101 11010100
补码:10101011 10101100
补码对应的字节数组为:{-43,-44},可用代码验证:
byte[] b3 = "赵".getBytes();
for (int i = 0; i < b3.length; i++) {
System.out.println(b3[i]);
}
UTF 编码系列小结
我们简单总结下 UTF 编码系列:
- UTF - 8 (变长字节,可以用 1~4 个字节来存储一个字符)
- UTF - 32(固定使用 4 个字节)
- UTF - 16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变
UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
一般来说,Unicode 编码之间可以相互转换,例如 UTF8 可以转换为 UTF16.
在计算机内存中,统一使用 Unicode 编码,当需要保存到硬盘或者需要传输的时候,就转换为 UTF-8 编码。用记事本编辑的时候,从文件读取的 UTF-8 字符被转换为 Unicode 字符到内存里,编辑完成后,保存的时候再把 Unicode 转换为 UTF-8 保存到文件。
查询 Unicode 编码
如果我们想知道某个字符的 Unicode 编码,怎么查呢?
可以去官网查询:Unicode – The World Standard for Text and Emoji
如果是汉字,可以去看专门的汉字对应表:字体编辑用中日韩汉字 Unicode 编码表 - 编著:资深中韩翻译金圣镇 金圣镇
还有很多其他的网站提供查询,例如:基本拉丁字母 — ✔️ ❤️ ★ Unicode 字符百科
编程语言与 Unicode
很多语言都有查询 Unicode 字符码点的内置函数。
例如 Python 的 ord 函数:
C:\Users\peterjxl>Python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> ord("严")
20005
ps:汉字“严”的 Unicode 是十六进制数 4E25, 其十进制就是 20005
JS 的 codePointAt 函数(读者可以打开浏览器控制台里输入):
"严".codePointAt()
20005
对于 Java 来说,以下结果输出:20005
public class TestUnicode {
public static void main(String[] args) {
String str = "严";
System.out.println(str.codePointAt(0));
}
}
Unicode 转字符
知道一个字符的 Unicode 码点,能否知道其对应什么字符呢?可以的。例如 Java,直接打印即可:
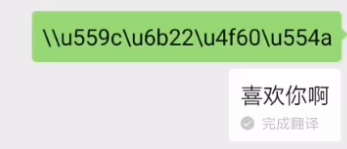
str = "\u4E25";
System.out.println(str); //输出严
其他语言同理,这里不一一演示了。
微信自带的翻译功能,也支持将 Unicode 码点转为字符,只需发送一段文字,然后右键翻译即可。如果不行,多翻译几次。
关于 Emoji
表情包,可以说是社交的灵魂。
2010 年,Emoji 也被纳入 Unicode。什么是Emoji ?就是一些小巧的表情包 🙃:
相信大家在各种社交媒体上都遇到过,例如微信,Twitter 等,基本上都内置了 Emoji。B 站也不例外:
截图来自 爷真可爱 💗_哔哩哔哩
除了社交媒体 APP 上自带的 Emoji,在邮箱、word 文档里,我们能否快速输入表情包呢?可以 ,请读者参考我的另一篇博客:输入法的技巧
小结
至此,我们对字符、字符集与字符编码的概念进行小结:
- 字符(Charcter)是文字与符号的总称,包括文字、图形符号、数学符号等。26 个英文字母属于字符,每个汉字也属于一个字符。
- 字符集是一组抽象的字符(Charcter)组合的集合。举一个例子,所有的汉字就算一个“字符集合”, 所有的英语字母也算一个“字符集合”。 注意,我这里说它们是字符集合,而且还有双引号。是因为字符集并不简单的是字符的集合, 准确概述来说,字符集是一套符号和编码的规则。 字符集需要以某种字符编码方式来表示、存储字符。我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有 0 和 1 两种状态。而如果用不同的 0 和 1 组合表示不同的字符就是编码。
- 关于字符编码,我们知道字符最终是以二进制形式存储在磁盘的,这也是为什么要有字符编码的原因,因为计算机最终都要以二进制形式存储,那么编码规则就是用什么样的二进制来代表这个字符。例如,我们所熟知的 ASCII 码表中,01000011 这个二进制对应的十进制是 67,它代表的就是英语字母 C。准确概述来说,字符编码方式是用一个或多个字节的二进制形式表示字符集中的一个字符。每种字符集都有自己特有的编码方式,因此同一个字符,在不同字符集的编码方式下,可能会产生不同的二进制形式。
另外,字符集合只是指定了一个集合中有哪些字符,而字符编码,是为这个集合中所有字符定义相关编号,而字符集(注意与字符集合的区别)是字符和集合与编码规则的混合体,这也是有时候编码方案代表字符集的原因。
相关代码
相关代码已上传到 Gitee:https://gitee.com/peterjxl/LearnJava/tree/master/src/01.JavaSE/05.OOP/15.character


















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











