







epoll 是一种多路复用技术。多路复用技术即一个线程可以监听多个文件句柄的的事件,多路指的是多个句柄,复用是指多个句柄复用一个线程资源。可想而知,和多路复用技术相对的就是一个文件句柄使用一个线程来监听。多路复用技术适用于高并发的场景。除了 epoll, linux 中的多路复用技术还有 poll 和 select。
nginx, libevent, golang net 库中均使用了 epoll。
本文首先通过一个简单例子来了解 epoll 基本使用方法,然后介绍了 epoll 中使用的主要数据结构,最后重点记录了 6 个问题,通过这 6 个问题全面而深入地理解 epoll。
1 epoll 使用方式
1.1 三个系统调用
通过以下 3 个 api 使用 epoll。
epoll 通过这 3 个 api 把控制面和数据面进行了隔离, epoll_cerate() 和 epoll_ctl() 完成控制面的工作,epoll_wait() 完成数据面的工作。控制面的工作包括 epoll 的创建,向 epoll 中增加 fd 或者从 epoll 中删除 fd,修改监听事件;数据面的工作包括从内核中获取事件,完成数据的读写。
| epoll_create() | ① 创建一个 epoll 对象,在内核会创建一个 eventpoll。 ② 返回的是一个 fd(文件描述符),该 fd 代表内核态的一个 eventpoll 对象,后边 epoll_ctl(), epoll_wait() 都是基于这个 fd 进行操作; 用 fd 表示内核态的 epoll 对象,体现了 linux 一切皆文件的思想。 |
| epoll_ctl() | 这个 api 通过三个命令字完成控制操作: ① EPOLL_CTL_ADD 往 epoll 对象增加一个 fd,fd 加到 epoll 里边之后,epoll 才会对这个 fd 上的事件进行监听。 ② EPOLL_CTL_DEL 语义与 EPOLL_CTL_ADD 相反 ③ EPOLL_CTL_MOD 修改已经加入到 epoll 里边的 fd 需要监听的事件类型。 |
| epoll_wait() | 从内核获取事件。 |
1.2 测试代码
测试步骤:
① 如果服务端和客户端不在一台机器,需要将 epoll_client.c 中的 SERVER_IP 修改为服务端机器的 ip 地址;
② 编译
gcc epoll_server.c -o server
gcc epoll_client.c -o client
③ 先后启动 server 和 client,便可以看到两端有数据收发。
server 端代码(epoll_server.c):
#include <arpa/inet.h>
#include <errno.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <string.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#define SERVER_IP ("0.0.0.0") // 0.0.0.0 all local ip
#define SERVER_PORT (12345)
#define MAX_LISTENQ (32)
#define MAX_EVENT (128)
#define MAX_BUFSIZE (512)
int create_tcp_server() {
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (listen_fd < 0) {
printf("create socket error: %s\n", strerror(errno));
return -1;
}
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = inet_addr(SERVER_IP);
server_addr.sin_port = htons(SERVER_PORT);
if (bind(listen_fd, (struct sockaddr *)&server_addr, sizeof(server_addr)) < 0) {
printf("bind[%s:%d] error.\n", SERVER_IP, SERVER_PORT);
return -1;
}
if (listen(listen_fd, MAX_LISTENQ) < 0) {
printf("listen error.\n");
return -1;
}
return listen_fd;
}
int main() {
int ret = -1;
int sock_fd = -1;
int accetp_fd = -1;
int event_num = -1;
int epoll_fd = -1;
int listen_fd = -1;
struct sockaddr_in client_addr;
struct sockaddr_in server_addr;
socklen_t client = sizeof(struct sockaddr_in);
struct epoll_event ev;
struct epoll_event events[MAX_EVENT];
listen_fd = create_tcp_server();
if (listen_fd < 0) {
printf("create server error\n");
return -1;
}
epoll_fd = epoll_create(MAX_EVENT);
if (epoll_fd <= 0) {
printf("cteare epoll failed, error: %s\n", strerror(errno));
return -1;
}
ev.data.fd = listen_fd;
ev.events = EPOLLIN;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &ev) < 0) {
printf("add listen fd to epoll error.\n");
return -1;
}
char buff[MAX_BUFSIZE] = {'\0'};
for (;;) {
printf("epoll wait:\n");
event_num = epoll_wait(epoll_fd, events, MAX_EVENT, -1);
printf("events num:%d\n", event_num);
for (int i = 0; i < event_num; i++) {
if (events[i].events & EPOLLIN == 0) {
printf("fd %d error, cloase it, event[0x%x].\n", events[i].data.fd, events[i].events);
close(events[i].data.fd);
return -1;
}
if (events[i].data.fd == listen_fd) {
accetp_fd = accept(listen_fd, (struct sockaddr *)&client_addr, &client);
printf("accepted fd: %d\n", accetp_fd);
if (accetp_fd < 0) {
printf("accept error.\n");
return -1;
}
ev.data.fd = accetp_fd;
ev.events = EPOLLIN;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, accetp_fd, &ev) < 0) {
printf("add fd to epoll error.\n");
return -1;
}
} else {
ret = recv(accetp_fd, buff, MAX_BUFSIZE, 0);
if (ret <= 0) {
printf("recv error. %s\n", strerror(errno));
epoll_ctl(epoll_fd, EPOLL_CTL_DEL, accetp_fd, &ev);
close(accetp_fd);
events[i].data.fd = -1;
return -1;
}
buff[ret] = '\0';
printf("**recv data: %s\n", buff);
send(accetp_fd, buff, strlen(buff), 0);
}
}
}
return 0;
}client 端代码(epoll_client.c):
#include <arpa/inet.h>
#include <errno.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <unistd.h>
#define SERVER_PORT (12345)
#define SERVER_IP "127.0.0.1"
#define MAX_EVENT (128)
#define MAX_BUFSIZE (512)
int main(int argc, char *argv[]) {
int sock_fd = socket(AF_INET, SOCK_STREAM, 0);
if (sock_fd < 0) {
printf("create socket error.\n");
return -1;
}
struct sockaddr_in addr_serv;
memset(&addr_serv, 0, sizeof(addr_serv));
addr_serv.sin_family = AF_INET;
addr_serv.sin_port = htons(SERVER_PORT);
addr_serv.sin_addr.s_addr = inet_addr(SERVER_IP);
if (connect(sock_fd, (struct sockaddr *)&addr_serv, sizeof(struct sockaddr)) < 0) {
printf("connect error.\n");
return -1;
}
int epoll_fd;
struct epoll_event ev;
struct epoll_event events[MAX_EVENT];
epoll_fd = epoll_create(MAX_EVENT);
if (epoll_fd <= 0) {
printf("create epoll error.\n");
return 0;
}
ev.data.fd = sock_fd;
ev.events = EPOLLIN;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sock_fd, &ev) < 0) {
printf("add fd to epoll error.\n");
return -1;
}
int recv_num;
char send_buff[] = "epoll test!";
char recv_buff[MAX_BUFSIZE];
send(sock_fd, send_buff, strlen(send_buff), 0);
for (;;) {
printf("epoll wait:\n");
int event_num = epoll_wait(epoll_fd, events, MAX_EVENT, -1);
printf("epoll events num:%d\n", event_num);
for (int i = 0; i < event_num; i++) {
if (events[i].events & EPOLLIN == 0) {
printf("fd %d error, cloase it, event[0x%x].\n", events[i].data.fd, events[i].events);
close(events[i].data.fd);
return -1;
}
recv_num = recv(sock_fd, recv_buff, sizeof(recv_buff), 0);
if (recv_num < 0) {
printf("recv error\n");
return -1;
}
recv_buff[recv_num] = '\0';
printf("**recv data: %s\n", recv_buff);
send(sock_fd, send_buff, strlen(send_buff), 0);
}
}
close(sock_fd);
return 0;
}2 epoll 内核数据结构
介绍两个数据结构,struct eventpoll 和 struct epitem。
前者在内核中代表一个 epoll;后者在内核中表示一个 epoll 监听的对象,比如一个 tcp 的 socket。在 c 语言中常常用结构体来表示一个对象,结构体中可以定义对象的属性,还可以定义函数指针表示对象的方法。
2.1 eventpoll
eventpoll 是一个结构体, 代表整个 epoll 对象,epoll_create() 的时候会创建一个 struct eventpoll,并对结构体的成员进行初始化。
为了便于理解,下边只展示了 5 个成员,重点需要理解的是 rbr 和 rdllist。
struct eventpoll {
/* Wait queue used by sys_epoll_wait() */
wait_queue_head_t wq;
/* Wait queue used by file->poll() */
wait_queue_head_t poll_wait;
/* List of ready file descriptors */
struct list_head rdllist;
/* RB tree root used to store monitored fd structs */
struct rb_root_cached rbr;
/*
* This is a single linked list that chains all the "struct epitem" that
* happened while transferring ready events to userspace w/out
* holding ->lock.
*/
struct epitem *ovflist;
};下面分别对这 5 个成员进行介绍:
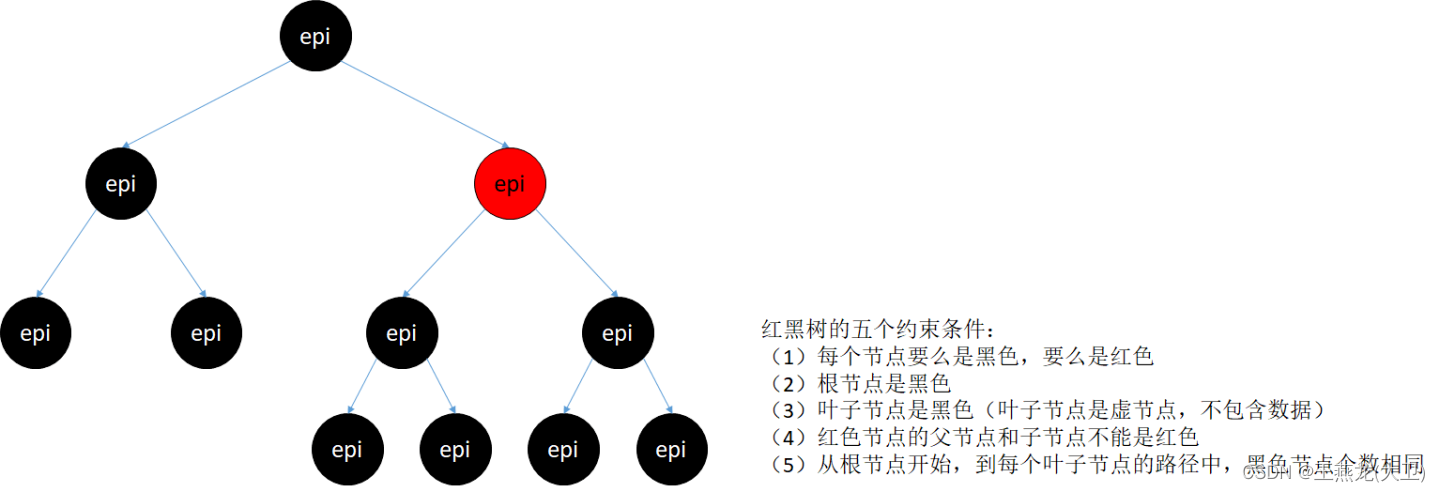
(1)rbr
rbr 是红黑树,保存着所有需要 epoll 监听的 fd 信息。红黑树中的每个节点是一个 epitem,epitem 代表着一个fd。
红黑树同时也是二叉搜索树,需要对节点进行排序,每个节点都有一个 key 用于在红黑树中进行排序。eventpoll 的红黑树节点的 key 是文件描述符在内核中对应的 file 结构体的地址。
static inline int ep_cmp_ffd(struct epoll_filefd *p1,
struct epoll_filefd *p2)
{
return (p1->file > p2->file ? +1:
(p1->file < p2->file ? -1 : p1->fd - p2->fd));
}epoll 中通过 ep_insert(), ep_remove, ep_modify(), ep_find() 完成红黑树的增删改查操作。
红黑树在增,删,改,查操作的时间复杂度之间取得了一定的平衡。linux 内核在多处使用了红黑树,tcp 接收侧维护了一个乱序队列,用来缓存乱序的报文,直到报文连续之后才会将连续的报文上报给应用,其中的乱序队列使用红黑树来实现;tcp 发送侧有一个重传队列,也是使用红黑树来维护;linux 调度策略 SCHED_NORMAL 和 SCHED_DEADLINE 的调度队列也是使用红黑树来实现。
(2)rdllist 就绪队列
就绪队列可以看做 epoll 中事件流转的中枢,当一个 fd 上有事件,epoll 便会将该 fd 对应的 epitem 加入到就绪队列中。
就绪队列是一个双向循环链表,使用内核的 struct list_head 实现。
生产者:底层协议栈,底层协议栈如果有事件(读,写,错误),会通过 sock_def_readable() 等函数将对应的 epitem 添加到 rdllist 里边。
消费者:用户态调用 epoll_wait() ,epoll_wait() 会从这个链表中消费事件。
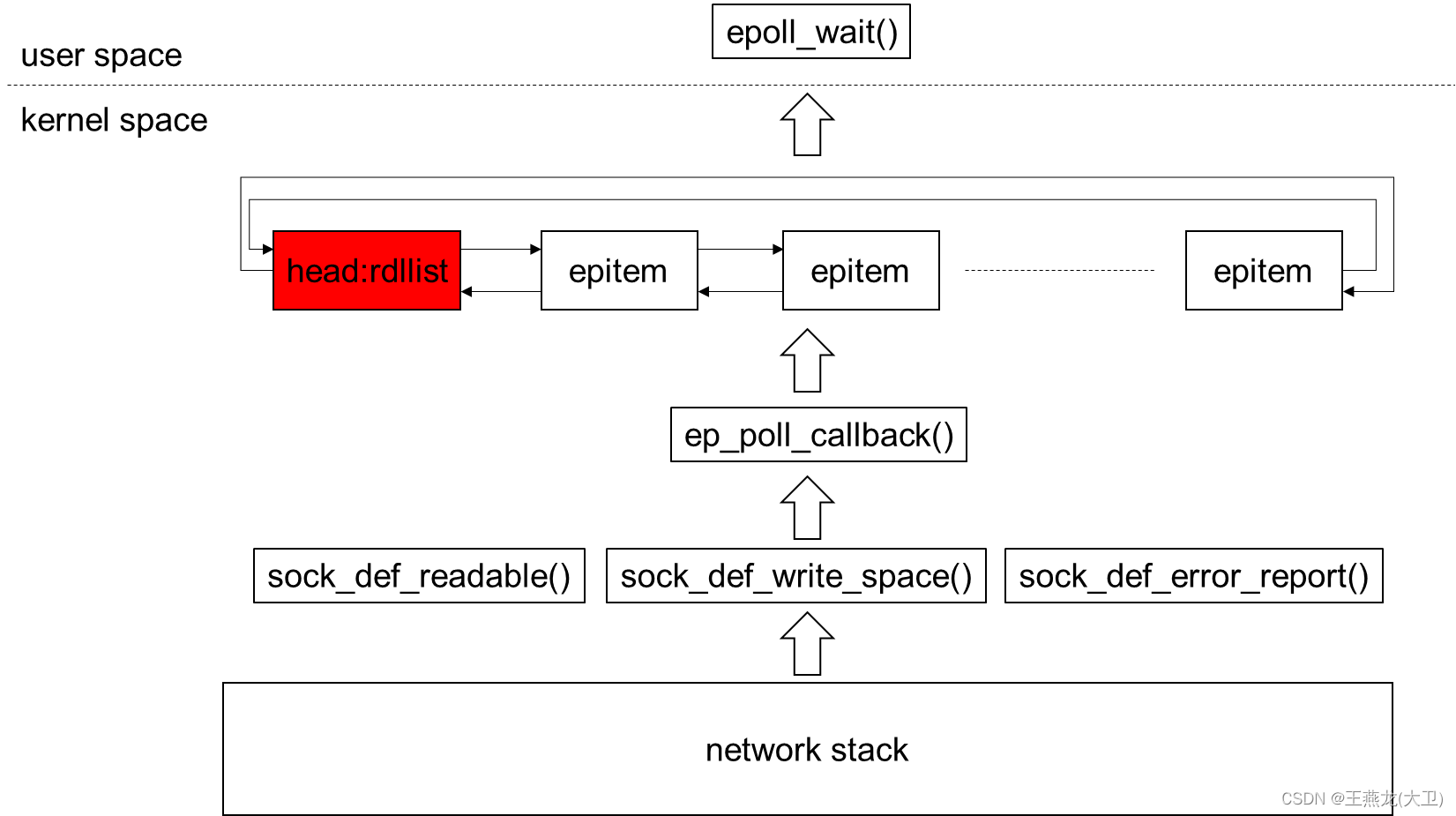
sock_def_readable(), sock_def_write_space(), sock_def_error_report() 这 3 个函数是协议栈向 sock 层通知事件的接口,分别是有可读,可写,错误。在创建 socket 的时候,都会调用函数 sock_init_data_uid(),在这个函数中完成了这几个函数的挂接。
void sock_init_data_uid(struct socket *sock, struct sock *sk, kuid_t uid)
{
...
sk->sk_state_change = sock_def_wakeup;
sk->sk_data_ready = sock_def_readable;
sk->sk_write_space = sock_def_write_space;
sk->sk_error_report = sock_def_error_report;
sk->sk_destruct = sock_def_destruct;
...
}(3) ovflist
从 ovflist 的注释可以看出来,如果当前正在向用户空间传递事件,那么这个时候底层协议栈上报的事件不会加入到 rdllist, 而是会加入到 ovflist 当中。
// ovflist 有两个取值, NULL 和 EP_UNACTIVE_PTR
// (1) EP_UNACTIVE_PTR:不需要将 epitem 放到 ovflist,
// UNACTIVE 即不活跃的
// 在函数 ep_done_scan() 中将 epitem 设置成 EP_UNACTIVE_PTR
// 调用 ep_done_scan() 的时候说明这次数据传输(从内核态向用户态)已经结束,可以将有事件的 epitem 放入 rdllist 中了
// (2) NULL: 需要将 epitem 放到 ovflist
// 在函数 ep_start_scan() 中将 ovflist 设置成 NULL,ep_start_scan() 和 ep_done_scan() 意思相反,
// 调用该函数时,即要开始进行数据传输了,这个时候需要将 epitem 放入 ovflist 当中
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{
/*
* If we are transferring events to userspace, we can hold no locks
* (because we're accessing user memory, and because of linux f_op->poll()
* semantics). All the events that happen during that period of time are
* chained in ep->ovflist and requeued later on.
*/
if (READ_ONCE(ep->ovflist) != EP_UNACTIVE_PTR) {
if (chain_epi_lockless(epi))
ep_pm_stay_awake_rcu(epi);
} else if (!ep_is_linked(epi)) {
/* In the usual case, add event to ready list. */
if (list_add_tail_lockless(&epi->rdllink, &ep->rdllist))
ep_pm_stay_awake_rcu(epi);
}
}每次 epoll_wait() 的时候,通过函数 ep_send_events() 来做事件的转移工作, 包括以下 3 步:
① 将事件从 rdllist 转移到局部变量 txlist 中
该函数将 rdllist 中的事件,通过指针操作,直接把事件转移到了 txlist 中,该函数返回之后,就会通过操作 txlist 将事件写入到用户空间的 event 数组当中, event 数组是用户调用 epoll_wait() 时传下来的数组;
同时将 ovflist 置 NULL,这样的话在 ep_poll_callback() 函数中就会把事件放到 ovflist 当中。
ep_start_scan(struct eventpoll *ep, struct list_head *txlist)
{
...
lockdep_assert_irqs_enabled();
write_lock_irq(&ep->lock);
list_splice_init(&ep->rdllist, txlist);
WRITE_ONCE(ep->ovflist, NULL);
write_unlock_irq(&ep->lock);
...
}② 将事件从 txlist 转移至用户的 event 数组
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
list_for_each_entry_safe(epi, tmp, &txlist, rdllink) {
events = epoll_put_uevent(revents, epi->event.data, events);
}
}③ 将 ovflist 中的事件转移到 rdllist, 这样下次查询事件的时候,就能从 rdllist 中将这些事件取出
static void ep_done_scan(struct eventpoll *ep,
struct list_head *txlist)
{
for (nepi = READ_ONCE(ep->ovflist); (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
if (!ep_is_linked(epi)) {
list_add(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
}
}(4) wq
注释说的很清楚,wq 表示一个等待队列,在 sys_poll_wait() 当中使用,
意思就是 epoll_wait() 的时候,如果当时没有事件,并且设置了等待时间没有超时或者设置成了阻塞模式,这个时候进程就会等待事件,在让出 cpu 之前,线程会将自己加入到等待队列里边,待有事件了会被唤醒。
/* Wait queue used by sys_epoll_wait() */
wait_queue_head_t wq;在 ep_poll_callback() 函数中,会将等待的线程唤醒,线程被唤醒之后就会去 rdllist 查找有没有事件,如果有的话,则将事件上报给用户空间并返回,否则会继续等待。
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{
if (waitqueue_active(&ep->wq)) {
wake_up(&ep->wq);
}
}(5)poll_wait
poll_wait 和上边的 wq 的数据结构是一样的,都是等待队列。当把 epoll fd 当成一个普通 fd 被监听时,poll_wait 这个成员才会使用(把 epoll fd 当成一个普通的 fd 被监听,后边 3.2 节会讨论)。
两者的区别如下:
① 服务的对象不同
wq 服务的对象是整个 epoll, 里边的元素代表一个线程,这个线程现在在睡眠,有事件上来之后会被唤醒,监听这个 epoll 的线程,都会加到这个队列里边,所以 wq 服务的是 epoll 这个对象。
poll_wait 服务的对象是一个 fd,比如一个 tcp socket,这样当该 socket 上边有事件的时候,会判断 poll_wait 有没有元素,如果有的话就进行唤醒。
② 唤醒函数不同
wq 是 autoremove_wake_function(), 这个函数里边会把 wq 中睡眠的线程唤醒。
#define init_wait(wait) \
do { \
(wait)->private = current; \
(wait)->func = autoremove_wake_function; \
INIT_LIST_HEAD(&(wait)->entry); \
(wait)->flags = 0; \
} while (0)poll_wait 的唤醒函数是 ep_poll_callback(), 这个函数里边不会做唤醒的工作,而是把事件加入到 rdllist 里边。
③ 移除时机不同
wq 中的睡眠线程,每一次被唤醒都会从 wq 中移除,下次睡眠的时候再次加入。
poll_wait 中的元素,每次有事件并不会从队列里边移除,而是会在 EPOLL_CTL_DEL 的时候进行移除。
wait_queue_head_t 队列中的元素是 struct wait_queue_entry 类型,结构提中有一个成员是 func,挂的是唤醒函数。wq 中的唤醒函数是 autoremove_wake_function, poll_wait 中的唤醒函数是 ep_poll_callback。
struct wait_queue_entry {
unsigned int flags;
void *private;
wait_queue_func_t func;
struct list_head entry;
};2.2 epitem
了解了 eventpoll 中的成员之后,epitem 就好理解了,eventpoll 代表整个 epoll,是一个容器,epitem 代表一个被监听的文件描述符,是一个元素。
epitem 中的 rbn 对应 eventpoll 中的 rbr, rdllink 对应 rdllist,next 对应 ovflist。
struct epitem {
union {
/* RB tree node links this structure to the eventpoll RB tree */
struct rb_node rbn;
/* Used to free the struct epitem */
struct rcu_head rcu;
};
/* List header used to link this structure to the eventpoll ready list */
struct list_head rdllink;
/*
* Works together "struct eventpoll"->ovflist in keeping the
* single linked chain of items.
*/
struct epitem *next;
/* The file descriptor information this item refers to */
struct epoll_filefd ffd;
/* List containing poll wait queues */
struct eppoll_entry *pwqlist;
/* The "container" of this item */
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
struct hlist_node fllink;
/* The structure that describe the interested events and the source fd */
struct epoll_event event;
};3 六个问题
3.1 epoll 回调函数是哪个,挂在了哪里,什么时候会调用
(1)回调函数是哪个 ?
ep_poll_callback()
另外, epoll 中还有一个函数 ep_ptable_queue_proc() 在这个函数中真正完成回调函数的挂载。
(2)挂在了哪里
对于 socket 来说,回调函数挂在了 socket 结构体的等待队列 wq 中。
struct socket {
struct socket_wq wq;
};ep_poll_callback() 的挂接是在 epoll 添加 fd 的时候完成的,下边记录一下回调挂接的过程:
① epoll_ctl() 调用 ep_insert() 完成监听 fd 的添加,具体的添加工作在 ep_insert() 中完成。
② ep_insert() 中调用函数 init_poll_funcptr(), 初始化 poll_table
poll_table 中的主要成员是 _qproc,在这个成员上挂了函数 ep_ptable_queue_proc(),在函数 ep_ptable_queue_proc() 中真正完成回调函数(ep_poll_callback)的挂接工作。
ep_insert():
初始化 pt, 然后调用 ep_item_poll(), 同时入参传递了 pt:
static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,
struct file *tfile, int fd, int full_check)
{
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc); // 初始化 pt
revents = ep_item_poll(epi, &epq.pt, 1);
}ep_item_poll():
调用 vfs_poll() 同时入参传递了 pt,对于 tcp socket 来说就是调用 tcp_poll():
static __poll_t ep_item_poll(const struct epitem *epi, poll_table *pt,
int depth)
{
res = vfs_poll(file, pt);
}tcp_poll():
调用 sock_poll_wait() 同时入参传递了 pt,在这里名字改成了 wait。
__poll_t tcp_poll(struct file *file, struct socket *sock, poll_table *wait)
{
sock_poll_wait(file, sock, wait);
}sock_poll_wait():
在该函数中取出了 socket 的等待队列,即 sock->wq.wait,然后调用 poll_wait(),同时传递了 pt,在这里名字改成了 p。
static inline void sock_poll_wait(struct file *filp, struct socket *sock,
poll_table *p)
{
if (!poll_does_not_wait(p)) {
poll_wait(filp, &sock->wq.wait, p);
smp_mb();
}
}poll_wait():
在这个函数里边,上边函数调用过程中一直传递的 pt 终于排上了用场,调用在 epoll 中注册的函数 ep_ptable_queue_proc() 来完成真正的 ep_poll_callback() 挂接的工作。
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);
}ep_ptable_queue_proc() :
可以看到在该函数中,封装了一个 pwq,里边就把 ep_poll_callback() 封装了进来,然后把这个元素添加到了等待队列里边。
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct ep_pqueue *epq = container_of(pt, struct ep_pqueue, pt);
struct epitem *epi = epq->epi;
struct eppoll_entry *pwq;
if (unlikely(!epi)) // an earlier allocation has failed
return;
pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL);
if (unlikely(!pwq)) {
epq->epi = NULL;
return;
}
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait);
else
add_wait_queue(whead, &pwq->wait);
pwq->next = epi->pwqlist;
epi->pwqlist = pwq;
}(3)什么时候会调用
回调的调用是在函数 sock_def_readable()、sock_def_write_space()、sock_def_error_report() 中发生的,这几个函数在 socket 初始化的时候,会挂到 sock 的函数指针上,当底层协议栈中有事件发生时就会调用对用的函数,向上层通知事件。
以读事件为例:
sock_def_readable():
在这个函数中首先取出 sock 的等待队列,然后调用 wake_up_interruptible_sync_poll() 唤醒等待队列里边的等待元素。
void sock_def_readable(struct sock *sk)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk->sk_wq);
if (skwq_has_sleeper(wq))
wake_up_interruptible_sync_poll(&wq->wait, EPOLLIN | EPOLLPRI |
EPOLLRDNORM | EPOLLRDBAND);
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
rcu_read_unlock();
}看到这里有个疑问,上边说的 epoll 的回调也是挂在了 socket 的等待队列中,挂到了 struct socket 这个结构体当中的 wq 中;这里要唤醒的等待队列却是 struct sock 中的 sk_wq,这两个不一样啊,怎么解释。
其实这两者指向的是一个队列,在 sock 初始化函数中做了关联。
void sock_init_data(struct socket *sock, struct sock *sk)
{
if (sock) {
sk->sk_type = sock->type;
RCU_INIT_POINTER(sk->sk_wq, &sock->wq); // 将 socket->wq 赋值给 sock->sk_wq
sock->sk = sk;
sk->sk_uid = SOCK_INODE(sock)->i_uid;
}
}__wake_up_common():
通过如下函数调用关系调用到 __wake_up_common()
__wake_up_sync_key() --> __wake_up_common_lock() --> __wake_up_common()
在该函数中就会取出等待队列中的元素并调用对应的 func 回调函数。对于 epoll 来说,回调函数就是 ep_poll_callback()。
static int __wake_up_common(struct wait_queue_head *wq_head, unsigned int mode,
int nr_exclusive, int wake_flags, void *key,
wait_queue_entry_t *bookmark)
{
list_for_each_entry_safe_from(curr, next, &wq_head->head, entry) {
ret = curr->func(curr, mode, wake_flags, key);
}
}epoll 和 socket 进行通信的方式就是通过 socket 中 wq 来进行。epoll 向 socket 的 wq 中添加了元素,当 socket 有事件的时候就会遍历 wq 中的元素,调用对应的函数,相当于向所有的监听方通知这个事件。类似于设计模式中的观察者模式。
linux 代表资源的这些对象,比如 socket,epoll,mutex,用户态使用的条件变量。当这些资源没有到来的时候,资源的消费者就需要等待,对应的就有一个等待队列;资源的生产者生产资源的时候,便会唤醒等待队列中的元素,唤醒的动作,往往是生产者注册的一个回调函数,具体的唤醒逻辑在回调函数中实现。
3.2 一个 epoll fd 可以当作一个普通的 fd 被另一个 epoll 监听吗
可以
这种使用方式,自己没见过具体的使用场景,但是 epoll 是支持这种用法的。
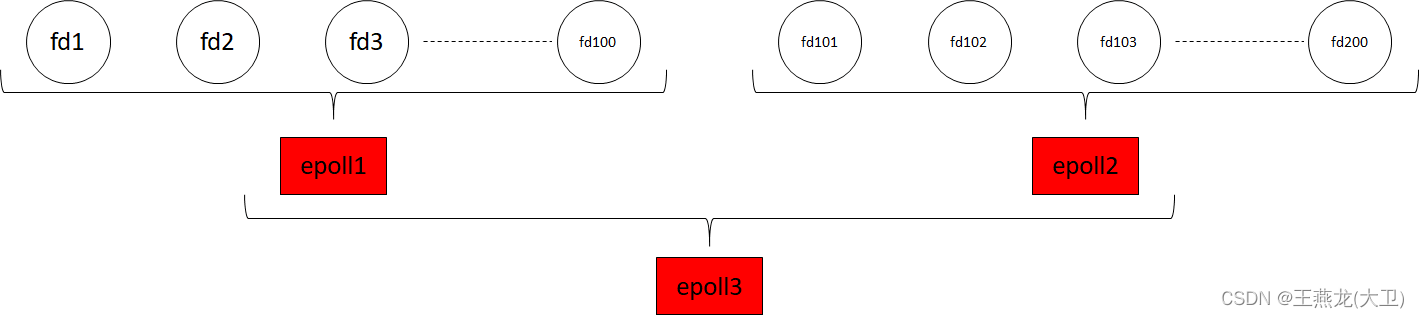
epoll 最常用的方式是监听普通的 socket fd,比如建立了 100 条 tcp 连接,然后把每个连接加入到 epoll 中,通过 epoll 进行监听,如下图所示。
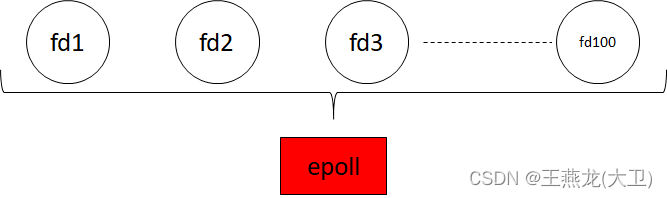
epoll 也是用一个 fd 来表示,epoll fd 也可以当做一个普通的 fd 加入到另外一个 epoll 里边进行监听。如下图所示,有 200 个 tcp 连接,其中第 1 到 100 个被 epoll1 监听,第 101 到 200 个被 epoll2 监听,然后 epoll1 和 epoll 2 再被 epoll 3 监听,这样用户只监听 epoll3 来同时监听 200 个连接。
当一个对象实现了 struct file_operations 中的 poll() 方法时,这个对象就可以加入到 epoll 中监听,否则无法使用 epoll 监听。如下是 epoll 实现的 struct_operations,其中实现了 poll 方法,所以 epoll 也可以当做一个普通 fd 被另一个 epoll 监听。
/* File callbacks that implement the eventpoll file behaviour */
static const struct file_operations eventpoll_fops = {
#ifdef CONFIG_PROC_FS
.show_fdinfo = ep_show_fdinfo,
#endif
.release = ep_eventpoll_release,
.poll = ep_eventpoll_poll,
.llseek = noop_llseek,
};
这种使用方式下,代码也需要分两级来进行:
event_num = epoll_wait(epoll3, events, MAX_EVENT, -1);
for (int i = 0; i < event_num; i++ ) {
if (events[i].data.fd == epoll1) {
epoll_wait(epoll1, events, MACX_EVENT, -1);
....
} else if (events[i].data.fd == epoll2) {
epoll_wait(epoll1, events, MACX_EVENT, -1);
....
}
}通过代码来理解:
(1) epoll1, epoll2 加入到 epoll3 和普通的 fd1 加入到 epoll1,代码上有什么区别
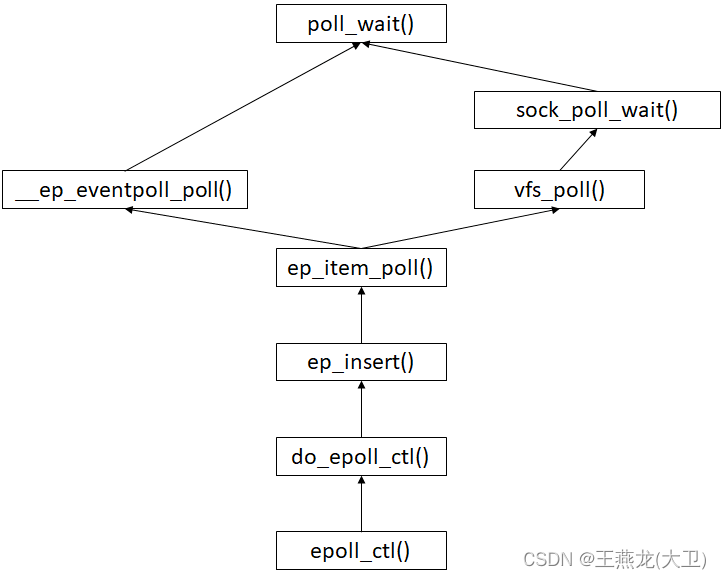
无论是普通的 fd 还是 epoll fd, 需要被 epoll 监听的时候,均是向这个 fd 的 poll_wait 队列入队一个元素,即注册回调函数 ep_poll_callback(),当描述符中有事件的时候,则会调用这个回调函数进行事件通知。
回调注册在 ep_item_poll() 函数中完成,普通 fd 通过 vfs_poll() 完成,epoll fd 通过 __ep_eventpoll_poll() 完成。
static __poll_t ep_item_poll(const struct epitem *epi, poll_table *pt,
int depth)
{
struct file *file = epi->ffd.file;
__poll_t res;
pt->_key = epi->event.events;
if (!is_file_epoll(file))
res = vfs_poll(file, pt);
else
res = __ep_eventpoll_poll(file, pt, depth);
return res & epi->event.events;
}
(2) 当 fd1 上有事件的时候,是怎么通知到 epoll3 的
epoll3 被通知到有事件,需要经过两步骤:
第一步:fd1 上有事件,通知 epoll1
调用栈如下所示,底层协议栈收到数据之后通过 ep_poll_callback() 通知 epoll
0xffffffff8b9281e0 : ep_poll_callback+0x0/0x2c0 [kernel]
0xffffffff8b7027fa : __wake_up_common+0x7a/0x190 [kernel]
0xffffffff8b70298c : __wake_up_common_lock+0x7c/0xc0 [kernel]
0xffffffff8bd1cf07 : sock_def_readable+0x37/0x60 [kernel]
0xffffffff8bdd7243 : tcp_data_queue+0x233/0xb60 [kernel]
0xffffffff8bdd7d90 : tcp_rcv_established+0x220/0x620 [kernel]
0xffffffff8bde3c8a : tcp_v4_do_rcv+0x12a/0x1e0 [kernel]
0xffffffff8bde5b2d : tcp_v4_rcv+0xb3d/0xc40 [kernel]
0xffffffff8bdbafc9 : ip_local_deliver_finish+0x69/0x210 [kernel]
0xffffffff8bdbb2eb : ip_local_deliver+0x6b/0xe0 [kernel]
0xffffffff8bdbb5db : ip_rcv+0x27b/0x36a [kernel]
0xffffffff8bd3ebe1 : __netif_receive_skb_core+0xb41/0xc40 [kernel]
0xffffffff8bd3ed7d : netif_receive_skb_internal+0x3d/0xb0 [kernel]
0xffffffff8bd3f67a : napi_gro_receive+0xba/0xe0 [kernel]
第二步:epoll1 上有事件,通知 epoll3
这个通知在 ep_poll_callback 中发起,由上文可知,epoll1 加入到 epoll3 的时候,epoll3 在 epoll1 的 poll_wait 中入队了一个元素,所以这个时候,发现 epoll1 的 poll_wait 有元素,则通过 ep_poll_safe_wake() 调用 epoll3 的回调,同样最终会调到 ep_poll_callback() 将事件挂到 epoll 的就绪队列中,这样 epoll3 就能监听到事件了。
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{
...
if (waitqueue_active(&ep->poll_wait))
pwake++;
...
if (pwake)
ep_poll_safewake(ep, epi);
...
}(3) 深度限制
由上边的分析,可以知道,当一个 epoll 被另外一个 epoll 监听的时候,事件上报路径会增加一级。epoll 中在向 epoll 添加需要被监听的描述符时,会对事件上报路径深度进行检查,如果检查不通过,则会添加失败。
引起上报深度过长的情况由两种:
① 循环路径,epoll1 监听 epoll2, 同时 epoll2 监听 epoll1
② 路径过长,如下边右边这张图,epoll1 被 epoll2 监听,epoll2 被 epoll3 监听 ...,epoll5 被 epoll6 监听。

代码验证:
如下代码能验证以上两种情况,将 注释 1 和 注释 2 同时打开,能验证循环监听的情况; 将 注释 1 打开,注释 2 不打开,能验证监听路径太长的情况。
#include <stdio.h>
#include <string.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/socket.h>
#include <sys/epoll.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <fcntl.h>
#include <errno.h>
#define SERVER_IP ("0.0.0.0")
#define SERVER_PORT (12345)
#define MAX_LISTENQ (32)
#define MAX_EVENT (128)
int create_tcp_server() {
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (listen_fd < 0) {
printf("create socket error: %s\n", strerror(errno));
return -1;
}
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = inet_addr(SERVER_IP); /**< 0.0.0.0 all local ip */
server_addr.sin_port = htons(SERVER_PORT);
if (bind(listen_fd,(struct sockaddr *)&server_addr, sizeof(server_addr)) < 0) {
printf("bind[%s:%d] error.\n", SERVER_IP, SERVER_PORT);
return -1;
}
if (listen(listen_fd, MAX_LISTENQ) < 0) {
printf("listen error.\n");
return -1;
}
return listen_fd;
}
int main() {
int ret = -1;
int sock_fd = -1;
int accetp_fd = -1;
int event_num = -1;
int fd1 = -1;
struct sockaddr_in client_addr;
struct sockaddr_in server_addr;
socklen_t client = sizeof(struct sockaddr_in);
struct epoll_event ev;
struct epoll_event events[MAX_EVENT];
fd1 = create_tcp_server();
if (fd1 < 0) {
printf("create server error\n");
return -1;
}
int epoll1 = epoll_create(MAX_EVENT);
if (epoll1 <= 0) {
printf("cteare epoll1 failed, error: %s\n", strerror(errno));
return -1;
}
int epoll2 = epoll_create(MAX_EVENT);
if (epoll2 <= 0) {
printf("cteare epoll2 failed, error: %s\n", strerror(errno));
return -1;
}
int epoll3 = epoll_create(MAX_EVENT);
if (epoll3 <= 0) {
printf("cteare epoll3 failed, error: %s\n", strerror(errno));
return -1;
}
int epoll4 = epoll_create(MAX_EVENT);
if (epoll4 <= 0) {
printf("cteare epoll4 failed, error: %s\n", strerror(errno));
return -1;
}
int epoll5 = epoll_create(MAX_EVENT);
if (epoll5 <= 0) {
printf("cteare epoll5 failed, error: %s\n", strerror(errno));
return -1;
}
int epoll6 = epoll_create(MAX_EVENT);
if (epoll6 <= 0) {
printf("cteare epoll6 failed, error: %s\n", strerror(errno));
return -1;
}
ev.data.fd = fd1;
ev.events = EPOLLIN;
if (epoll_ctl(epoll1, EPOLL_CTL_ADD, fd1, &ev) < 0) {
printf("add fd1 to epoll1 error: %s\n", strerror(errno));
return -1;
}
// 注释 1
/*
ev.data.fd = epoll1;
ev.events = EPOLLIN;
if (epoll_ctl(epoll2, EPOLL_CTL_ADD, epoll1, &ev) < 0) {
printf("add epoll1 to epoll2 error: %s\n", strerror(errno));
return -1;
}
*/
// 注释 2
/*
ev.data.fd = epoll2;
ev.events = EPOLLIN;
if (epoll_ctl(epoll1, EPOLL_CTL_ADD, epoll2, &ev) < 0) {
printf("add epoll2 to epoll1 error: %s\n", strerror(errno));
return -1;
}
*/
ev.data.fd = epoll2;
ev.events = EPOLLIN;
if (epoll_ctl(epoll3, EPOLL_CTL_ADD, epoll2, &ev) < 0) {
printf("add epoll2 to epoll3 error: %s\n", strerror(errno));
return -1;
}
ev.data.fd = epoll3;
ev.events = EPOLLIN;
if (epoll_ctl(epoll4, EPOLL_CTL_ADD, epoll3, &ev) < 0) {
printf("add epoll3 to epoll4 error: %s\n", strerror(errno));
return -1;
}
ev.data.fd = epoll4;
ev.events = EPOLLIN;
if (epoll_ctl(epoll5, EPOLL_CTL_ADD, epoll4, &ev) < 0) {
printf("add epoll4 to epoll5 error: %s\n", strerror(errno));
return -1;
}
ev.data.fd = epoll5;
ev.events = EPOLLIN;
if (ret = epoll_ctl(epoll6, EPOLL_CTL_ADD, epoll5, &ev) < 0) {
printf("add epoll5 to epoll6 error: %s, ret: %d, epoll5: %d, epoll6: %d\n", strerror(errno), ret, epoll5, epoll6);
return -1;
}
return 0;
}循环路径报错信息以及代码位置:

int do_epoll_ctl(int epfd, int op, int fd, struct epoll_event *epds,
bool nonblock)
{
error = epoll_mutex_lock(&ep->mtx, 0, nonblock);
if (error)
goto error_tgt_fput;
if (op == EPOLL_CTL_ADD) {
if (READ_ONCE(f.file->f_ep) || ep->gen == loop_check_gen ||
is_file_epoll(tf.file)) {
mutex_unlock(&ep->mtx);
error = epoll_mutex_lock(&epmutex, 0, nonblock);
if (error)
goto error_tgt_fput;
loop_check_gen++;
full_check = 1;
if (is_file_epoll(tf.file)) {
tep = tf.file->private_data;
error = -ELOOP; // 循环路径报错
if (ep_loop_check(ep, tep) != 0)
goto error_tgt_fput;
}
error = epoll_mutex_lock(&ep->mtx, 0, nonblock);
if (error)
goto error_tgt_fput;
}
}
return error;
}路径太长报错信息及报错位置:

static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,
struct file *tfile, int fd, int full_check)
{
/* now check if we've created too many backpaths */
if (unlikely(full_check && reverse_path_check())) {
ep_remove(ep, epi);
return -EINVAL;
}
return 0;
}3.3 水平触发和边沿触发的区别
通俗来讲,水平触发,只要有数据,epoll_wait() 就会一直返回;边沿触发,如果数据没处理完,并且这个 fd 没有新的事件,那么再次 epoll_wait() 的时候也不会有事件上来。
水平触发还是边沿触发,影响的是接收事件的行为。
(1)举个例子
假如一个 tcp socket 一次收到了 1MByte 的数据,但是 epoll_wait() 返回之后,用户一次只读取 1KB 的数据,读完之后再进行 epoll_wait() 监听事件,示例代码如下所示:
for (;;) {
event_num = epoll_wait(epoll_fd, events, 1, -1);
ret = recv(tcp_fd, buff, 1024, 0);
if (ret <= 0) {
break;
}
}如果是水平触发,那么每次 epoll_wait() 都能返回这个 tcp_fd 的事件,共返回 (1MB / 1KB)= 1024 次事件;如果是边沿触发,那么只有第一次返回了 tcp_fd 的事件,后边的 epoll_wait() 也不返回了。
(2)代码
从代码实现来理解边沿触发和水平触发之间的区别。
用户在调用 epoll_wait() 之后,如果有事件,最终会调用 ep_send_events() 来做事件的转移,
主要工作是将事件从 rdllist 中转移到用户的 events 数组。
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
ep_start_scan(ep, &txlist);
list_for_each_entry_safe(epi, tmp, &txlist, rdllink)
revents = ep_item_poll(epi, &pt, 1);
if (!revents)
continue;
events = epoll_put_uevent(revents, epi->event.data, events);
}
res++;
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS;
else if (!(epi->event.events & EPOLLET)) { // 如果不是边沿触发,则将 epitem 重新加回就绪链表
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
return res;
}对于从 rdllist 中获取的 epitem,首先调用 ep_item_poll() 确定有没有事件,以及事件的具体类型,如果有事件则件通过 epoll_put_uevent() 将事件保存存到用户的 event 数组中。
之后会判断是否为边沿触发,如果不是边沿触发,即水平触发,还会把这个 epitem 加入到 rdllist 的尾部,这样下次 epoll_wait() 的时候还会 poll 这个 fd,还会对这个 fd 进行 poll 操作,如果有事件还会向用户返回。
以上边举的例子来看,第 1 到 1024 次调用 epoll_wait() 都会返回事件,第 1025 次调用 epoll_wait() 的时候,由于数据都已经读取完毕,所以通过 ep_item_poll() 发现没有事件,这次当然也不会向用户返回事件,同时也不会把 epitem 返回 rdllist 了。
(3)实验
server:
#include <stdio.h>
#include <string.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/socket.h>
#include <sys/epoll.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <fcntl.h>
#include <errno.h>
#define SERVER_IP ("0.0.0.0")
#define SERVER_PORT (12345)
#define MAX_LISTENQ (32)
#define MAX_EVENT (128)
int create_tcp_server() {
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (listen_fd < 0) {
printf("create socket error: %s\n", strerror(errno));
return -1;
}
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = inet_addr(SERVER_IP); /**< 0.0.0.0 all local ip */
server_addr.sin_port = htons(SERVER_PORT);
if (bind(listen_fd,(struct sockaddr *)&server_addr, sizeof(server_addr)) < 0) {
printf("bind[%s:%d] error.\n", SERVER_IP, SERVER_PORT);
return -1;
}
if (listen(listen_fd, MAX_LISTENQ) < 0) {
printf("listen error.\n");
return -1;
}
return listen_fd;
}
int main() {
int ret = -1;
int sock_fd = -1;
int accetp_fd = -1;
int event_num = -1;
int epoll_fd = -1;
int listen_fd = -1;
struct sockaddr_in client_addr;
struct sockaddr_in server_addr;
socklen_t client = sizeof(struct sockaddr_in);
struct epoll_event ev;
struct epoll_event events[MAX_EVENT];
listen_fd = create_tcp_server();
if (listen_fd < 0) {
printf("create server error\n");
return -1;
}
epoll_fd = epoll_create(MAX_EVENT);
if (epoll_fd <= 0) {
printf("cteare epoll failed, error: %s\n", strerror(errno));
return -1;
}
ev.data.fd = listen_fd;
ev.events = EPOLLIN;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &ev) < 0) {
printf("add listen fd to epoll error.\n");
return -1;
}
char buff[1024] = {'\0'};
int seq = 0;
for (;;) {
printf("epoll wait:\n");
event_num = epoll_wait(epoll_fd, events, MAX_EVENT, -1);
printf("events num:%d\n", event_num);
for (int i = 0; i < event_num; i++ ) {
if (events[i].events & EPOLLIN == 0) {
/* 只监听 EPOLLIN 事件 */
printf("fd %d error, cloase it, event[0x%x].\n", events[i].data.fd, events[i].events);
close(events[i].data.fd);
return -1;
}
if (events[i].data.fd == listen_fd) {
accetp_fd = accept(listen_fd, (struct sockaddr*)&client_addr, &client);
if(accetp_fd < 0) {
printf("accept error.\n");
return -1;
}
ev.data.fd = accetp_fd;
ev.events = EPOLLIN; // 水平触发,默认触发方式
// ev.events = EPOLLIN | EPOLLET; // 边沿触发,需要通过标记 EPOLLET 来指定
if(epoll_ctl(epoll_fd, EPOLL_CTL_ADD, accetp_fd, &ev) < 0) {
printf("add fd to epoll error.\n");
return -1;
}
sleep(2); // 之所以等 2 秒,是为了让客户端发送 1M 的数据发送完毕
} else {
ret = recv(accetp_fd, buff, 1024, 0);
if (ret <= 0) {
printf("recv error.\n");
epoll_ctl(epoll_fd, EPOLL_CTL_DEL, accetp_fd, &ev);
close(accetp_fd);
events[i].data.fd = -1;
return -1;
}
printf("seq: %d, recv len: %d\n", seq, ret);
seq++;
}
}
}
close(listen_fd);
}client:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <errno.h>
#include <fcntl.h>
#include <sys/epoll.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <unistd.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#define SERVER_PORT (12345)
#define SERVER_IP "127.0.0.1"
#define MAX_EVENT (128)
#define MAX_BUFSIZE (512)
int main(int argc,char *argv[]) {
int sock_fd;
sock_fd = socket(AF_INET, SOCK_STREAM, 0);
if(sock_fd < 0) {
printf("create socket error.\n");
return -1;
}
struct sockaddr_in addr_serv;
memset(&addr_serv, 0, sizeof(addr_serv));
addr_serv.sin_family = AF_INET;
addr_serv.sin_port = htons(SERVER_PORT);
addr_serv.sin_addr.s_addr = inet_addr(SERVER_IP);
if(connect(sock_fd, (struct sockaddr *)&addr_serv,sizeof(struct sockaddr)) < 0){
printf("connect error.\n");
return -1;
}
char send_buff[1024 * 1024] = "epoll test!";
int send_total_count = 0;
int send_tmp_count = 0;
while (send_total_count < 1024 * 1024) {
send_tmp_count = send(sock_fd, send_buff, 1024 * 1024, 0);
send_total_count += send_tmp_count;
}
printf("send 1MB success\n");
close(sock_fd);
return 0;
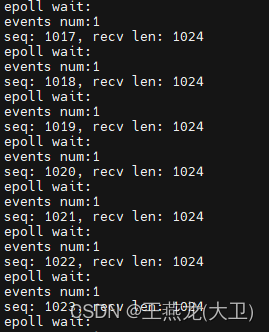
}水平触发测试结果:
计数从 0 开始,到 1023 结束,共接收 1024 次数据,共 1MB
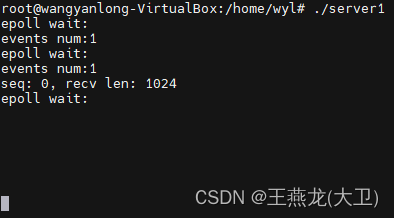
边沿触发测试结果:
第一次接受 1024 的数据之后,后边 epoll_wait() 不会返回事件
3.4 epoll 惊群问题是怎么回事
(1)现象
在 linux 网络方面讨论惊群问题的时候,通常有两个惊群问题,分别是 accept 惊群问题和 epoll 惊群问题。如果多个进程阻塞到同一个 fd 上,当这个 fd 有事件的时候,多个进程会被唤醒,但是只有一个进程获得并处理该事件,导致其它进程空转,进而导致 cpu 资源的浪费。这就是惊群问题。
如果你见过养鸡的,那么很好理解惊群问题。假设养了一群鸡,这个时候你要喂鸡,鸡群看到你来了,都跑了过来,但是这个时候,你手中只有一粒玉米,你往空中一抛,所有的鸡都跳了起来,但是只有一只鸡能吃到这粒玉米,其它集白跳了一次,这就是惊群问题。

从 2.6 开始,linux 内核已经解决了 accept 惊群问题, 具体的解决方式就是给等待队列中的元素增加一个 EXCLUSIVE(排他)标记。
![]()
当多个进程阻塞在同一个 listening fd 上时,进程就会被加入到这个 fd 的等待队列中,当 fd 中有事件到来的时候,就会唤醒等待队列中的进程。当没有 EXCLUSIVE 标记的时候,等待队列中的元素全部会被唤醒。
后来给等待元素增加了 EXCLUSIVE 标记,并且带此标记的进程会加到等待队列的尾部。唤醒的时候,从队列头开始唤醒,没有 EXCLUSIVE 标记的进程都会被唤醒,有这个标记的进程只唤醒一个,这样就保证了 EXCLUSIVE 的进程只唤醒一个。
当用户调用 accept(),在内核态会调用到 inet_csk_accept(),如果当前没有新的连接到来,那么就会调用 inet_csk_wait_for_connet(), 进而调用到 prepare_to_wait_exclusive(),从这个函数的名字来看,就是排他性的。所以 accept() 通过 EXCLUSIVE 标志解决了惊群问题。
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern)
{
if (reqsk_queue_empty(queue)) {
error = inet_csk_wait_for_connect(sk, timeo);
if (error)
goto out_err;
}
}
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
for (;;) {
prepare_to_wait_exclusive(sk_sleep(sk), &wait,
TASK_INTERRUPTIBLE);
}
}(2)原因
由上边分析可知,解决 accept() 惊群问题就是在把进程加入到等待队列时,增加了 EXCLUSIVE 标志,并且唤醒的时候,对于有该标志的进程只唤醒一个。
而在 epoll_wait() 的内核实现中,当没有事件需要等待的时候,也需要把进程加入到等待队列中,加入到等待队列中的时候,也加了 EXCLUSIVE 标志,为什么这种方式下 epoll 仍然有惊群问题呢 ?
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, struct timespec64 *timeout)
{
while (1) {
if (!eavail)
__add_wait_queue_exclusive(&ep->wq, &wait);
}
}
}可以说,通过 EXCLUSIVE 标志,内核在一定程度上解决了 epoll 惊群问题,但是没有完全解决。
先通过一个例子看一下 epoll 惊群的现象,然后再结合代码分析产生这种现象的原因:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <netdb.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/epoll.h>
#include <sys/wait.h>
#include <errno.h>
#define SERVER_IP ("0.0.0.0")
#define SERVER_PORT (12345)
#define MAX_LISTENQ (32)
#define MAX_EVENT (128)
#define PROCESS_NUM (10)
int set_fd_nonblocking(int fd){
int val = fcntl(fd, F_GETFL);
val |= O_NONBLOCK;
if(fcntl(fd, F_SETFL, val) < 0){
return -1;
}
return 0;
}
int set_tcp_server_reuse(int fd) {
int so_reuse = 1;
if (setsockopt(fd, SOL_SOCKET, SO_REUSEADDR, &so_reuse, sizeof(so_reuse)) < 0) {
printf("fd[%d] set SO_REUSEADDR error[%s]", fd, strerror(errno));
return -1;
}
return 0;
}
int create_tcp_server() {
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (listen_fd < 0) {
printf("create socket error: %s\n", strerror(errno));
return -1;
}
set_tcp_server_reuse(listen_fd);
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = inet_addr(SERVER_IP); /**< 0.0.0.0 all local ip */
server_addr.sin_port = htons(SERVER_PORT);
if (bind(listen_fd,(struct sockaddr *)&server_addr, sizeof(server_addr)) < 0) {
printf("bind[%s:%d] error: %s.\n", SERVER_IP, SERVER_PORT, strerror(errno));
return -1;
}
if (listen(listen_fd, MAX_LISTENQ) < 0) {
printf("listen error.\n");
return -1;
}
return listen_fd;
}
int main() {
int ret = -1;
int accept_fd = -1;
int event_num = -1;
int epoll_fd = -1;
int listen_fd = -1;
struct sockaddr_in client_addr;
struct sockaddr_in server_addr;
socklen_t client = sizeof(struct sockaddr_in);
struct epoll_event ev;
struct epoll_event events[MAX_EVENT];
listen_fd = create_tcp_server();
if (listen_fd < 0) {
printf("create server error\n");
return -1;
}
set_fd_nonblocking(listen_fd);
epoll_fd = epoll_create(MAX_EVENT);
if (epoll_fd <= 0) {
printf("cteare epoll failed, error: %s\n", strerror(errno));
return -1;
}
ev.data.fd = listen_fd;
ev.events = EPOLLIN;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &ev) < 0) {
printf("add listen fd to epoll error.\n");
return -1;
}
for(int i = 0; i < PROCESS_NUM; i++){
int pid = fork();
if(pid == 0){
while(1){
int event_num = 0;
event_num = epoll_wait(epoll_fd, events, MAX_EVENT, -1);
printf("process %d return from epoll_wait, event num: %d\n", getpid(), event_num);
sleep(1);
for(i = 0; i < event_num; i++){
if(!(events[i].events & EPOLLIN)){
printf("epoll error\n");
return -1;
}else if(listen_fd == events[i].data.fd){
struct sockaddr in_addr;
socklen_t in_len = sizeof(in_addr);
accept_fd = accept(listen_fd, &in_addr, &in_len);
printf("process %d accept fd %d\n", getpid(), accept_fd);
if(accept_fd <= 0){
printf("process %d accept failed!\n", getpid());
}else{
printf("process %d accept successful!\n", getpid());
}
}
}
}
}
}
wait(0);
return 0;
}代码解释:
上述代码,首先在主进程中创建一个 epoll fd, 并加入一个 tcp listening fd,然后创建 10 个子进程,这 10 个子进程均对主进程创建的 epoll fd 进行 epoll wait。
设置 socket 选项 SO_REUSEADDR 是为了避免在测试过程中出现 “Address already in use.” 错误。
将 fd 设置为非阻塞,是为了在没有新连接的时候也让 accept() 返回,防止其中一个进程将新连接接收之后,其它进程一直阻塞在 accept() 系统调用,看不到后边的接收成功与否的打印。
测试过程:
上述代码编译之后,在一个终端启动,在另外一个终端通过 telnet 链接监听的端口,telnet 127.0.0.1 12345。
测试现象:
基于上边代码和测试步骤,做三个不同的实验,这三个实验呈现不同的现象。
这三个实验的区别有两方面,分别是监听 fd 是水平触发还是边沿触发, epoll_wait() 返回之后要不要 sleep()。
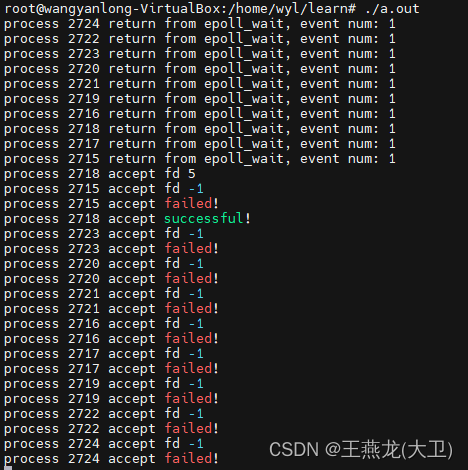
实验 一:水平触发 + epoll_wait() 返回之后 sleep()
10 个进程都被唤醒,其中一个进程接收了新连接。出现了惊群现象。
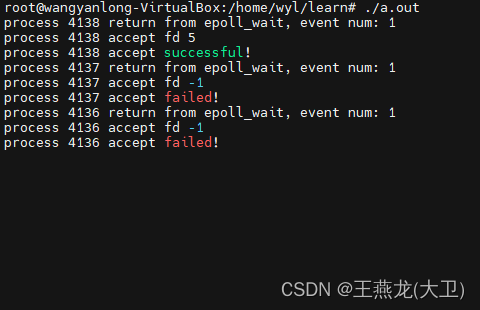
实验 二:水平触发 + epoll_wait() 返回之后不进行 sleep()
被唤醒进程的个数不确定, 范围在 [1, 10] 之间,其中一个进程接收了新连接。出现了惊群现象,但是没有实验 一那么严重。
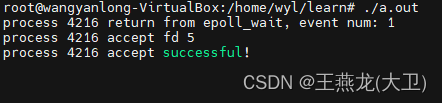
实验 三:边沿触发 + epoll_wait() 返回之后 sleep()
只有一个进程被唤醒,该进程接收了新链接。没有出现惊群现象。
下边通过分析源码,来解释上边三个现象:
在 epoll_wait() 函数中,如果有事件,那么就会唤醒等待进程。进程会调用函数 ep_send_events() 将事件从就绪链表转移到用户态的 event 数组。该函数最后调用了 ep_done_scan(),这个函数最后判断了就绪队列是不是空,如果非空的话,会继续唤醒等待队列中的进程。唤醒一个等待进程之后,当前这个进程就会返回用户态。
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
ep_done_scan(ep, &txlist);
}
static void ep_done_scan(struct eventpoll *ep,
struct list_head *txlist)
{
if (!list_empty(&ep->rdllist)) {
if (waitqueue_active(&ep->wq))
wake_up(&ep->wq);
}
write_unlock_irq(&ep->lock);
}而后边被唤醒的进程,当被执行的时候,有两种情况:
① 事件已经被之前被唤醒的进程处理,那么该进程检查没有事件,继续睡眠等待,不会返回用户态;
② 事件还没有被处理,那么该进程的工作流程和第一个被唤醒的进程相同,会返回用户态。
根据上边两种情况可以解释实验一和实验二的区别,实验一,在 epoll_wait() 返回之后进行 sleep(),就是为了不让返回的进程立即处理事件,这样就会导致所有的进程都被唤醒,返回用户态;实验二,epoll_wait() 返回之后会立即处理事件,这就和操作系统调度的快慢有关系了,被唤醒的进程个数是不确定的。
当就绪链表中有事件的时候,就会继续唤醒进程,如果是边沿触发的话,也不会惊群了,因为一次之后这个就不会加回就绪链表了。
实验一和实验三之间的区别就是水平触发和边沿触发的区别,因为水平触发的话,事件转移到用户态之后,还会加回就绪队列,这样导致就绪队列不为空,进而导致会继续唤醒进程;而边沿触发不会把事件加回就绪队列,这就绪队列为空,所以不会继续唤醒进程
(3)epoll 惊群如何规避
从上边的分析来看,linux 内核完全解决了 accept() 的惊群问题,因为对于 accept() 来说,一个连接事件是原子的,不能拆分的,只能被一个进程处理,所以内核这么实现是没有问题的,也不会引起用户的异议。
但是 epoll 就不一样,因为 epoll 除了能监听连接事件以外还可以监听接收,发送等事件。就拿接收事件来说,用户可能希望一次接收的数据用多个进程或线程来处理,如果内核强制成只唤醒一个进程,那么就满足不了用户的需求了。
所以说 epoll 惊群,严格意义上来说,并不是问题,而是将最终的决策权交给了用户。
3.5 为什么当发送返回失败时才需要监听 EPOLLOUT 事件
(1)接收数据和发送数据的区别: 一个被动,一个主动
使用一个连接(tcp socket) 无非就是做两件事情,接收数据和发送数据,
对于接收数据来说,接收方是被动的,只有对端的数据到达本端之后,才会产生 EPOLLIN 事件,之后进行实际数据的接收才是有意义的;
而对于发送来说,发送端是主动的,不是被动的,也就是说只要发送缓冲区有充足的空间,那么发送端就可以发送数据,而不需要有 EPOLLOUT 事件才能发送数据。
所以对于发送数据来说,并不需要一开始就监听 EPOLLOUT 事件,只需要等到这次发送失败(实际发送的数据长度小于要发送的数据长度), 才需要监听发送事件。而一旦 EPOLLOUT 事件上来之后,就需要清除这个事件,不需要一直监听,否则的话每次 epoll wait,只要发送侧有缓冲区可用,都会返回可写事件。
(2)tcp 上报 EPOLLOUT 事件的判断条件
static inline bool __sk_stream_is_writeable(const struct sock *sk, int wake)
{
// 条件1:剩余空间大于发送缓冲区最大值的 1/3
// 条件2:沒有发送出去的要小于 lowwat 的临界值
return sk_stream_wspace(sk) >= sk_stream_min_wspace(sk) &&
__sk_stream_memory_free(sk, wake);
}3.6 epoll 相对于 select, poll 有什么区别
(1)epoll 在内核态和用户态,只需要遍历有事件的 fd,不用全部遍历
这个是 epoll 和 select, poll 最明显的别,也是 epoll 最明显的优势。
假如要监听 500 个 fd,而现在只有 10 个 fd 有事件,对于 select 和 poll 来说,当调用 select(), poll() 之后,内核需要把 500 个 fd 遍历一遍,然后返回,返回之后,用户处理事件的时候,仍然要把所有 fd 都遍历一遍,同时处理有事件的 fd。
对于 epoll 来说,当调用 epoll_wait() 之后,在内核态只需要遍历 10 个文件描述符,返回之后,在用户态也只需要处理 10 个事件即可,不需要遍历全部的 500 个描述符。
![]()
由此可见,select 和 poll 适用于 fd 个数比较少,或者 fd 个数比较多并且大多数 fd 都比较活跃的场景;而 epoll 适用于 fd 个数比较多,但是活跃 fd 占比不大的场景。
(2)监听的文件个数限制
① select 只能监听 1024 个文件描述符(0 ~ 1023)
select 能监听的 fd 的个数是有限制的,1024 个,并且这 1024 个 fd 的范围也是有限制的,只能是 0~ 1023, 假如你创建了一个 fd 是 2000, 但是被 select 监听的 fd 只有 10 个(没有超过数量限制),那么这个 2000 的 fd 也是不能被 select 监听。因为 fd_set 在内核是一个 bitmap, 用 bitmap 的位来表示一个 fd,所以能表示的 fd 的范围就是 0 ~ 1023。
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
#define __FD_SETSIZE 1024
typedef struct {
unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set;② poll 和 epoll 本身没有对文件按描述符个数的限制。
(3)目标事件和实际事件分离
① select 目标事件和实际事件没有分离
select 每次调用之前,都需要将自己要监听的读事件,写事件,错误事件分别设置到对应的 fd_set 中,内核处理的时候,如果要监听的事件,当前没有,就会把对应位置清除,返回给用户态。所以对于 select 来说,用户要监听的事件,以及用户返回的事件,都放到 fd_set 里边,共用这块数据空间。这就导致每次调用 select 时,都需要重新设置一边 fd_set。
② poll 和 epoll 实现了分离
poll 使用一个结构体 strucy poll_fd 来表示一个 被监听的 fd,并且目标事件和实际事件通过 events 和 reevents 来表示,这样对于用户来说不需要每次调用 poll() 之前都设置一遍目标事件。
struct pollfd {
int fd;
short int events;
short int revents;
};epoll 通过一个专门的 api epoll_ctl 来管理要监听的目标事件,epoll_wait() 的时候直接获取数据事件。
(4)系统调用个数的区别
select 和 poll 均是只有一个 系统调用,这样使用简单,但是每次都要传递要监听的 fd 以及监听的目标事件,导致在用户态和内核态传递的数据量较大;
epoll 通过三个 api 来实现,epoll_create(), epoll_ctl(), epoll_wait()。epoll 本身也占用一个 fd 资源,select,poll 不存在这种情况,但是 epoll 通过这种方式,将控制面和数据面完全分离,要监听哪些 fd,以及每个 fd 要监听的目标事件,完全在内核进行管理,这就减少了 epoll_wait() 时在用户态和内核态传输的数据量。















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









